 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Rubric Generation for Improving LLM Judge and Reward Modeling for Open-ended Tasks
Feb 04, 2026Recently, rubrics have been used to guide LLM judges in capturing subjective, nuanced, multi-dimensional human preferences, and have been extended from evaluation to reward signals for reinforcement fine-tuning (RFT). However, rubric generation remains hard to control: rubrics often lack coverage, conflate dimensions, misalign preference direction, and contain redundant or highly correlated criteria, degrading judge accuracy and producing suboptimal rewards during RFT. We propose RRD, a principled framework for rubric refinement built on a recursive decompose-filter cycle. RRD decomposes coarse rubrics into fine-grained, discriminative criteria, expanding coverage while sharpening separation between responses. A complementary filtering mechanism removes misaligned and redundant rubrics, and a correlation-aware weighting scheme prevents over-representing highly correlated criteria, yielding rubric sets that are informative, comprehensive, and non-redundant. Empirically, RRD delivers large, consistent gains across both evaluation and training: it improves preference-judgment accuracy on JudgeBench and PPE for both GPT-4o and Llama3.1-405B judges, achieving top performance in all settings with up to +17.7 points on JudgeBench. When used as the reward source for RFT on WildChat, it yields substantially stronger and more stable learning signals, boosting reward by up to 160% (Qwen3-4B) and 60% (Llama3.1-8B) versus 10-20% for prior rubric baselines, with gains that transfer to HealthBench-Hard and BiGGen Bench. Overall, RRD establishes recursive rubric refinement as a scalable and interpretable foundation for LLM judging and reward modeling in open-ended domains.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Training AI Co-Scientists Using Rubric Rewards
Dec 29, 2025AI co-scientists are emerging as a tool to assist human researchers in achieving their research goals. A crucial feature of these AI co-scientists is the ability to generate a research plan given a set of aims and constraints. The plan may be used by researchers for brainstorming, or may even be implemented after further refinement. However, language models currently struggle to generate research plans that follow all constraints and implicit requirements. In this work, we study how to leverage the vast corpus of existing research papers to train language models that generate better research plans. We build a scalable, diverse training corpus by automatically extracting research goals and goal-specific grading rubrics from papers across several domains. We then train models for research plan generation via reinforcement learning with self-grading. A frozen copy of the initial policy acts as the grader during training, with the rubrics creating a generator-verifier gap that enables improvements without external human supervision. To validate this approach, we conduct a study with human experts for machine learning research goals, spanning 225 hours. The experts prefer plans generated by our finetuned Qwen3-30B-A3B model over the initial model for 70% of research goals, and approve 84% of the automatically extracted goal-specific grading rubrics. To assess generality, we also extend our approach to research goals from medical papers, and new arXiv preprints, evaluating with a jury of frontier models. Our finetuning yields 12-22% relative improvements and significant cross-domain generalization, proving effective even in problem settings like medical research where execution feedback is infeasible. Together, these findings demonstrate the potential of a scalable, automated training recipe as a step towards improving general AI co-scientists.
Balanced Accuracy: The Right Metric for Evaluating LLM Judges -- Explained through Youden's J statistic
Dec 08, 2025

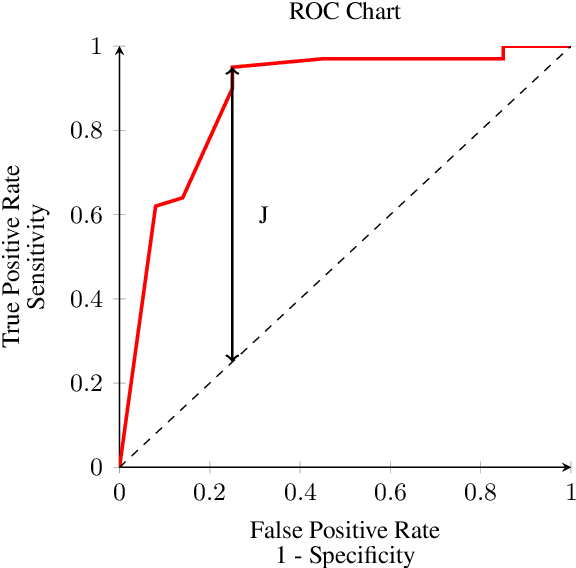

Rigorous evaluation of large language models (LLMs) relies on comparing models by the prevalence of desirable or undesirable behaviors, such as task pass rates or policy violations. These prevalence estimates are produced by a classifier, either an LLM-as-a-judge or human annotators, making the choice of classifier central to trustworthy evaluation. Common metrics used for this choice, such as Accuracy, Precision, and F1, are sensitive to class imbalance and to arbitrary choices of positive class, and can favor judges that distort prevalence estimates. We show that Youden's $J$ statistic is theoretically aligned with choosing the best judge to compare models, and that Balanced Accuracy is an equivalent linear transformation of $J$. Through both analytical arguments and empirical examples and simulations, we demonstrate how selecting judges using Balanced Accuracy leads to better, more robust classifier selection.
