 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdam on Local Time: Addressing Nonstationarity in RL with Relative Adam Timesteps
Dec 22, 2024In reinforcement learning (RL), it is common to apply techniques used broadly in machine learning such as neural network function approximators and momentum-based optimizers. However, such tools were largely developed for supervised learning rather than nonstationary RL, leading practitioners to adopt target networks, clipped policy updates, and other RL-specific implementation tricks to combat this mismatch, rather than directly adapting this toolchain for use in RL. In this paper, we take a different approach and instead address the effect of nonstationarity by adapting the widely used Adam optimiser. We first analyse the impact of nonstationary gradient magnitude -- such as that caused by a change in target network -- on Adam's update size, demonstrating that such a change can lead to large updates and hence sub-optimal performance. To address this, we introduce Adam-Rel. Rather than using the global timestep in the Adam update, Adam-Rel uses the local timestep within an epoch, essentially resetting Adam's timestep to 0 after target changes. We demonstrate that this avoids large updates and reduces to learning rate annealing in the absence of such increases in gradient magnitude. Evaluating Adam-Rel in both on-policy and off-policy RL, we demonstrate improved performance in both Atari and Craftax. We then show that increases in gradient norm occur in RL in practice, and examine the differences between our theoretical model and the observed data.
Beyond the Boundaries of Proximal Policy Optimization
Nov 01, 2024
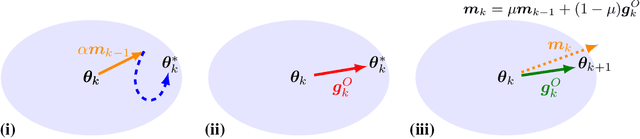

Proximal policy optimization (PPO) is a widely-used algorithm for on-policy reinforcement learning. This work offers an alternative perspective of PPO, in which it is decomposed into the inner-loop estimation of update vectors, and the outer-loop application of updates using gradient ascent with unity learning rate. Using this insight we propose outer proximal policy optimization (outer-PPO); a framework wherein these update vectors are applied using an arbitrary gradient-based optimizer. The decoupling of update estimation and update application enabled by outer-PPO highlights several implicit design choices in PPO that we challenge through empirical investigation. In particular we consider non-unity learning rates and momentum applied to the outer loop, and a momentum-bias applied to the inner estimation loop. Methods are evaluated against an aggressively tuned PPO baseline on Brax, Jumanji and MinAtar environments; non-unity learning rates and momentum both achieve statistically significant improvement on Brax and Jumanji, given the same hyperparameter tuning budget.
CURATe: Benchmarking Personalised Alignment of Conversational AI Assistants
Oct 28, 2024



We introduce a multi-turn benchmark for evaluating personalised alignment in LLM-based AI assistants, focusing on their ability to handle user-provided safety-critical contexts. Our assessment of ten leading models across five scenarios (each with 337 use cases) reveals systematic inconsistencies in maintaining user-specific consideration, with even top-rated "harmless" models making recommendations that should be recognised as obviously harmful to the user given the context provided. Key failure modes include inappropriate weighing of conflicting preferences, sycophancy (prioritising user preferences above safety), a lack of attentiveness to critical user information within the context window, and inconsistent application of user-specific knowledge. The same systematic biases were observed in OpenAI's o1, suggesting that strong reasoning capacities do not necessarily transfer to this kind of personalised thinking. We find that prompting LLMs to consider safety-critical context significantly improves performance, unlike a generic 'harmless and helpful' instruction. Based on these findings, we propose research directions for embedding self-reflection capabilities, online user modelling, and dynamic risk assessment in AI assistants. Our work emphasises the need for nuanced, context-aware approaches to alignment in systems designed for persistent human interaction, aiding the development of safe and considerate AI assistants.
Simplifying Deep Temporal Difference Learning
Jul 05, 2024



