 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitation Learning for Multi-turn LM Agents via On-policy Expert Corrections
Dec 16, 2025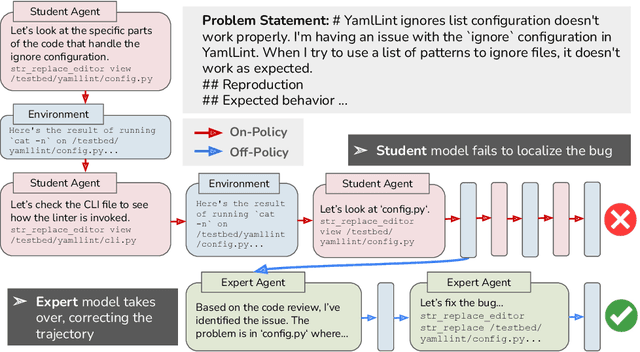
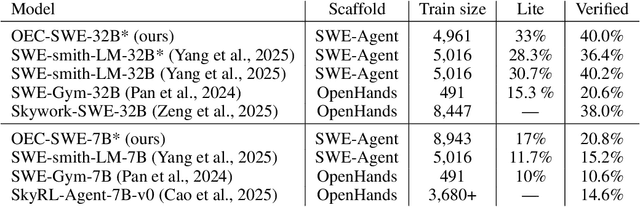
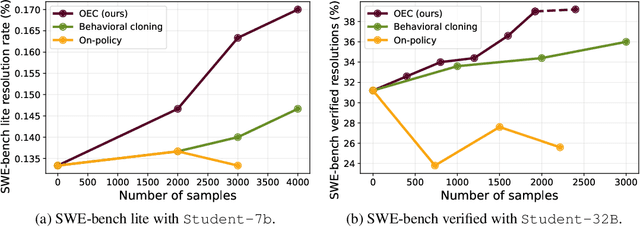

A popular paradigm for training LM agents relies on imitation learning, fine-tuning on expert trajectories. However, we show that the off-policy nature of imitation learning for multi-turn LM agents suffers from the fundamental limitation known as covariate shift: as the student policy's behavior diverges from the expert's, it encounters states not present in the training data, reducing the effectiveness of fine-tuning. Taking inspiration from the classic DAgger algorithm, we propose a novel data generation methodology for addressing covariate shift for multi-turn LLM training. We introduce on-policy expert corrections (OECs), partially on-policy data generated by starting rollouts with a student model and then switching to an expert model part way through the trajectory. We explore the effectiveness of our data generation technique in the domain of software engineering (SWE) tasks, a multi-turn setting where LLM agents must interact with a development environment to fix software bugs. Our experiments compare OEC data against various other on-policy and imitation learning approaches on SWE agent problems and train models using a common rejection sampling (i.e., using environment reward) combined with supervised fine-tuning technique. Experiments find that OEC trajectories show a relative 14% and 13% improvement over traditional imitation learning in the 7b and 32b setting, respectively, on SWE-bench verified. Our results demonstrate the need for combining expert demonstrations with on-policy data for effective multi-turn LM agent training.
Robust and Diverse Multi-Agent Learning via Rational Policy Gradient
Nov 12, 2025Adversarial optimization algorithms that explicitly search for flaws in agents' policies have been successfully applied to finding robust and diverse policies in multi-agent settings. However, the success of adversarial optimization has been largely limited to zero-sum settings because its naive application in cooperative settings leads to a critical failure mode: agents are irrationally incentivized to self-sabotage, blocking the completion of tasks and halting further learning. To address this, we introduce Rationality-preserving Policy Optimization (RPO), a formalism for adversarial optimization that avoids self-sabotage by ensuring agents remain rational--that is, their policies are optimal with respect to some possible partner policy. To solve RPO, we develop Rational Policy Gradient (RPG), which trains agents to maximize their own reward in a modified version of the original game in which we use opponent shaping techniques to optimize the adversarial objective. RPG enables us to extend a variety of existing adversarial optimization algorithms that, no longer subject to the limitations of self-sabotage, can find adversarial examples, improve robustness and adaptability, and learn diverse policies. We empirically validate that our approach achieves strong performance in several popular cooperative and general-sum environments. Our project page can be found at https://rational-policy-gradient.github.io.