The Decrypto Benchmark for Multi-Agent Reasoning and Theory of Mind
Jun 25, 2025As Large Language Models (LLMs) gain agentic abilities, they will have to navigate complex multi-agent scenarios, interacting with human users and other agents in cooperative and competitive settings. This will require new reasoning skills, chief amongst them being theory of mind (ToM), or the ability to reason about the "mental" states of other agents. However, ToM and other multi-agent abilities in LLMs are poorly understood, since existing benchmarks suffer from narrow scope, data leakage, saturation, and lack of interactivity. We thus propose Decrypto, a game-based benchmark for multi-agent reasoning and ToM drawing inspiration from cognitive science, computational pragmatics and multi-agent reinforcement learning. It is designed to be as easy as possible in all other dimensions, eliminating confounding factors commonly found in other benchmarks. To our knowledge, it is also the first platform for designing interactive ToM experiments. We validate the benchmark design through comprehensive empirical evaluations of frontier LLMs, robustness studies, and human-AI cross-play experiments. We find that LLM game-playing abilities lag behind humans and simple word-embedding baselines. We then create variants of two classic cognitive science experiments within Decrypto to evaluate three key ToM abilities. Surprisingly, we find that state-of-the-art reasoning models are significantly worse at those tasks than their older counterparts. This demonstrates that Decrypto addresses a crucial gap in current reasoning and ToM evaluations, and paves the path towards better artificial agents.
No Regrets: Investigating and Improving Regret Approximations for Curriculum Discovery
Aug 27, 2024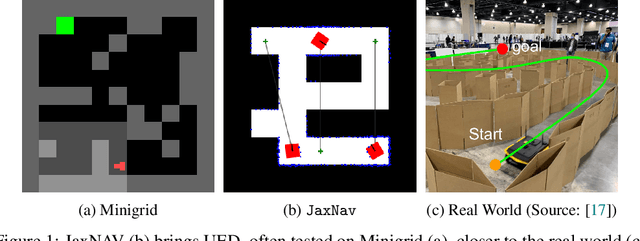
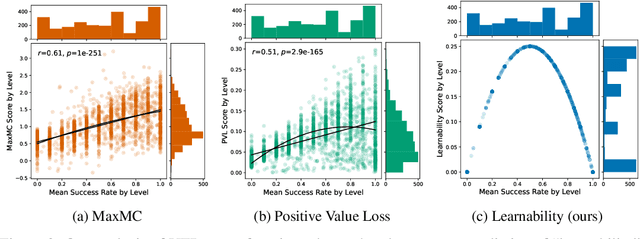
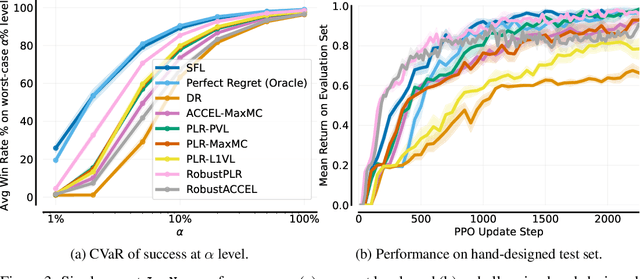
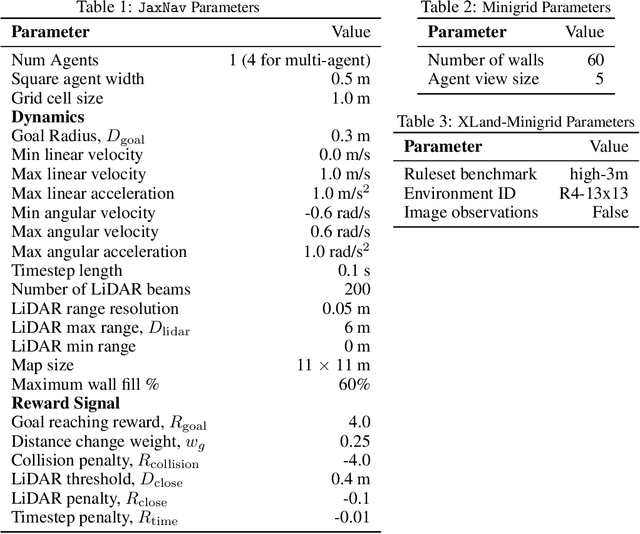
