 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Policy Selection and Fine-Tuning under Interaction Budgets for Offline-to-Online Reinforcement Learning
May 06, 2026In offline-to-online reinforcement learning (O2O-RL), policies are first safely trained offline using previously collected datasets and then further fine-tuned for tasks via limited online interactions. In a typical O2O-RL pipeline, candidate policies trained with offline RL are evaluated via either off-policy evaluation (OPE) or online evaluation (OE). The policy with the highest estimated value is then deployed and continually fine-tuned. However, this setup has two main issues. First, OPE can be unreliable, making it risky to deploy a policy based solely on those estimates, whereas OE may identify a viable policy with substantial online interaction, which could have been used for fine-tuning. Second--and more importantly--it is also often not possible to determine a priori whether a pretrained policy will improve with post-deployment fine-tuning, especially in non-stationary environments. As a result, procedures committing to a single deployed policy are impractical in many real-world settings. Moreover, a naive remedy that exhaustively fine-tunes all candidates would violate interaction budget constraints and is likewise infeasible. In this paper, we propose a novel adaptive approach for policy selection and fine-tuning under online interaction budgets in O2O-RL. Following the standard pipeline, we first train a set of candidate policies with different offline RL algorithms and hyperparameters; we then perform OPE to obtain initial performance estimates. We next adaptively select and fine-tune the policies based on their predicted performance via an upper-confidence-bound approach thereby making efficient use of online interactions. We demonstrate that our approach improves upon O2O-RL baselines with various benchmarks.
Almost Sure Convergence of Differential Temporal Difference Learning for Average Reward Markov Decision Processes
Feb 18, 2026The average reward is a fundamental performance metric in reinforcement learning (RL) focusing on the long-run performance of an agent. Differential temporal difference (TD) learning algorithms are a major advance for average reward RL as they provide an efficient online method to learn the value functions associated with the average reward in both on-policy and off-policy settings. However, existing convergence guarantees require a local clock in learning rates tied to state visit counts, which practitioners do not use and does not extend beyond tabular settings. We address this limitation by proving the almost sure convergence of on-policy $n$-step differential TD for any $n$ using standard diminishing learning rates without a local clock. We then derive three sufficient conditions under which off-policy $n$-step differential TD also converges without a local clock. These results strengthen the theoretical foundations of differential TD and bring its convergence analysis closer to practical implementations.
MathlibLemma: Folklore Lemma Generation and Benchmark for Formal Mathematics
Jan 30, 2026While the ecosystem of Lean and Mathlib has enjoyed celebrated success in formal mathematical reasoning with the help of large language models (LLMs), the absence of many folklore lemmas in Mathlib remains a persistent barrier that limits Lean's usability as an everyday tool for mathematicians like LaTeX or Maple. To address this, we introduce MathlibLemma, the first LLM-based multi-agent system to automate the discovery and formalization of mathematical folklore lemmas. This framework constitutes our primary contribution, proactively mining the missing connective tissue of mathematics. Its efficacy is demonstrated by the production of a verified library of folklore lemmas, a subset of which has already been formally merged into the latest build of Mathlib, thereby validating the system's real-world utility and alignment with expert standards. Leveraging this pipeline, we further construct the MathlibLemma benchmark, a suite of 4,028 type-checked Lean statements spanning a broad range of mathematical domains. By transforming the role of LLMs from passive consumers to active contributors, this work establishes a constructive methodology for the self-evolution of formal mathematical libraries.
