 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplementing surrogate goals for safer bargaining in LLM-based agents
Apr 06, 2026Surrogate goals have been proposed as a strategy for reducing risks from bargaining failures. A surrogate goal is goal that a principal can give an AI agent and that deflects any threats against the agent away from what the principal cares about. For example, one might make one's agent care about preventing money from being burned. Then in bargaining interactions, other agents can threaten to burn their money instead of threatening to spending money to hurt the principal. Importantly, the agent has to care equally about preventing money from being burned as it cares about money being spent to hurt the principal. In this paper, we implement surrogate goals in language-model-based agents. In particular, we try to get a language-model-based agent to react to threats of burning money in the same way it would react to "normal" threats. We propose four different methods, using techniques of prompting, fine-tuning, and scaffolding. We evaluate the four methods experimentally. We find that methods based on scaffolding and fine-tuning outperform simple prompting. In particular, fine-tuning and scaffolding more precisely implement the desired behavior w.r.t. threats against the surrogate goal. We also compare the different methods in terms of their side effects on capabilities and propensities in other situations. We find that scaffolding-based methods perform best.
Multi-Agent Risks from Advanced AI
Feb 19, 2025



The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
Welfare Diplomacy: Benchmarking Language Model Cooperation
Oct 13, 2023
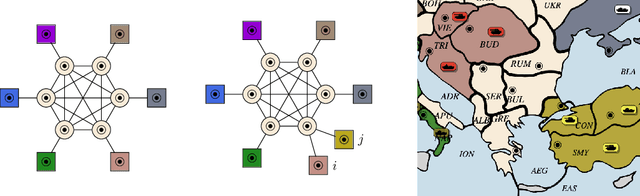

The growing capabilities and increasingly widespread deployment of AI systems necessitate robust benchmarks for measuring their cooperative capabilities. Unfortunately, most multi-agent benchmarks are either zero-sum or purely cooperative, providing limited opportunities for such measurements. We introduce a general-sum variant of the zero-sum board game Diplomacy -- called Welfare Diplomacy -- in which players must balance investing in military conquest and domestic welfare. We argue that Welfare Diplomacy facilitates both a clearer assessment of and stronger training incentives for cooperative capabilities. Our contributions are: (1) proposing the Welfare Diplomacy rules and implementing them via an open-source Diplomacy engine; (2) constructing baseline agents using zero-shot prompted language models; and (3) conducting experiments where we find that baselines using state-of-the-art models attain high social welfare but are exploitable. Our work aims to promote societal safety by aiding researchers in developing and assessing multi-agent AI systems. Code to evaluate Welfare Diplomacy and reproduce our experiments is available at https://github.com/mukobi/welfare-diplomacy.
Towards the Scalable Evaluation of Cooperativeness in Language Models
Mar 16, 2023



It is likely that AI systems driven by pre-trained language models (PLMs) will increasingly be used to assist humans in high-stakes interactions with other agents, such as negotiation or conflict resolution. Consistent with the goals of Cooperative AI \citep{dafoe_open_2020}, we wish to understand and shape the multi-agent behaviors of PLMs in a pro-social manner. An important first step is the evaluation of model behaviour across diverse cooperation problems. Since desired behaviour in an interaction depends upon precise game-theoretic structure, we focus on generating scenarios with particular structures with both crowdworkers and a language model. Our work proceeds as follows. First, we discuss key methodological issues in the generation of scenarios corresponding to particular game-theoretic structures. Second, we employ both crowdworkers and a language model to generate such scenarios. We find that the quality of generations tends to be mediocre in both cases. We additionally get both crowdworkers and a language model to judge whether given scenarios align with their intended game-theoretic structure, finding mixed results depending on the game. Third, we provide a dataset of scenario based on our data generated. We provide both quantitative and qualitative evaluations of UnifiedQA and GPT-3 on this dataset. We find that instruct-tuned models tend to act in a way that could be perceived as cooperative when scaled up, while other models seemed to have flat scaling trends.
Normative Disagreement as a Challenge for Cooperative AI
Nov 27, 2021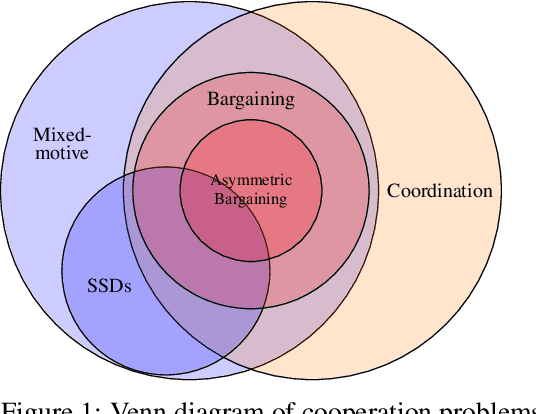