What data or environments to use for training to improve downstream performance is a longstanding and very topical question in reinforcement learning. In particular, Unsupervised Environment Design (UED) methods have gained recent attention as their adaptive curricula enable agents to be robust to in- and out-of-distribution tasks. We ask to what extent these methods are themselves robust when applied to a novel setting, closely inspired by a real-world robotics problem. Surprisingly, we find that the state-of-the-art UED methods either do not improve upon the na\"{i}ve baseline of Domain Randomisation (DR), or require substantial hyperparameter tuning to do so. Our analysis shows that this is due to their underlying scoring functions failing to predict intuitive measures of ``learnability'', i.e., in finding the settings that the agent sometimes solves, but not always. Based on this, we instead directly train on levels with high learnability and find that this simple and intuitive approach outperforms UED methods and DR in several binary-outcome environments, including on our domain and the standard UED domain of Minigrid. We further introduce a new adversarial evaluation procedure for directly measuring robustness, closely mirroring the conditional value at risk (CVaR). We open-source all our code and present visualisations of final policies here: https://github.com/amacrutherford/sampling-for-learnability.
Mixture of Experts in a Mixture of RL settings
Jun 26, 2024Mixtures of Experts (MoEs) have gained prominence in (self-)supervised learning due to their enhanced inference efficiency, adaptability to distributed training, and modularity. Previous research has illustrated that MoEs can significantly boost Deep Reinforcement Learning (DRL) performance by expanding the network's parameter count while reducing dormant neurons, thereby enhancing the model's learning capacity and ability to deal with non-stationarity. In this work, we shed more light on MoEs' ability to deal with non-stationarity and investigate MoEs in DRL settings with "amplified" non-stationarity via multi-task training, providing further evidence that MoEs improve learning capacity. In contrast to previous work, our multi-task results allow us to better understand the underlying causes for the beneficial effect of MoE in DRL training, the impact of the various MoE components, and insights into how best to incorporate them in actor-critic-based DRL networks. Finally, we also confirm results from previous work.