Q-learning played a foundational role in the field reinforcement learning (RL). However, TD algorithms with off-policy data, such as Q-learning, or nonlinear function approximation like deep neural networks require several additional tricks to stabilise training, primarily a replay buffer and target networks. Unfortunately, the delayed updating of frozen network parameters in the target network harms the sample efficiency and, similarly, the replay buffer introduces memory and implementation overheads. In this paper, we investigate whether it is possible to accelerate and simplify TD training while maintaining its stability. Our key theoretical result demonstrates for the first time that regularisation techniques such as LayerNorm can yield provably convergent TD algorithms without the need for a target network, even with off-policy data. Empirically, we find that online, parallelised sampling enabled by vectorised environments stabilises training without the need of a replay buffer. Motivated by these findings, we propose PQN, our simplified deep online Q-Learning algorithm. Surprisingly, this simple algorithm is competitive with more complex methods like: Rainbow in Atari, R2D2 in Hanabi, QMix in Smax, PPO-RNN in Craftax, and can be up to 50x faster than traditional DQN without sacrificing sample efficiency. In an era where PPO has become the go-to RL algorithm, PQN reestablishes Q-learning as a viable alternative. We make our code available at: https://github.com/mttga/purejaxql.
Policy-Guided Diffusion
Apr 09, 2024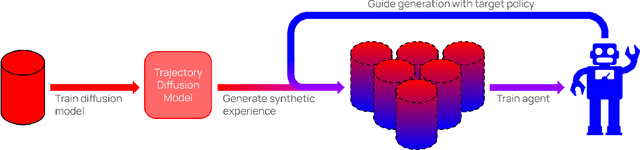


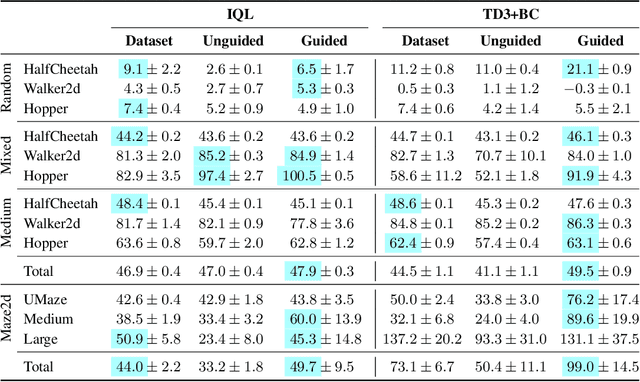
In many real-world settings, agents must learn from an offline dataset gathered by some prior behavior policy. Such a setting naturally leads to distribution shift between the behavior policy and the target policy being trained - requiring policy conservatism to avoid instability and overestimation bias. Autoregressive world models offer a different solution to this by generating synthetic, on-policy experience. However, in practice, model rollouts must be severely truncated to avoid compounding error. As an alternative, we propose policy-guided diffusion. Our method uses diffusion models to generate entire trajectories under the behavior distribution, applying guidance from the target policy to move synthetic experience further on-policy. We show that policy-guided diffusion models a regularized form of the target distribution that balances action likelihood under both the target and behavior policies, leading to plausible trajectories with high target policy probability, while retaining a lower dynamics error than an offline world model baseline. Using synthetic experience from policy-guided diffusion as a drop-in substitute for real data, we demonstrate significant improvements in performance across a range of standard offline reinforcement learning algorithms and environments. Our approach provides an effective alternative to autoregressive offline world models, opening the door to the controllable generation of synthetic training data.
Craftax: A Lightning-Fast Benchmark for Open-Ended Reinforcement Learning
Feb 26, 2024

