 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Subgoal-driven Framework for Improving Long-Horizon LLM Agents
Mar 20, 2026Large language model (LLM)-based agents have emerged as powerful autonomous controllers for digital environments, including mobile interfaces, operating systems, and web browsers. Web navigation, for example, requires handling dynamic content and long sequences of actions, making it particularly challenging. Existing LLM-based agents struggle with long-horizon planning in two main ways. During online execution, they often lose track as new information arrives, lacking a clear and adaptive path toward the final goal. This issue is further exacerbated during reinforcement learning (RL) fine-tuning, where sparse and delayed rewards make it difficult for agents to identify which actions lead to success, preventing them from maintaining coherent reasoning over extended tasks. To address these challenges, we propose two contributions. First, we introduce an agent framework that leverages proprietary models for online planning through subgoal decomposition. Second, we present MiRA (Milestoning your Reinforcement Learning Enhanced Agent), an RL training framework that uses dense, milestone-based reward signals. The real-time planning mechanism improves proprietary models such as Gemini by approximately a 10% absolute increase in success rate (SR) on the WebArena-Lite benchmark. Meanwhile, applying MiRA to the open Gemma3-12B model increases its success rate from 6.4% to 43.0%. This performance surpasses proprietary systems such as GPT-4-Turbo (17.6%) and GPT-4o (13.9%), as well as the previous open-model state of the art, WebRL (38.4%). Overall, our findings demonstrate that combining explicit inference-time planning with milestone-based rewards significantly improves an agent's long-horizon capabilities, paving the way for more robust and general-purpose autonomous systems.
Learning to Learn from Language Feedback with Social Meta-Learning
Feb 18, 2026Large language models (LLMs) often struggle to learn from corrective feedback within a conversational context. They are rarely proactive in soliciting this feedback, even when faced with ambiguity, which can make their dialogues feel static, one-sided, and lacking the adaptive qualities of human conversation. To address these limitations, we draw inspiration from social meta-learning (SML) in humans - the process of learning how to learn from others. We formulate SML as a finetuning methodology, training LLMs to solicit and learn from language feedback in simulated pedagogical dialogues, where static tasks are converted into interactive social learning problems. SML effectively teaches models to use conversation to solve problems they are unable to solve in a single turn. This capability generalises across domains; SML on math problems produces models that better use feedback to solve coding problems and vice versa. Furthermore, despite being trained only on fully-specified problems, these models are better able to solve underspecified tasks where critical information is revealed over multiple turns. When faced with this ambiguity, SML-trained models make fewer premature answer attempts and are more likely to ask for the information they need. This work presents a scalable approach to developing AI systems that effectively learn from language feedback.
Improving Interactive In-Context Learning from Natural Language Feedback
Feb 17, 2026Adapting one's thought process based on corrective feedback is an essential ability in human learning, particularly in collaborative settings. In contrast, the current large language model training paradigm relies heavily on modeling vast, static corpora. While effective for knowledge acquisition, it overlooks the interactive feedback loops essential for models to adapt dynamically to their context. In this work, we propose a framework that treats this interactive in-context learning ability not as an emergent property, but as a distinct, trainable skill. We introduce a scalable method that transforms single-turn verifiable tasks into multi-turn didactic interactions driven by information asymmetry. We first show that current flagship models struggle to integrate corrective feedback on hard reasoning tasks. We then demonstrate that models trained with our approach dramatically improve the ability to interactively learn from language feedback. More specifically, the multi-turn performance of a smaller model nearly reaches that of a model an order of magnitude larger. We also observe robust out-of-distribution generalization: interactive training on math problems transfers to diverse domains like coding, puzzles and maze navigation. Our qualitative analysis suggests that this improvement is due to an enhanced in-context plasticity. Finally, we show that this paradigm offers a unified path to self-improvement. By training the model to predict the teacher's critiques, effectively modeling the feedback environment, we convert this external signal into an internal capability, allowing the model to self-correct even without a teacher.
Infusion: Shaping Model Behavior by Editing Training Data via Influence Functions
Feb 11, 2026Influence functions are commonly used to attribute model behavior to training documents. We explore the reverse: crafting training data that induces model behavior. Our framework, Infusion, uses scalable influence-function approximations to compute small perturbations to training documents that induce targeted changes in model behavior through parameter shifts. We evaluate Infusion on data poisoning tasks across vision and language domains. On CIFAR-10, we show that making subtle edits via Infusion to just 0.2% (100/45,000) of the training documents can be competitive with the baseline of inserting a small number of explicit behavior examples. We also find that Infusion transfers across architectures (ResNet $\leftrightarrow$ CNN), suggesting a single poisoned corpus can affect multiple independently trained models. In preliminary language experiments, we characterize when our approach increases the probability of target behaviors and when it fails, finding it most effective at amplifying behaviors the model has already learned. Taken together, these results show that small, subtle edits to training data can systematically shape model behavior, underscoring the importance of training data interpretability for adversaries and defenders alike. We provide the code here: https://github.com/jrosseruk/infusion.
Interaction Dynamics as a Reward Signal for LLMs
Nov 11, 2025The alignment of Large Language Models (LLMs) for multi-turn conversations typically relies on reward signals derived from the content of the text. This approach, however, overlooks a rich, complementary source of signal: the dynamics of the interaction itself. This paper introduces TRACE (Trajectory-based Reward for Agent Collaboration Estimation), a novel reward signal derived from the geometric properties of a dialogue's embedding trajectory--a concept we term 'conversational geometry'. Our central finding is that a reward model trained only on these structural signals achieves a pairwise accuracy (68.20%) comparable to a powerful LLM baseline that analyzes the full transcript (70.04%). Furthermore, a hybrid model combining interaction dynamics with textual analysis achieves the highest performance (80.17%), demonstrating their complementary nature. This work provides strong evidence that for interactive settings, how an agent communicates is as powerful a predictor of success as what it says, offering a new, privacy-preserving framework that not only aligns agents but also serves as a diagnostic tool for understanding the distinct interaction patterns that drive successful collaboration.
Generative Data Refinement: Just Ask for Better Data
Sep 10, 2025



