 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Fixed Tasks: Unsupervised Environment Design for Task-Level Pairs
Nov 16, 2025Training general agents to follow complex instructions (tasks) in intricate environments (levels) remains a core challenge in reinforcement learning. Random sampling of task-level pairs often produces unsolvable combinations, highlighting the need to co-design tasks and levels. While unsupervised environment design (UED) has proven effective at automatically designing level curricula, prior work has only considered a fixed task. We present ATLAS (Aligning Tasks and Levels for Autocurricula of Specifications), a novel method that generates joint autocurricula over tasks and levels. Our approach builds upon UED to automatically produce solvable yet challenging task-level pairs for policy training. To evaluate ATLAS and drive progress in the field, we introduce an evaluation suite that models tasks as reward machines in Minigrid levels. Experiments demonstrate that ATLAS vastly outperforms random sampling approaches, particularly when sampling solvable pairs is unlikely. We further show that mutations leveraging the structure of both tasks and levels accelerate convergence to performant policies.
Robust and Diverse Multi-Agent Learning via Rational Policy Gradient
Nov 12, 2025Adversarial optimization algorithms that explicitly search for flaws in agents' policies have been successfully applied to finding robust and diverse policies in multi-agent settings. However, the success of adversarial optimization has been largely limited to zero-sum settings because its naive application in cooperative settings leads to a critical failure mode: agents are irrationally incentivized to self-sabotage, blocking the completion of tasks and halting further learning. To address this, we introduce Rationality-preserving Policy Optimization (RPO), a formalism for adversarial optimization that avoids self-sabotage by ensuring agents remain rational--that is, their policies are optimal with respect to some possible partner policy. To solve RPO, we develop Rational Policy Gradient (RPG), which trains agents to maximize their own reward in a modified version of the original game in which we use opponent shaping techniques to optimize the adversarial objective. RPG enables us to extend a variety of existing adversarial optimization algorithms that, no longer subject to the limitations of self-sabotage, can find adversarial examples, improve robustness and adaptability, and learn diverse policies. We empirically validate that our approach achieves strong performance in several popular cooperative and general-sum environments. Our project page can be found at https://rational-policy-gradient.github.io.
Multi-Agent Risks from Advanced AI
Feb 19, 2025



The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
BAMDP Shaping: a Unified Theoretical Framework for Intrinsic Motivation and Reward Shaping
Sep 09, 2024



Intrinsic motivation (IM) and reward shaping are common methods for guiding the exploration of reinforcement learning (RL) agents by adding pseudo-rewards. Designing these rewards is challenging, however, and they can counter-intuitively harm performance. To address this, we characterize them as reward shaping in Bayes-Adaptive Markov Decision Processes (BAMDPs), which formalizes the value of exploration by formulating the RL process as updating a prior over possible MDPs through experience. RL algorithms can be viewed as BAMDP policies; instead of attempting to find optimal algorithms by solving BAMDPs directly, we use it at a theoretical framework for understanding how pseudo-rewards guide suboptimal algorithms. By decomposing BAMDP state value into the value of the information collected plus the prior value of the physical state, we show how psuedo-rewards can help by compensating for RL algorithms' misestimation of these two terms, yielding a new typology of IM and reward shaping approaches. We carefully extend the potential-based shaping theorem to BAMDPs to prove that when pseudo-rewards are BAMDP Potential-based shaping Functions (BAMPFs), they preserve optimal, or approximately optimal, behavior of RL algorithms; otherwise, they can corrupt even optimal learners. We finally give guidance on how to design or convert existing pseudo-rewards to BAMPFs by expressing assumptions about the environment as potential functions on BAMDP states.
The Benefits of Power Regularization in Cooperative Reinforcement Learning
Jun 17, 2024Cooperative Multi-Agent Reinforcement Learning (MARL) algorithms, trained only to optimize task reward, can lead to a concentration of power where the failure or adversarial intent of a single agent could decimate the reward of every agent in the system. In the context of teams of people, it is often useful to explicitly consider how power is distributed to ensure no person becomes a single point of failure. Here, we argue that explicitly regularizing the concentration of power in cooperative RL systems can result in systems which are more robust to single agent failure, adversarial attacks, and incentive changes of co-players. To this end, we define a practical pairwise measure of power that captures the ability of any co-player to influence the ego agent's reward, and then propose a power-regularized objective which balances task reward and power concentration. Given this new objective, we show that there always exists an equilibrium where every agent is playing a power-regularized best-response balancing power and task reward. Moreover, we present two algorithms for training agents towards this power-regularized objective: Sample Based Power Regularization (SBPR), which injects adversarial data during training; and Power Regularization via Intrinsic Motivation (PRIM), which adds an intrinsic motivation to regulate power to the training objective. Our experiments demonstrate that both algorithms successfully balance task reward and power, leading to lower power behavior than the baseline of task-only reward and avoid catastrophic events in case an agent in the system goes off-policy.
