 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructing LLMs to Negotiate using Reinforcement Learning with Verifiable Rewards
Apr 10, 2026The recent advancement of Large Language Models (LLMs) has established their potential as autonomous interactive agents. However, they often struggle in strategic games of incomplete information, such as bilateral price negotiation. In this paper, we investigate if Reinforcement Learning from Verifiable Rewards (RLVR) can effectively teach LLMs to negotiate. Specifically, we explore the strategic behaviors that emerge during the learning process. We introduce a framework that trains a mid-sized buyer agent against a regulated LLM seller across a wide distribution of real-world products. By grounding reward signals directly in the maximization of economic surplus and strict adherence to private budget constraints, we reveal a novel four-phase strategic evolution. The agent progresses from naive bargaining to using aggressive starting prices, moves through a phase of deadlock, and ultimately develops sophisticated persuasive skills. Our results demonstrate that this verifiable training allows a 30B agent to significantly outperform frontier models over ten times its size in extracting surplus. Furthermore, the trained agent generalizes robustly to stronger counterparties unseen during training and remains effective even when facing hostile, adversarial seller personas.
Beyond Pessimism: Offline Learning in KL-regularized Games
Apr 08, 2026We study offline learning in KL-regularized two-player zero-sum games, where policies are optimized under a KL constraint to a fixed reference policy. Prior work relies on pessimistic value estimation to handle distribution shift, yielding only $\widetilde{\mathcal{O}}(1/\sqrt n)$ statistical rates. We develop a new pessimism-free algorithm and analytical framework for KL-regularized games, built on the smoothness of KL-regularized best responses and a stability property of the Nash equilibrium induced by skew symmetry. This yields the first $\widetilde{\mathcal{O}}(1/n)$ sample complexity bound for offline learning in KL-regularized zero-sum games, achieved entirely without pessimism. We further propose an efficient self-play policy optimization algorithm and prove that, with a number of iterations linear in the sample size, it achieves the same fast $\widetilde{\mathcal{O}}(1/n)$ statistical rate as the minimax estimator.
MathlibLemma: Folklore Lemma Generation and Benchmark for Formal Mathematics
Jan 30, 2026While the ecosystem of Lean and Mathlib has enjoyed celebrated success in formal mathematical reasoning with the help of large language models (LLMs), the absence of many folklore lemmas in Mathlib remains a persistent barrier that limits Lean's usability as an everyday tool for mathematicians like LaTeX or Maple. To address this, we introduce MathlibLemma, the first LLM-based multi-agent system to automate the discovery and formalization of mathematical folklore lemmas. This framework constitutes our primary contribution, proactively mining the missing connective tissue of mathematics. Its efficacy is demonstrated by the production of a verified library of folklore lemmas, a subset of which has already been formally merged into the latest build of Mathlib, thereby validating the system's real-world utility and alignment with expert standards. Leveraging this pipeline, we further construct the MathlibLemma benchmark, a suite of 4,028 type-checked Lean statements spanning a broad range of mathematical domains. By transforming the role of LLMs from passive consumers to active contributors, this work establishes a constructive methodology for the self-evolution of formal mathematical libraries.
Causal-PIK: Causality-based Physical Reasoning with a Physics-Informed Kernel
May 28, 2025



Tasks that involve complex interactions between objects with unknown dynamics make planning before execution difficult. These tasks require agents to iteratively improve their actions after actively exploring causes and effects in the environment. For these type of tasks, we propose Causal-PIK, a method that leverages Bayesian optimization to reason about causal interactions via a Physics-Informed Kernel to help guide efficient search for the best next action. Experimental results on Virtual Tools and PHYRE physical reasoning benchmarks show that Causal-PIK outperforms state-of-the-art results, requiring fewer actions to reach the goal. We also compare Causal-PIK to human studies, including results from a new user study we conducted on the PHYRE benchmark. We find that Causal-PIK remains competitive on tasks that are very challenging, even for human problem-solvers.
DexForce: Extracting Force-informed Actions from Kinesthetic Demonstrations for Dexterous Manipulation
Jan 17, 2025



Imitation learning requires high-quality demonstrations consisting of sequences of state-action pairs. For contact-rich dexterous manipulation tasks that require fine-grained dexterity, the actions in these state-action pairs must produce the right forces. Current widely-used methods for collecting dexterous manipulation demonstrations are difficult to use for demonstrating contact-rich tasks due to unintuitive human-to-robot motion retargeting and the lack of direct haptic feedback. Motivated by this, we propose DexForce, a method for collecting demonstrations of contact-rich dexterous manipulation. DexForce leverages contact forces, measured during kinesthetic demonstrations, to compute force-informed actions for policy learning. We use DexForce to collect demonstrations for six tasks and show that policies trained on our force-informed actions achieve an average success rate of 76% across all tasks. In contrast, policies trained directly on actions that do not account for contact forces have near-zero success rates. We also conduct a study ablating the inclusion of force data in policy observations. We find that while using force data never hurts policy performance, it helps the most for tasks that require an advanced level of precision and coordination, like opening an AirPods case and unscrewing a nut.
Efficient Policy Evaluation with Safety Constraint for Reinforcement Learning
Oct 08, 2024