For a fixed parameter size, the capabilities of large models are primarily determined by the quality and quantity of its training data. Consequently, training datasets now grow faster than the rate at which new data is indexed on the web, leading to projected data exhaustion over the next decade. Much more data exists as user-generated content that is not publicly indexed, but incorporating such data comes with considerable risks, such as leaking private information and other undesirable content. We introduce a framework, Generative Data Refinement (GDR), for using pretrained generative models to transform a dataset with undesirable content into a refined dataset that is more suitable for training. Our experiments show that GDR can outperform industry-grade solutions for dataset anonymization, as well as enable direct detoxification of highly unsafe datasets. Moreover, we show that by generating synthetic data that is conditioned on each example in the real dataset, GDR's refined outputs naturally match the diversity of web scale datasets, and thereby avoid the often challenging task of generating diverse synthetic data via model prompting. The simplicity and effectiveness of GDR make it a powerful tool for scaling up the total stock of training data for frontier models.
Learning When to Plan: Efficiently Allocating Test-Time Compute for LLM Agents
Sep 03, 2025



Training large language models (LLMs) to reason via reinforcement learning (RL) significantly improves their problem-solving capabilities. In agentic settings, existing methods like ReAct prompt LLMs to explicitly plan before every action; however, we demonstrate that always planning is computationally expensive and degrades performance on long-horizon tasks, while never planning further limits performance. To address this, we introduce a conceptual framework formalizing dynamic planning for LLM agents, enabling them to flexibly decide when to allocate test-time compute for planning. We propose a simple two-stage training pipeline: (1) supervised fine-tuning on diverse synthetic data to prime models for dynamic planning, and (2) RL to refine this capability in long-horizon environments. Experiments on the Crafter environment show that dynamic planning agents trained with this approach are more sample-efficient and consistently achieve more complex objectives. Additionally, we demonstrate that these agents can be effectively steered by human-written plans, surpassing their independent capabilities. To our knowledge, this work is the first to explore training LLM agents for dynamic test-time compute allocation in sequential decision-making tasks, paving the way for more efficient, adaptive, and controllable agentic systems.
Writing as a testbed for open ended agents
Mar 25, 2025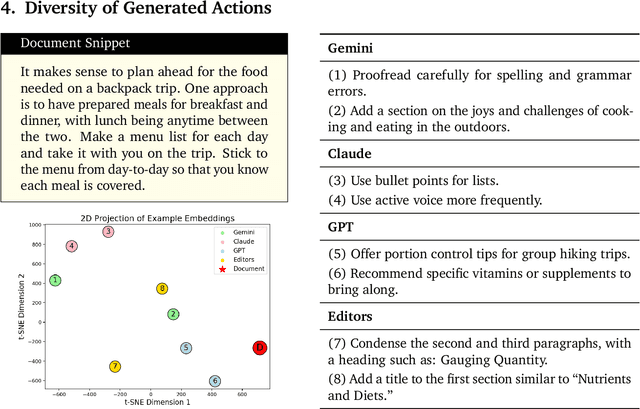