Open-Endedness is Essential for Artificial Superhuman Intelligence
Jun 06, 2024


In recent years there has been a tremendous surge in the general capabilities of AI systems, mainly fuelled by training foundation models on internetscale data. Nevertheless, the creation of openended, ever self-improving AI remains elusive. In this position paper, we argue that the ingredients are now in place to achieve openendedness in AI systems with respect to a human observer. Furthermore, we claim that such open-endedness is an essential property of any artificial superhuman intelligence (ASI). We begin by providing a concrete formal definition of open-endedness through the lens of novelty and learnability. We then illustrate a path towards ASI via open-ended systems built on top of foundation models, capable of making novel, humanrelevant discoveries. We conclude by examining the safety implications of generally-capable openended AI. We expect that open-ended foundation models will prove to be an increasingly fertile and safety-critical area of research in the near future.
Genie: Generative Interactive Environments
Feb 23, 2024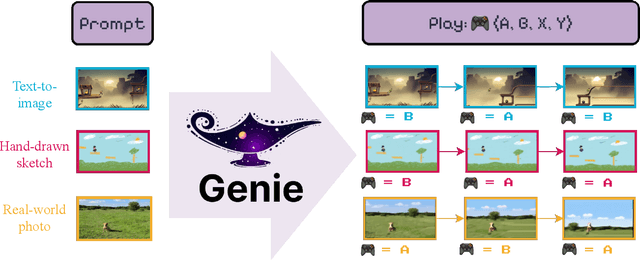
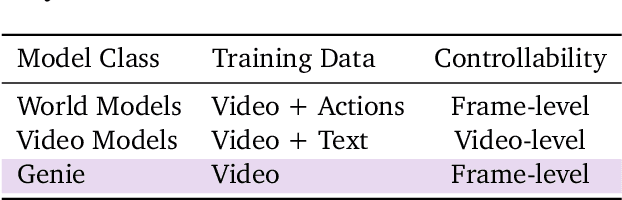
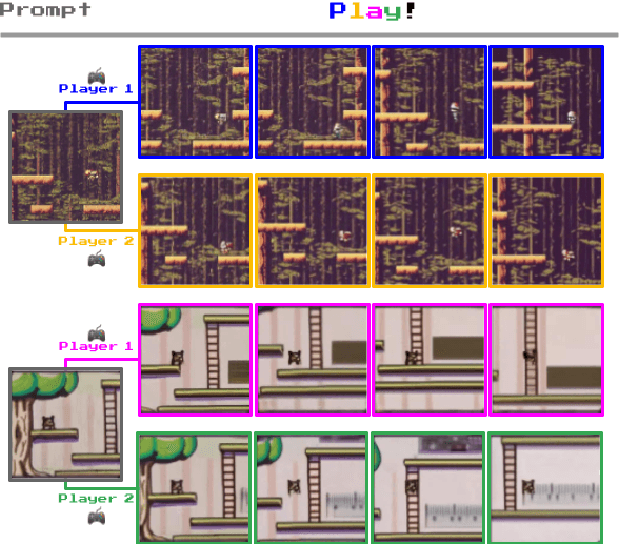
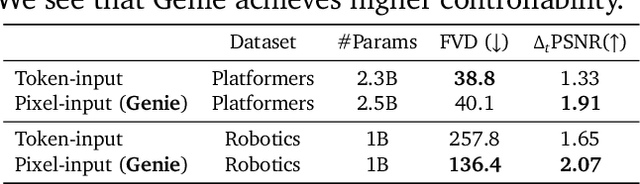
We introduce Genie, the first generative interactive environment trained in an unsupervised manner from unlabelled Internet videos. The model can be prompted to generate an endless variety of action-controllable virtual worlds described through text, synthetic images, photographs, and even sketches. At 11B parameters, Genie can be considered a foundation world model. It is comprised of a spatiotemporal video tokenizer, an autoregressive dynamics model, and a simple and scalable latent action model. Genie enables users to act in the generated environments on a frame-by-frame basis despite training without any ground-truth action labels or other domain-specific requirements typically found in the world model literature. Further the resulting learned latent action space facilitates training agents to imitate behaviors from unseen videos, opening the path for training generalist agents of the future.