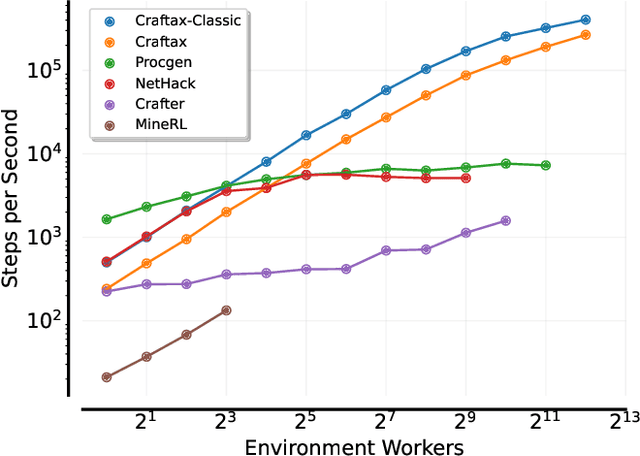

Benchmarks play a crucial role in the development and analysis of reinforcement learning (RL) algorithms. We identify that existing benchmarks used for research into open-ended learning fall into one of two categories. Either they are too slow for meaningful research to be performed without enormous computational resources, like Crafter, NetHack and Minecraft, or they are not complex enough to pose a significant challenge, like Minigrid and Procgen. To remedy this, we first present Craftax-Classic: a ground-up rewrite of Crafter in JAX that runs up to 250x faster than the Python-native original. A run of PPO using 1 billion environment interactions finishes in under an hour using only a single GPU and averages 90% of the optimal reward. To provide a more compelling challenge we present the main Craftax benchmark, a significant extension of the Crafter mechanics with elements inspired from NetHack. Solving Craftax requires deep exploration, long term planning and memory, as well as continual adaptation to novel situations as more of the world is discovered. We show that existing methods including global and episodic exploration, as well as unsupervised environment design fail to make material progress on the benchmark. We believe that Craftax can for the first time allow researchers to experiment in a complex, open-ended environment with limited computational resources.
JaxMARL: Multi-Agent RL Environments in JAX
Nov 20, 2023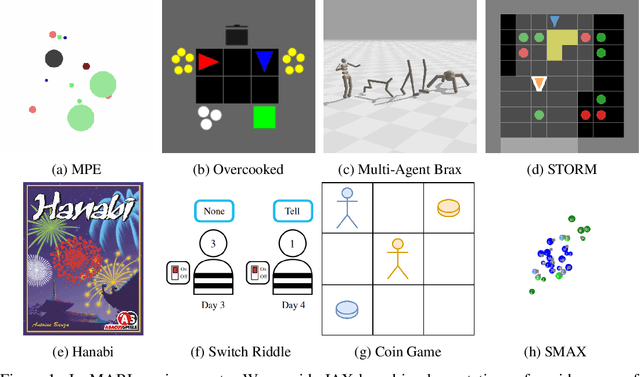