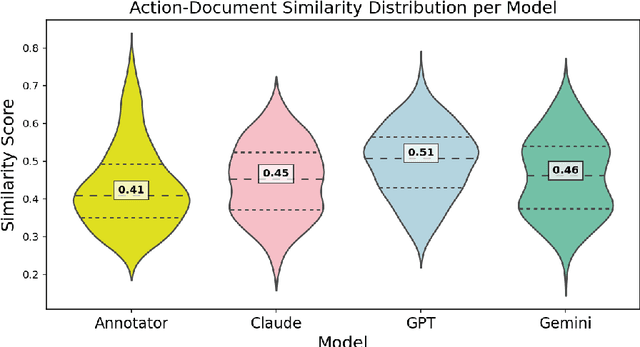

Open-ended tasks are particularly challenging for LLMs due to the vast solution space, demanding both expansive exploration and adaptable strategies, especially when success lacks a clear, objective definition. Writing, with its vast solution space and subjective evaluation criteria, provides a compelling testbed for studying such problems. In this paper, we investigate the potential of LLMs to act as collaborative co-writers, capable of suggesting and implementing text improvements autonomously. We analyse three prominent LLMs - Gemini 1.5 Pro, Claude 3.5 Sonnet, and GPT-4o - focusing on how their action diversity, human alignment, and iterative improvement capabilities impact overall performance. This work establishes a framework for benchmarking autonomous writing agents and, more broadly, highlights fundamental challenges and potential solutions for building systems capable of excelling in diverse open-ended domains.
Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models
Nov 19, 2024



The capabilities and limitations of Large Language Models have been sketched out in great detail in recent years, providing an intriguing yet conflicting picture. On the one hand, LLMs demonstrate a general ability to solve problems. On the other hand, they show surprising reasoning gaps when compared to humans, casting doubt on the robustness of their generalisation strategies. The sheer volume of data used in the design of LLMs has precluded us from applying the method traditionally used to measure generalisation: train-test set separation. To overcome this, we study what kind of generalisation strategies LLMs employ when performing reasoning tasks by investigating the pretraining data they rely on. For two models of different sizes (7B and 35B) and 2.5B of their pretraining tokens, we identify what documents influence the model outputs for three simple mathematical reasoning tasks and contrast this to the data that are influential for answering factual questions. We find that, while the models rely on mostly distinct sets of data for each factual question, a document often has a similar influence across different reasoning questions within the same task, indicating the presence of procedural knowledge. We further find that the answers to factual questions often show up in the most influential data. However, for reasoning questions the answers usually do not show up as highly influential, nor do the answers to the intermediate reasoning steps. When we characterise the top ranked documents for the reasoning questions qualitatively, we confirm that the influential documents often contain procedural knowledge, like demonstrating how to obtain a solution using formulae or code. Our findings indicate that the approach to reasoning the models use is unlike retrieval, and more like a generalisable strategy that synthesises procedural knowledge from documents doing a similar form of reasoning.
Debating with More Persuasive LLMs Leads to More Truthful Answers
Feb 15, 2024Common methods for aligning large language models (LLMs) with desired behaviour heavily rely on human-labelled data. However, as models grow increasingly sophisticated, they will surpass human expertise, and the role of human evaluation will evolve into non-experts overseeing experts. In anticipation of this, we ask: can weaker models assess the correctness of stronger models? We investigate this question in an analogous setting, where stronger models (experts) possess the necessary information to answer questions and weaker models (non-experts) lack this information. The method we evaluate is \textit{debate}, where two LLM experts each argue for a different answer, and a non-expert selects the answer. We find that debate consistently helps both non-expert models and humans answer questions, achieving 76\% and 88\% accuracy respectively (naive baselines obtain 48\% and 60\%). Furthermore, optimising expert debaters for persuasiveness in an unsupervised manner improves non-expert ability to identify the truth in debates. Our results provide encouraging empirical evidence for the viability of aligning models with debate in the absence of ground truth.