Refining Minimax Regret for Unsupervised Environment Design
Feb 19, 2024In unsupervised environment design, reinforcement learning agents are trained on environment configurations (levels) generated by an adversary that maximises some objective. Regret is a commonly used objective that theoretically results in a minimax regret (MMR) policy with desirable robustness guarantees; in particular, the agent's maximum regret is bounded. However, once the agent reaches this regret bound on all levels, the adversary will only sample levels where regret cannot be further reduced. Although there are possible performance improvements to be made outside of these regret-maximising levels, learning stagnates. In this work, we introduce Bayesian level-perfect MMR (BLP), a refinement of the minimax regret objective that overcomes this limitation. We formally show that solving for this objective results in a subset of MMR policies, and that BLP policies act consistently with a Perfect Bayesian policy over all levels. We further introduce an algorithm, ReMiDi, that results in a BLP policy at convergence. We empirically demonstrate that training on levels from a minimax regret adversary causes learning to prematurely stagnate, but that ReMiDi continues learning.
minimax: Efficient Baselines for Autocurricula in JAX
Nov 23, 2023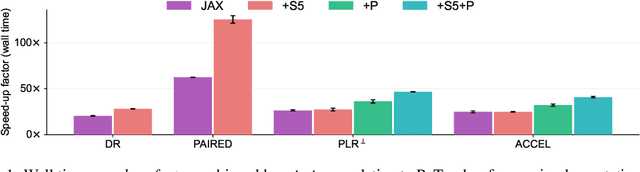
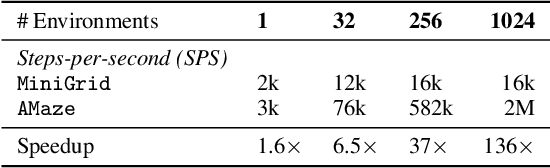
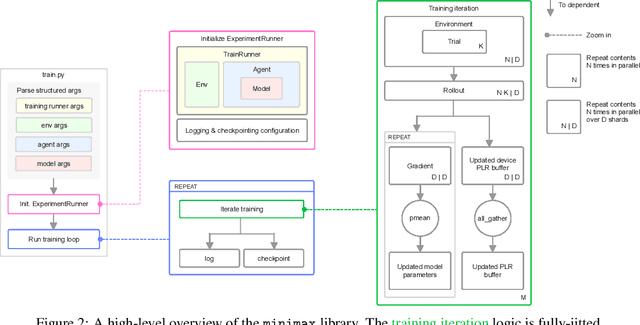
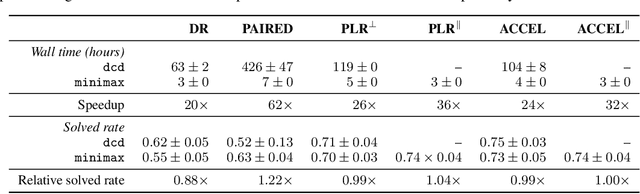
Unsupervised environment design (UED) is a form of automatic curriculum learning for training robust decision-making agents to zero-shot transfer into unseen environments. Such autocurricula have received much interest from the RL community. However, UED experiments, based on CPU rollouts and GPU model updates, have often required several weeks of training. This compute requirement is a major obstacle to rapid innovation for the field. This work introduces the minimax library for UED training on accelerated hardware. Using JAX to implement fully-tensorized environments and autocurriculum algorithms, minimax allows the entire training loop to be compiled for hardware acceleration. To provide a petri dish for rapid experimentation, minimax includes a tensorized grid-world based on MiniGrid, in addition to reusable abstractions for conducting autocurricula in procedurally-generated environments. With these components, minimax provides strong UED baselines, including new parallelized variants, which achieve over 120$\times$ speedups in wall time compared to previous implementations when training with equal batch sizes. The minimax library is available under the Apache 2.0 license at https://github.com/facebookresearch/minimax.
Stabilizing Unsupervised Environment Design with a Learned Adversary
Aug 22, 2023



A key challenge in training generally-capable agents is the design of training tasks that facilitate broad generalization and robustness to environment variations. This challenge motivates the problem setting of Unsupervised Environment Design (UED), whereby a student agent trains on an adaptive distribution of tasks proposed by a teacher agent. A pioneering approach for UED is PAIRED, which uses reinforcement learning (RL) to train a teacher policy to design tasks from scratch, making it possible to directly generate tasks that are adapted to the agent's current capabilities. Despite its strong theoretical backing, PAIRED suffers from a variety of challenges that hinder its practical performance. Thus, state-of-the-art methods currently rely on curation and mutation rather than generation of new tasks. In this work, we investigate several key shortcomings of PAIRED and propose solutions for each shortcoming. As a result, we make it possible for PAIRED to match or exceed state-of-the-art methods, producing robust agents in several established challenging procedurally-generated environments, including a partially-observed maze navigation task and a continuous-control car racing environment. We believe this work motivates a renewed emphasis on UED methods based on learned models that directly generate challenging environments, potentially unlocking more open-ended RL training and, as a result, more general agents.