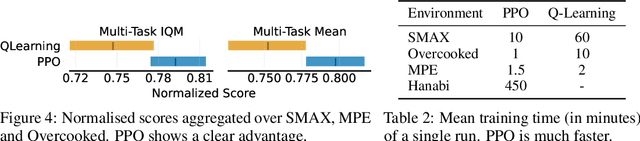
Benchmarks play an important role in the development of machine learning algorithms. For example, research in reinforcement learning (RL) has been heavily influenced by available environments and benchmarks. However, RL environments are traditionally run on the CPU, limiting their scalability with typical academic compute. Recent advancements in JAX have enabled the wider use of hardware acceleration to overcome these computational hurdles, enabling massively parallel RL training pipelines and environments. This is particularly useful for multi-agent reinforcement learning (MARL) research. First of all, multiple agents must be considered at each environment step, adding computational burden, and secondly, the sample complexity is increased due to non-stationarity, decentralised partial observability, or other MARL challenges. In this paper, we present JaxMARL, the first open-source code base that combines ease-of-use with GPU enabled efficiency, and supports a large number of commonly used MARL environments as well as popular baseline algorithms. When considering wall clock time, our experiments show that per-run our JAX-based training pipeline is up to 12500x faster than existing approaches. This enables efficient and thorough evaluations, with the potential to alleviate the evaluation crisis of the field. We also introduce and benchmark SMAX, a vectorised, simplified version of the popular StarCraft Multi-Agent Challenge, which removes the need to run the StarCraft II game engine. This not only enables GPU acceleration, but also provides a more flexible MARL environment, unlocking the potential for self-play, meta-learning, and other future applications in MARL. We provide code at https://github.com/flairox/jaxmarl.
Trust-Region-Free Policy Optimization for Stochastic Policies
Feb 15, 2023Trust Region Policy Optimization (TRPO) is an iterative method that simultaneously maximizes a surrogate objective and enforces a trust region constraint over consecutive policies in each iteration. The combination of the surrogate objective maximization and the trust region enforcement has been shown to be crucial to guarantee a monotonic policy improvement. However, solving a trust-region-constrained optimization problem can be computationally intensive as it requires many steps of conjugate gradient and a large number of on-policy samples. In this paper, we show that the trust region constraint over policies can be safely substituted by a trust-region-free constraint without compromising the underlying monotonic improvement guarantee. The key idea is to generalize the surrogate objective used in TRPO in a way that a monotonic improvement guarantee still emerges as a result of constraining the maximum advantage-weighted ratio between policies. This new constraint outlines a conservative mechanism for iterative policy optimization and sheds light on practical ways to optimize the generalized surrogate objective. We show that the new constraint can be effectively enforced by being conservative when optimizing the generalized objective function in practice. We call the resulting algorithm Trust-REgion-Free Policy Optimization (TREFree) as it is free of any explicit trust region constraints. Empirical results show that TREFree outperforms TRPO and Proximal Policy Optimization (PPO) in terms of policy performance and sample efficiency.
SMACv2: An Improved Benchmark for Cooperative Multi-Agent Reinforcement Learning
Dec 14, 2022
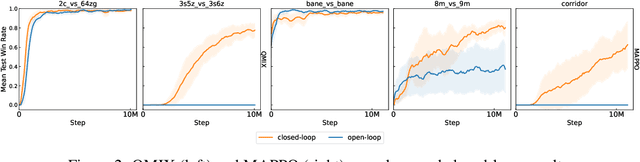
The availability of challenging benchmarks has played a key role in the recent progress of machine learning. In cooperative multi-agent reinforcement learning, the StarCraft Multi-Agent Challenge (SMAC) has become a popular testbed for centralised training with decentralised execution. However, after years of sustained improvement on SMAC, algorithms now achieve near-perfect performance. In this work, we conduct new analysis demonstrating that SMAC is not sufficiently stochastic to require complex closed-loop policies. In particular, we show that an open-loop policy conditioned only on the timestep can achieve non-trivial win rates for many SMAC scenarios. To address this limitation, we introduce SMACv2, a new version of the benchmark where scenarios are procedurally generated and require agents to generalise to previously unseen settings (from the same distribution) during evaluation. We show that these changes ensure the benchmark requires the use of closed-loop policies. We evaluate state-of-the-art algorithms on SMACv2 and show that it presents significant challenges not present in the original benchmark. Our analysis illustrates that SMACv2 addresses the discovered deficiencies of SMAC and can help benchmark the next generation of MARL methods. Videos of training are available at https://sites.google.com/view/smacv2
Generalization in Cooperative Multi-Agent Systems
Jan 31, 2022


Collective intelligence is a fundamental trait shared by several species of living organisms. It has allowed them to thrive in the diverse environmental conditions that exist on our planet. From simple organisations in an ant colony to complex systems in human groups, collective intelligence is vital for solving complex survival tasks. As is commonly observed, such natural systems are flexible to changes in their structure. Specifically, they exhibit a high degree of generalization when the abilities or the total number of agents changes within a system. We term this phenomenon as Combinatorial Generalization (CG). CG is a highly desirable trait for autonomous systems as it can increase their utility and deployability across a wide range of applications. While recent works addressing specific aspects of CG have shown impressive results on complex domains, they provide no performance guarantees when generalizing towards novel situations. In this work, we shed light on the theoretical underpinnings of CG for cooperative multi-agent systems (MAS). Specifically, we study generalization bounds under a linear dependence of the underlying dynamics on the agent capabilities, which can be seen as a generalization of Successor Features to MAS. We then extend the results first for Lipschitz and then arbitrary dependence of rewards on team capabilities. Finally, empirical analysis on various domains using the framework of multi-agent reinforcement learning highlights important desiderata for multi-agent algorithms towards ensuring CG.