 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcedural Generation of Algorithm Discovery Tasks in Machine Learning
Mar 18, 2026Automating the development of machine learning algorithms has the potential to unlock new breakthroughs. However, our ability to improve and evaluate algorithm discovery systems has thus far been limited by existing task suites. They suffer from many issues, such as: poor evaluation methodologies; data contamination; and containing saturated or very similar problems. Here, we introduce DiscoGen, a procedural generator of algorithm discovery tasks for machine learning, such as developing optimisers for reinforcement learning or loss functions for image classification. Motivated by the success of procedural generation in reinforcement learning, DiscoGen spans millions of tasks of varying difficulty and complexity from a range of machine learning fields. These tasks are specified by a small number of configuration parameters and can be used to optimise algorithm discovery agents (ADAs). We present DiscoBench, a benchmark consisting of a fixed, small subset of DiscoGen tasks for principled evaluation of ADAs. Finally, we propose a number of ambitious, impactful research directions enabled by DiscoGen, in addition to experiments demonstrating its use for prompt optimisation of an ADA. DiscoGen is released open-source at https://github.com/AlexGoldie/discogen.
HyperVLA: Efficient Inference in Vision-Language-Action Models via Hypernetworks
Oct 06, 2025Built upon language and vision foundation models with strong generalization ability and trained on large-scale robotic data, Vision-Language-Action (VLA) models have recently emerged as a promising approach to learning generalist robotic policies. However, a key drawback of existing VLAs is their extremely high inference costs. In this paper, we propose HyperVLA to address this problem. Unlike existing monolithic VLAs that activate the whole model during both training and inference, HyperVLA uses a novel hypernetwork (HN)-based architecture that activates only a small task-specific policy during inference, while still retaining the high model capacity needed to accommodate diverse multi-task behaviors during training. Successfully training an HN-based VLA is nontrivial so HyperVLA contains several key algorithm design features that improve its performance, including properly utilizing the prior knowledge from existing vision foundation models, HN normalization, and an action generation strategy. Compared to monolithic VLAs, HyperVLA achieves a similar or even higher success rate for both zero-shot generalization and few-shot adaptation, while significantly reducing inference costs. Compared to OpenVLA, a state-of-the-art VLA model, HyperVLA reduces the number of activated parameters at test time by $90\times$, and accelerates inference speed by $120\times$. Code is publicly available at https://github.com/MasterXiong/HyperVLA
How Should We Meta-Learn Reinforcement Learning Algorithms?
Jul 23, 2025The process of meta-learning algorithms from data, instead of relying on manual design, is growing in popularity as a paradigm for improving the performance of machine learning systems. Meta-learning shows particular promise for reinforcement learning (RL), where algorithms are often adapted from supervised or unsupervised learning despite their suboptimality for RL. However, until now there has been a severe lack of comparison between different meta-learning algorithms, such as using evolution to optimise over black-box functions or LLMs to propose code. In this paper, we carry out this empirical comparison of the different approaches when applied to a range of meta-learned algorithms which target different parts of the RL pipeline. In addition to meta-train and meta-test performance, we also investigate factors including the interpretability, sample cost and train time for each meta-learning algorithm. Based on these findings, we propose several guidelines for meta-learning new RL algorithms which will help ensure that future learned algorithms are as performant as possible.