Multi-agent DRL-based Lane Change Decision Model for Cooperative Planning in Mixed Traffic
Jan 16, 2026Connected automated vehicles (CAVs) possess the ability to communicate and coordinate with one another, enabling cooperative platooning that enhances both energy efficiency and traffic flow. However, during the initial stage of CAV deployment, the sparse distribution of CAVs among human-driven vehicles reduces the likelihood of forming effective cooperative platoons. To address this challenge, this study proposes a hybrid multi-agent lane change decision model aimed at increasing CAV participation in cooperative platooning and maximizing its associated benefits. The proposed model employs the QMIX framework, integrating traffic data processed through a convolutional neural network (CNN-QMIX). This architecture addresses a critical issue in dynamic traffic scenarios by enabling CAVs to make optimal decisions irrespective of the varying number of CAVs present in mixed traffic. Additionally, a trajectory planner and a model predictive controller are designed to ensure smooth and safe lane-change execution. The proposed model is trained and evaluated within a microsimulation environment under varying CAV market penetration rates. The results demonstrate that the proposed model efficiently manages fluctuating traffic agent numbers, significantly outperforming the baseline rule-based models. Notably, it enhances cooperative platooning rates up to 26.2\%, showcasing its potential to optimize CAV cooperation and traffic dynamics during the early stage of deployment.
Prompt-Driven Domain Adaptation for End-to-End Autonomous Driving via In-Context RL
Nov 16, 2025
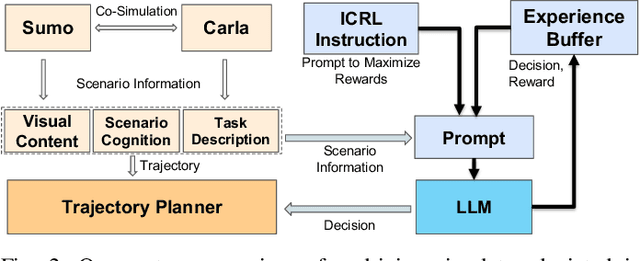


Despite significant progress and advances in autonomous driving, many end-to-end systems still struggle with domain adaptation (DA), such as transferring a policy trained under clear weather to adverse weather conditions. Typical DA strategies in the literature include collecting additional data in the target domain or re-training the model, or both. Both these strategies quickly become impractical as we increase scale and complexity of driving. These limitations have encouraged investigation into few-shot and zero-shot prompt-driven DA at inference time involving LLMs and VLMs. These methods work by adding a few state-action trajectories during inference to the prompt (similar to in-context learning). However, there are two limitations of such an approach: $(i)$ prompt-driven DA methods are currently restricted to perception tasks such as detection and segmentation and $(ii)$ they require expert few-shot data. In this work, we present a new approach to inference-time few-shot prompt-driven DA for closed-loop autonomous driving in adverse weather condition using in-context reinforcement learning (ICRL). Similar to other prompt-driven DA methods, our approach does not require any updates to the model parameters nor does it require additional data collection in adversarial weather regime. Furthermore, our approach advances the state-of-the-art in prompt-driven DA by extending to closed driving using general trajectories observed during inference. Our experiments using the CARLA simulator show that ICRL results in safer, more efficient, and more comfortable driving policies in the target domain compared to state-of-the-art prompt-driven DA baselines.
Towards Formalizing Reinforcement Learning Theory
Nov 05, 2025In this paper, we formalize the almost sure convergence of $Q$-learning and linear temporal difference (TD) learning with Markovian samples using the Lean 4 theorem prover based on the Mathlib library. $Q$-learning and linear TD are among the earliest and most influential reinforcement learning (RL) algorithms. The investigation of their convergence properties is not only a major research topic during the early development of the RL field but also receives increasing attention nowadays. This paper formally verifies their almost sure convergence in a unified framework based on the Robbins-Siegmund theorem. The framework developed in this work can be easily extended to convergence rates and other modes of convergence. This work thus makes an important step towards fully formalizing convergent RL results. The code is available at https://github.com/ShangtongZhang/rl-theory-in-lean.
Extensions of Robbins-Siegmund Theorem with Applications in Reinforcement Learning
Sep 30, 2025The Robbins-Siegmund theorem establishes the convergence of stochastic processes that are almost supermartingales and is foundational for analyzing a wide range of stochastic iterative algorithms in stochastic approximation and reinforcement learning (RL). However, its original form has a significant limitation as it requires the zero-order term to be summable. In many important RL applications, this summable condition, however, cannot be met. This limitation motivates us to extend the Robbins-Siegmund theorem for almost supermartingales where the zero-order term is not summable but only square summable. Particularly, we introduce a novel and mild assumption on the increments of the stochastic processes. This together with the square summable condition enables an almost sure convergence to a bounded set. Additionally, we further provide almost sure convergence rates, high probability concentration bounds, and $L^p$ convergence rates. We then apply the new results in stochastic approximation and RL. Notably, we obtain the first almost sure convergence rate, the first high probability concentration bound, and the first $L^p$ convergence rate for $Q$-learning with linear function approximation.