Provably Correct Automata Embeddings for Optimal Automata-Conditioned Reinforcement Learning
Mar 06, 2025Automata-conditioned reinforcement learning (RL) has given promising results for learning multi-task policies capable of performing temporally extended objectives given at runtime, done by pretraining and freezing automata embeddings prior to training the downstream policy. However, no theoretical guarantees were given. This work provides a theoretical framework for the automata-conditioned RL problem and shows that it is probably approximately correct learnable. We then present a technique for learning provably correct automata embeddings, guaranteeing optimal multi-task policy learning. Our experimental evaluation confirms these theoretical results.
Multi-Agent Risks from Advanced AI
Feb 19, 2025



The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
Learning Symbolic Task Decompositions for Multi-Agent Teams
Feb 19, 2025



One approach for improving sample efficiency in cooperative multi-agent learning is to decompose overall tasks into sub-tasks that can be assigned to individual agents. We study this problem in the context of reward machines: symbolic tasks that can be formally decomposed into sub-tasks. In order to handle settings without a priori knowledge of the environment, we introduce a framework that can learn the optimal decomposition from model-free interactions with the environment. Our method uses a task-conditioned architecture to simultaneously learn an optimal decomposition and the corresponding agents' policies for each sub-task. In doing so, we remove the need for a human to manually design the optimal decomposition while maintaining the sample-efficiency benefits of improved credit assignment. We provide experimental results in several deep reinforcement learning settings, demonstrating the efficacy of our approach. Our results indicate that our approach succeeds even in environments with codependent agent dynamics, enabling synchronous multi-agent learning not achievable in previous works.
Compositional Automata Embeddings for Goal-Conditioned Reinforcement Learning
Oct 31, 2024
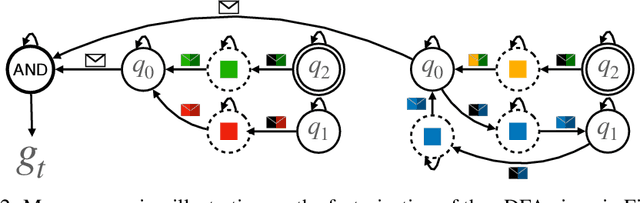
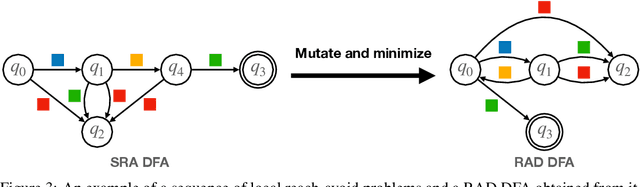
Goal-conditioned reinforcement learning is a powerful way to control an AI agent's behavior at runtime. That said, popular goal representations, e.g., target states or natural language, are either limited to Markovian tasks or rely on ambiguous task semantics. We propose representing temporal goals using compositions of deterministic finite automata (cDFAs) and use cDFAs to guide RL agents. cDFAs balance the need for formal temporal semantics with ease of interpretation: if one can understand a flow chart, one can understand a cDFA. On the other hand, cDFAs form a countably infinite concept class with Boolean semantics, and subtle changes to the automaton can result in very different tasks, making them difficult to condition agent behavior on. To address this, we observe that all paths through a DFA correspond to a series of reach-avoid tasks and propose pre-training graph neural network embeddings on "reach-avoid derived" DFAs. Through empirical evaluation, we demonstrate that the proposed pre-training method enables zero-shot generalization to various cDFA task classes and accelerated policy specialization without the myopic suboptimality of hierarchical methods.