A Clean Slate for Offline Reinforcement Learning
Apr 15, 2025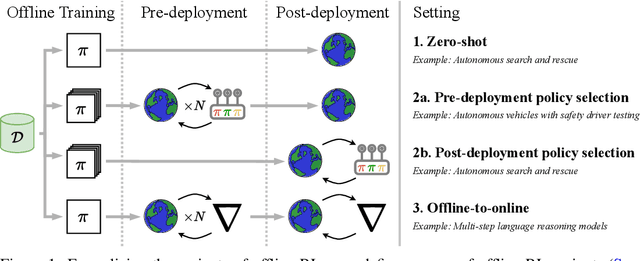

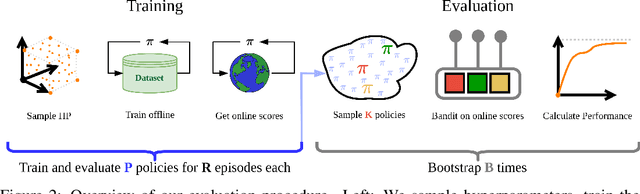

Progress in offline reinforcement learning (RL) has been impeded by ambiguous problem definitions and entangled algorithmic designs, resulting in inconsistent implementations, insufficient ablations, and unfair evaluations. Although offline RL explicitly avoids environment interaction, prior methods frequently employ extensive, undocumented online evaluation for hyperparameter tuning, complicating method comparisons. Moreover, existing reference implementations differ significantly in boilerplate code, obscuring their core algorithmic contributions. We address these challenges by first introducing a rigorous taxonomy and a transparent evaluation protocol that explicitly quantifies online tuning budgets. To resolve opaque algorithmic design, we provide clean, minimalistic, single-file implementations of various model-free and model-based offline RL methods, significantly enhancing clarity and achieving substantial speed-ups. Leveraging these streamlined implementations, we propose Unifloral, a unified algorithm that encapsulates diverse prior approaches within a single, comprehensive hyperparameter space, enabling algorithm development in a shared hyperparameter space. Using Unifloral with our rigorous evaluation protocol, we develop two novel algorithms - TD3-AWR (model-free) and MoBRAC (model-based) - which substantially outperform established baselines. Our implementation is publicly available at https://github.com/EmptyJackson/unifloral.
A Survey of In-Context Reinforcement Learning
Feb 11, 2025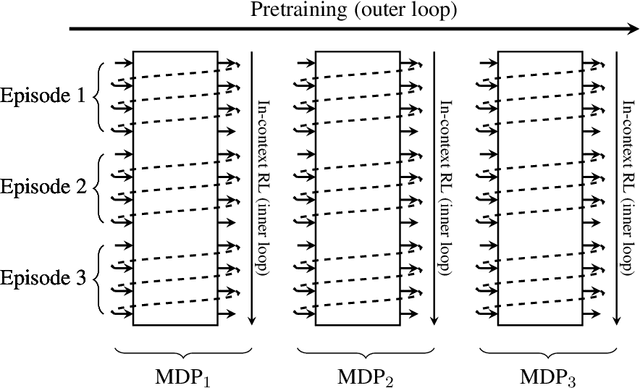
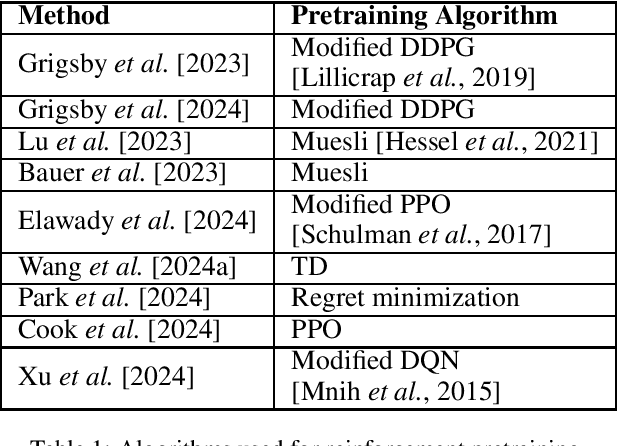
Reinforcement learning (RL) agents typically optimize their policies by performing expensive backward passes to update their network parameters. However, some agents can solve new tasks without updating any parameters by simply conditioning on additional context such as their action-observation histories. This paper surveys work on such behavior, known as in-context reinforcement learning.