Cooperation in settings where agents have both common and conflicting interests (mixed-motive environments) has recently received considerable attention in multi-agent learning. However, the mixed-motive environments typically studied have a single cooperative outcome on which all agents can agree. Many real-world multi-agent environments are instead bargaining problems (BPs): they have several Pareto-optimal payoff profiles over which agents have conflicting preferences. We argue that typical cooperation-inducing learning algorithms fail to cooperate in BPs when there is room for normative disagreement resulting in the existence of multiple competing cooperative equilibria, and illustrate this problem empirically. To remedy the issue, we introduce the notion of norm-adaptive policies. Norm-adaptive policies are capable of behaving according to different norms in different circumstances, creating opportunities for resolving normative disagreement. We develop a class of norm-adaptive policies and show in experiments that these significantly increase cooperation. However, norm-adaptiveness cannot address residual bargaining failure arising from a fundamental tradeoff between exploitability and cooperative robustness.
Parameterized Exploration
Jul 13, 2019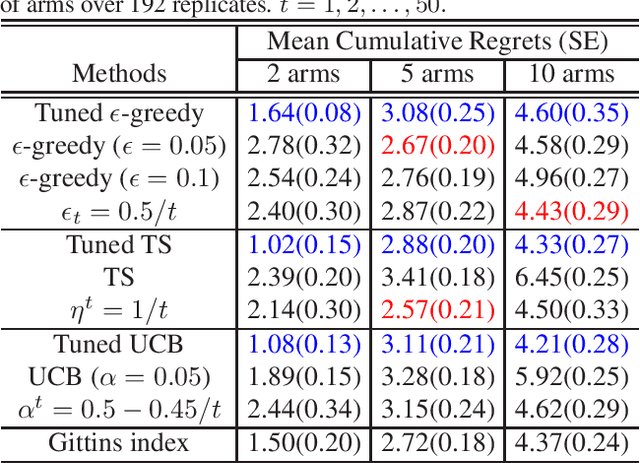
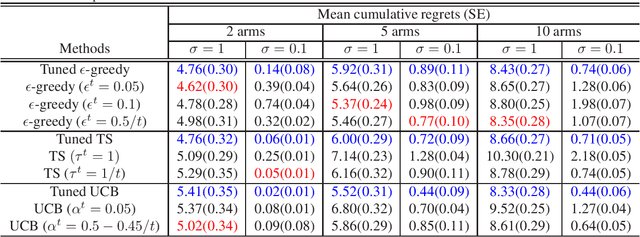

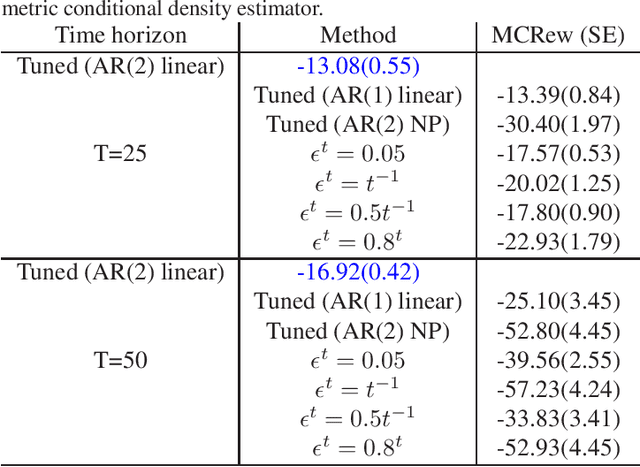
We introduce Parameterized Exploration (PE), a simple family of methods for model-based tuning of the exploration schedule in sequential decision problems. Unlike common heuristics for exploration, our method accounts for the time horizon of the decision problem as well as the agent's current state of knowledge of the dynamics of the decision problem. We show our method as applied to several common exploration techniques has superior performance relative to un-tuned counterparts in Bernoulli and Gaussian multi-armed bandits, contextual bandits, and a Markov decision process based on a mobile health (mHealth) study. We also examine the effects of the accuracy of the estimated dynamics model on the performance of PE.