Mixtures of Experts Unlock Parameter Scaling for Deep RL
Feb 13, 2024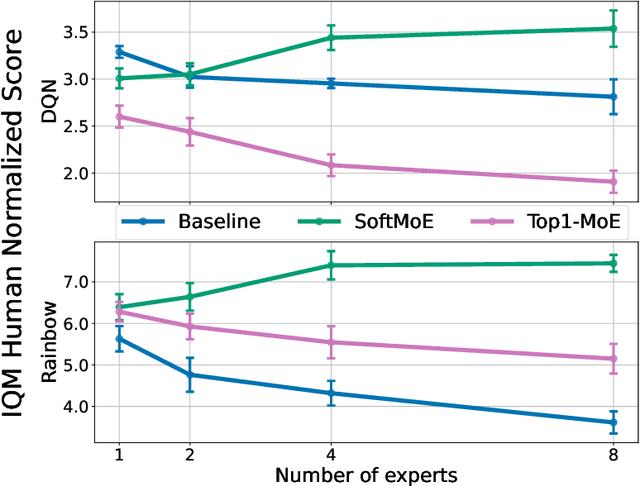
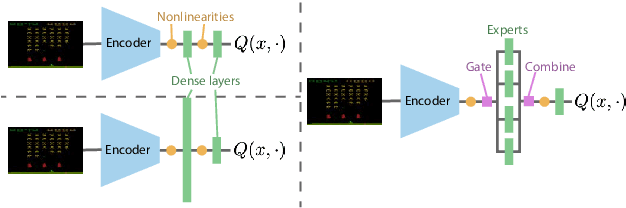
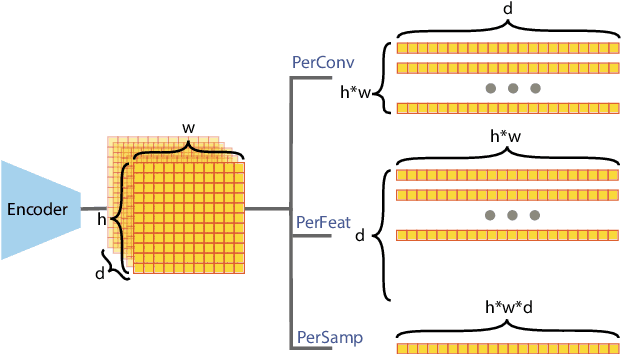

The recent rapid progress in (self) supervised learning models is in large part predicted by empirical scaling laws: a model's performance scales proportionally to its size. Analogous scaling laws remain elusive for reinforcement learning domains, however, where increasing the parameter count of a model often hurts its final performance. In this paper, we demonstrate that incorporating Mixture-of-Expert (MoE) modules, and in particular Soft MoEs (Puigcerver et al., 2023), into value-based networks results in more parameter-scalable models, evidenced by substantial performance increases across a variety of training regimes and model sizes. This work thus provides strong empirical evidence towards developing scaling laws for reinforcement learning.
Analysing the Sample Complexity of Opponent Shaping
Feb 08, 2024



Learning in general-sum games often yields collectively sub-optimal results. Addressing this, opponent shaping (OS) methods actively guide the learning processes of other agents, empirically leading to improved individual and group performances in many settings. Early OS methods use higher-order derivatives to shape the learning of co-players, making them unsuitable for shaping multiple learning steps. Follow-up work, Model-free Opponent Shaping (M-FOS), addresses these by reframing the OS problem as a meta-game. In contrast to early OS methods, there is little theoretical understanding of the M-FOS framework. Providing theoretical guarantees for M-FOS is hard because A) there is little literature on theoretical sample complexity bounds for meta-reinforcement learning B) M-FOS operates in continuous state and action spaces, so theoretical analysis is challenging. In this work, we present R-FOS, a tabular version of M-FOS that is more suitable for theoretical analysis. R-FOS discretises the continuous meta-game MDP into a tabular MDP. Within this discretised MDP, we adapt the $R_{max}$ algorithm, most prominently used to derive PAC-bounds for MDPs, as the meta-learner in the R-FOS algorithm. We derive a sample complexity bound that is exponential in the cardinality of the inner state and action space and the number of agents. Our bound guarantees that, with high probability, the final policy learned by an R-FOS agent is close to the optimal policy, apart from a constant factor. Finally, we investigate how R-FOS's sample complexity scales in the size of state-action space. Our theoretical results on scaling are supported empirically in the Matching Pennies environment.
Leading the Pack: N-player Opponent Shaping
Dec 26, 2023



Reinforcement learning solutions have great success in the 2-player general sum setting. In this setting, the paradigm of Opponent Shaping (OS), in which agents account for the learning of their co-players, has led to agents which are able to avoid collectively bad outcomes, whilst also maximizing their reward. These methods have currently been limited to 2-player game. However, the real world involves interactions with many more agents, with interactions on both local and global scales. In this paper, we extend Opponent Shaping (OS) methods to environments involving multiple co-players and multiple shaping agents. We evaluate on over 4 different environments, varying the number of players from 3 to 5, and demonstrate that model-based OS methods converge to equilibrium with better global welfare than naive learning. However, we find that when playing with a large number of co-players, OS methods' relative performance reduces, suggesting that in the limit OS methods may not perform well. Finally, we explore scenarios where more than one OS method is present, noticing that within games requiring a majority of cooperating agents, OS methods converge to outcomes with poor global welfare.