Adam on Local Time: Addressing Nonstationarity in RL with Relative Adam Timesteps
Dec 22, 2024In reinforcement learning (RL), it is common to apply techniques used broadly in machine learning such as neural network function approximators and momentum-based optimizers. However, such tools were largely developed for supervised learning rather than nonstationary RL, leading practitioners to adopt target networks, clipped policy updates, and other RL-specific implementation tricks to combat this mismatch, rather than directly adapting this toolchain for use in RL. In this paper, we take a different approach and instead address the effect of nonstationarity by adapting the widely used Adam optimiser. We first analyse the impact of nonstationary gradient magnitude -- such as that caused by a change in target network -- on Adam's update size, demonstrating that such a change can lead to large updates and hence sub-optimal performance. To address this, we introduce Adam-Rel. Rather than using the global timestep in the Adam update, Adam-Rel uses the local timestep within an epoch, essentially resetting Adam's timestep to 0 after target changes. We demonstrate that this avoids large updates and reduces to learning rate annealing in the absence of such increases in gradient magnitude. Evaluating Adam-Rel in both on-policy and off-policy RL, we demonstrate improved performance in both Atari and Craftax. We then show that increases in gradient norm occur in RL in practice, and examine the differences between our theoretical model and the observed data.
Rate-Informed Discovery via Bayesian Adaptive Multifidelity Sampling
Nov 26, 2024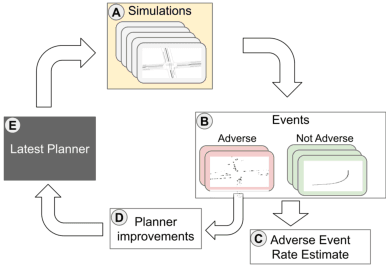
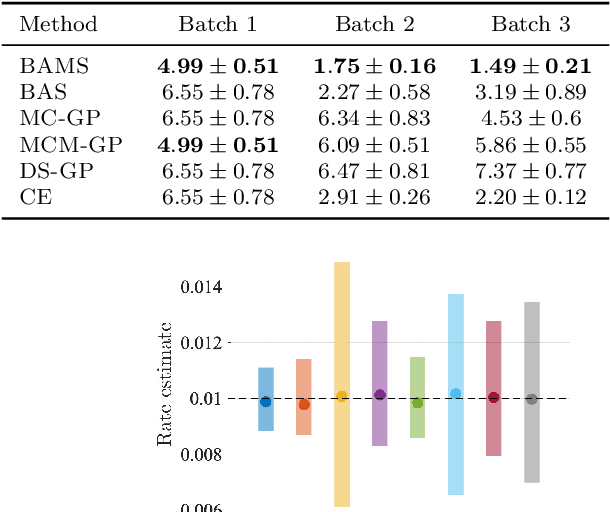
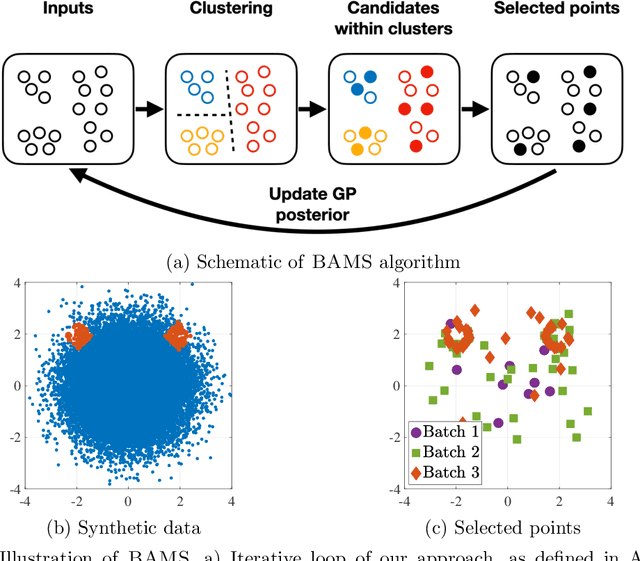
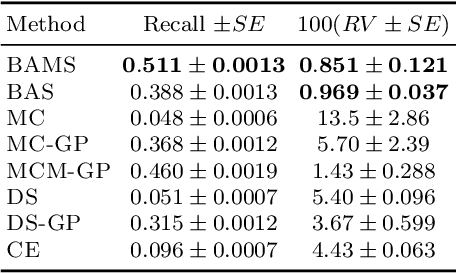
Ensuring the safety of autonomous vehicles (AVs) requires both accurate estimation of their performance and efficient discovery of potential failure cases. This paper introduces Bayesian adaptive multifidelity sampling (BAMS), which leverages the power of adaptive Bayesian sampling to achieve efficient discovery while simultaneously estimating the rate of adverse events. BAMS prioritizes exploration of regions with potentially low performance, leading to the identification of novel and critical scenarios that traditional methods might miss. Using real-world AV data we demonstrate that BAMS discovers 10 times as many issues as Monte Carlo (MC) and importance sampling (IS) baselines, while at the same time generating rate estimates with variances 15 and 6 times narrower than MC and IS baselines respectively.