Finite Sample Analysis of Linear Temporal Difference Learning with Arbitrary Features
May 27, 2025Linear TD($\lambda$) is one of the most fundamental reinforcement learning algorithms for policy evaluation. Previously, convergence rates are typically established under the assumption of linearly independent features, which does not hold in many practical scenarios. This paper instead establishes the first $L^2$ convergence rates for linear TD($\lambda$) operating under arbitrary features, without making any algorithmic modification or additional assumptions. Our results apply to both the discounted and average-reward settings. To address the potential non-uniqueness of solutions resulting from arbitrary features, we develop a novel stochastic approximation result featuring convergence rates to the solution set instead of a single point.
Counterfactual Explanations for Continuous Action Reinforcement Learning
May 19, 2025Reinforcement Learning (RL) has shown great promise in domains like healthcare and robotics but often struggles with adoption due to its lack of interpretability. Counterfactual explanations, which address "what if" scenarios, provide a promising avenue for understanding RL decisions but remain underexplored for continuous action spaces. We propose a novel approach for generating counterfactual explanations in continuous action RL by computing alternative action sequences that improve outcomes while minimizing deviations from the original sequence. Our approach leverages a distance metric for continuous actions and accounts for constraints such as adhering to predefined policies in specific states. Evaluations in two RL domains, Diabetes Control and Lunar Lander, demonstrate the effectiveness, efficiency, and generalization of our approach, enabling more interpretable and trustworthy RL applications.
Experience Replay Addresses Loss of Plasticity in Continual Learning
Mar 25, 2025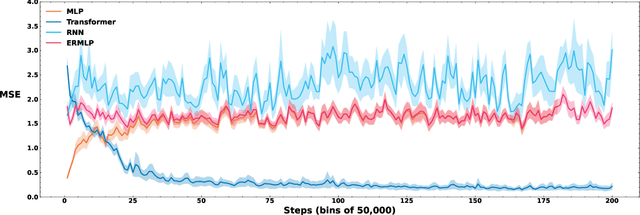
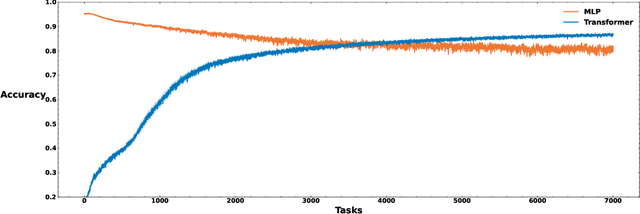
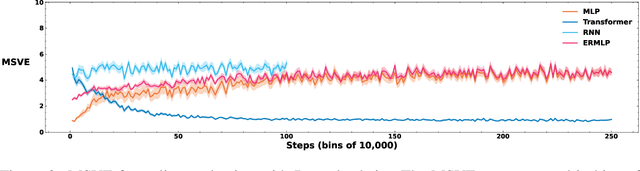
Loss of plasticity is one of the main challenges in continual learning with deep neural networks, where neural networks trained via backpropagation gradually lose their ability to adapt to new tasks and perform significantly worse than their freshly initialized counterparts. The main contribution of this paper is to propose a new hypothesis that experience replay addresses the loss of plasticity in continual learning. Here, experience replay is a form of memory. We provide supporting evidence for this hypothesis. In particular, we demonstrate in multiple different tasks, including regression, classification, and policy evaluation, that by simply adding an experience replay and processing the data in the experience replay with Transformers, the loss of plasticity disappears. Notably, we do not alter any standard components of deep learning. For example, we do not change backpropagation. We do not modify the activation functions. And we do not use any regularization. We conjecture that experience replay and Transformers can address the loss of plasticity because of the in-context learning phenomenon.