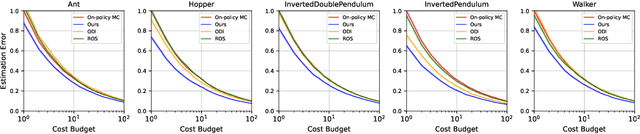
In reinforcement learning, classic on-policy evaluation methods often suffer from high variance and require massive online data to attain the desired accuracy. Previous studies attempt to reduce evaluation variance by searching for or designing proper behavior policies to collect data. However, these approaches ignore the safety of such behavior policies -- the designed behavior policies have no safety guarantee and may lead to severe damage during online executions. In this paper, to address the challenge of reducing variance while ensuring safety simultaneously, we propose an optimal variance-minimizing behavior policy under safety constraints. Theoretically, while ensuring safety constraints, our evaluation method is unbiased and has lower variance than on-policy evaluation. Empirically, our method is the only existing method to achieve both substantial variance reduction and safety constraint satisfaction. Furthermore, we show our method is even superior to previous methods in both variance reduction and execution safety.
Doubly Optimal Policy Evaluation for Reinforcement Learning
Oct 03, 2024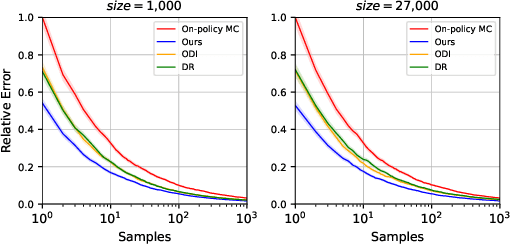
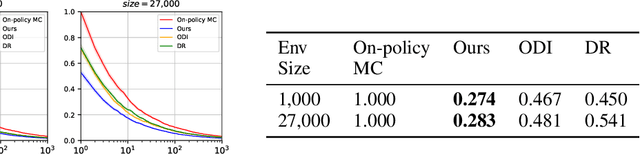
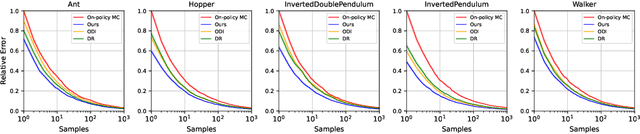
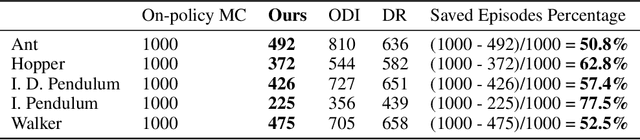
Policy evaluation estimates the performance of a policy by (1) collecting data from the environment and (2) processing raw data into a meaningful estimate. Due to the sequential nature of reinforcement learning, any improper data-collecting policy or data-processing method substantially deteriorates the variance of evaluation results over long time steps. Thus, policy evaluation often suffers from large variance and requires massive data to achieve the desired accuracy. In this work, we design an optimal combination of data-collecting policy and data-processing baseline. Theoretically, we prove our doubly optimal policy evaluation method is unbiased and guaranteed to have lower variance than previously best-performing methods. Empirically, compared with previous works, we show our method reduces variance substantially and achieves superior empirical performance.
AO-Grasp: Articulated Object Grasp Generation
Oct 24, 2023



We introduce AO-Grasp, a grasp proposal method that generates stable and actionable 6 degree-of-freedom grasps for articulated objects. Our generated grasps enable robots to interact with articulated objects, such as opening and closing cabinets and appliances. Given a segmented partial point cloud of a single articulated object, AO-Grasp predicts the best grasp points on the object with a novel Actionable Grasp Point Predictor model and then finds corresponding grasp orientations for each point by leveraging a state-of-the-art rigid object grasping method. We train AO-Grasp on our new AO-Grasp Dataset, which contains 48K actionable parallel-jaw grasps on synthetic articulated objects. In simulation, AO-Grasp achieves higher grasp success rates than existing rigid object grasping and articulated object interaction baselines on both train and test categories. Additionally, we evaluate AO-Grasp on 120 realworld scenes of objects with varied geometries, articulation axes, and joint states, where AO-Grasp produces successful grasps on 67.5% of scenes, while the baseline only produces successful grasps on 33.3% of scenes.
What do we learn from a large-scale study of pre-trained visual representations in sim and real environments?
Oct 03, 2023



We present a large empirical investigation on the use of pre-trained visual representations (PVRs) for training downstream policies that execute real-world tasks. Our study spans five different PVRs, two different policy-learning paradigms (imitation and reinforcement learning), and three different robots for 5 distinct manipulation and indoor navigation tasks. From this effort, we can arrive at three insights: 1) the performance trends of PVRs in the simulation are generally indicative of their trends in the real world, 2) the use of PVRs enables a first-of-its-kind result with indoor ImageNav (zero-shot transfer to a held-out scene in the real world), and 3) the benefits from variations in PVRs, primarily data-augmentation and fine-tuning, also transfer to the real-world performance. See project website for additional details and visuals.
Where are we in the search for an Artificial Visual Cortex for Embodied Intelligence?
Mar 31, 2023



We present the largest and most comprehensive empirical study of pre-trained visual representations (PVRs) or visual 'foundation models' for Embodied AI. First, we curate CortexBench, consisting of 17 different tasks spanning locomotion, navigation, dexterous, and mobile manipulation. Next, we systematically evaluate existing PVRs and find that none are universally dominant. To study the effect of pre-training data scale and diversity, we combine over 4,000 hours of egocentric videos from 7 different sources (over 5.6M images) and ImageNet to train different-sized vision transformers using Masked Auto-Encoding (MAE) on slices of this data. Contrary to inferences from prior work, we find that scaling dataset size and diversity does not improve performance universally (but does so on average). Our largest model, named VC-1, outperforms all prior PVRs on average but does not universally dominate either. Finally, we show that task or domain-specific adaptation of VC-1 leads to substantial gains, with VC-1 (adapted) achieving competitive or superior performance than the best known results on all of the benchmarks in CortexBench. These models required over 10,000 GPU-hours to train and can be found on our website for the benefit of the research community.