IGDrivSim: A Benchmark for the Imitation Gap in Autonomous Driving
Nov 07, 2024



Developing autonomous vehicles that can navigate complex environments with human-level safety and efficiency is a central goal in self-driving research. A common approach to achieving this is imitation learning, where agents are trained to mimic human expert demonstrations collected from real-world driving scenarios. However, discrepancies between human perception and the self-driving car's sensors can introduce an \textit{imitation gap}, leading to imitation learning failures. In this work, we introduce \textbf{IGDrivSim}, a benchmark built on top of the Waymax simulator, designed to investigate the effects of the imitation gap in learning autonomous driving policy from human expert demonstrations. Our experiments show that this perception gap between human experts and self-driving agents can hinder the learning of safe and effective driving behaviors. We further show that combining imitation with reinforcement learning, using a simple penalty reward for prohibited behaviors, effectively mitigates these failures. Our code is open-sourced at: https://github.com/clemgris/IGDrivSim.git.
Can Learned Optimization Make Reinforcement Learning Less Difficult?
Jul 09, 2024While reinforcement learning (RL) holds great potential for decision making in the real world, it suffers from a number of unique difficulties which often need specific consideration. In particular: it is highly non-stationary; suffers from high degrees of plasticity loss; and requires exploration to prevent premature convergence to local optima and maximize return. In this paper, we consider whether learned optimization can help overcome these problems. Our method, Learned Optimization for Plasticity, Exploration and Non-stationarity (OPEN), meta-learns an update rule whose input features and output structure are informed by previously proposed solutions to these difficulties. We show that our parameterization is flexible enough to enable meta-learning in diverse learning contexts, including the ability to use stochasticity for exploration. Our experiments demonstrate that when meta-trained on single and small sets of environments, OPEN outperforms or equals traditionally used optimizers. Furthermore, OPEN shows strong generalization across a distribution of environments and a range of agent architectures.
A Bayesian Solution To The Imitation Gap
Jun 29, 2024



In many real-world settings, an agent must learn to act in environments where no reward signal can be specified, but a set of expert demonstrations is available. Imitation learning (IL) is a popular framework for learning policies from such demonstrations. However, in some cases, differences in observability between the expert and the agent can give rise to an imitation gap such that the expert's policy is not optimal for the agent and a naive application of IL can fail catastrophically. In particular, if the expert observes the Markov state and the agent does not, then the expert will not demonstrate the information-gathering behavior needed by the agent but not the expert. In this paper, we propose a Bayesian solution to the Imitation Gap (BIG), first using the expert demonstrations, together with a prior specifying the cost of exploratory behavior that is not demonstrated, to infer a posterior over rewards with Bayesian inverse reinforcement learning (IRL). BIG then uses the reward posterior to learn a Bayes-optimal policy. Our experiments show that BIG, unlike IL, allows the agent to explore at test time when presented with an imitation gap, whilst still learning to behave optimally using expert demonstrations when no such gap exists.