Welfare Diplomacy: Benchmarking Language Model Cooperation
Oct 13, 2023
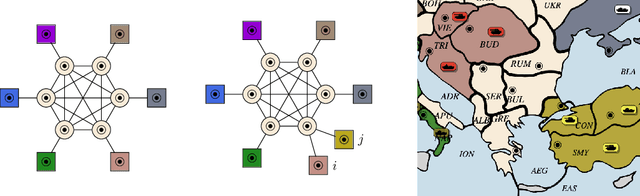

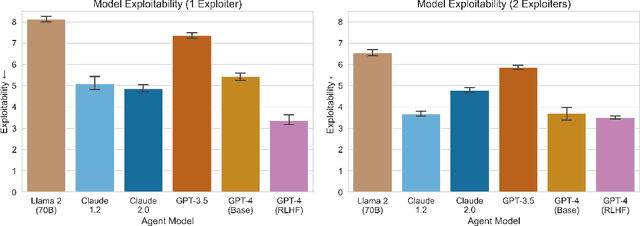
The growing capabilities and increasingly widespread deployment of AI systems necessitate robust benchmarks for measuring their cooperative capabilities. Unfortunately, most multi-agent benchmarks are either zero-sum or purely cooperative, providing limited opportunities for such measurements. We introduce a general-sum variant of the zero-sum board game Diplomacy -- called Welfare Diplomacy -- in which players must balance investing in military conquest and domestic welfare. We argue that Welfare Diplomacy facilitates both a clearer assessment of and stronger training incentives for cooperative capabilities. Our contributions are: (1) proposing the Welfare Diplomacy rules and implementing them via an open-source Diplomacy engine; (2) constructing baseline agents using zero-shot prompted language models; and (3) conducting experiments where we find that baselines using state-of-the-art models attain high social welfare but are exploitable. Our work aims to promote societal safety by aiding researchers in developing and assessing multi-agent AI systems. Code to evaluate Welfare Diplomacy and reproduce our experiments is available at https://github.com/mukobi/welfare-diplomacy.
Who Needs to Know? Minimal Knowledge for Optimal Coordination
Jun 15, 2023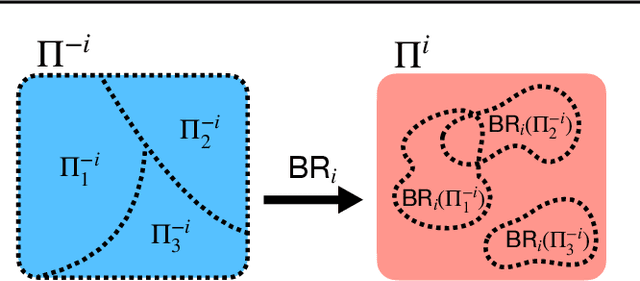
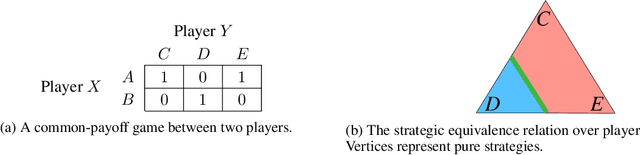
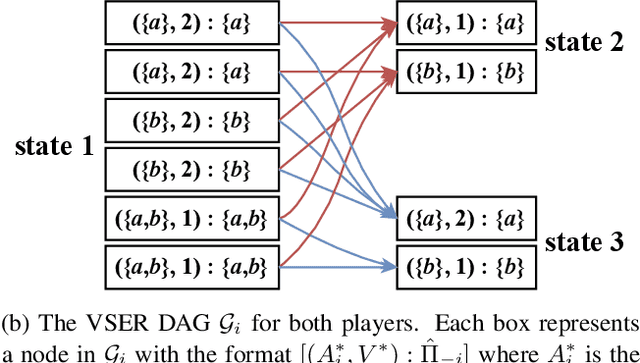
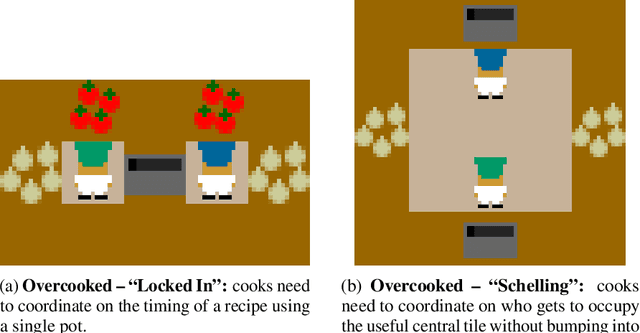
To optimally coordinate with others in cooperative games, it is often crucial to have information about one's collaborators: successful driving requires understanding which side of the road to drive on. However, not every feature of collaborators is strategically relevant: the fine-grained acceleration of drivers may be ignored while maintaining optimal coordination. We show that there is a well-defined dichotomy between strategically relevant and irrelevant information. Moreover, we show that, in dynamic games, this dichotomy has a compact representation that can be efficiently computed via a Bellman backup operator. We apply this algorithm to analyze the strategically relevant information for tasks in both a standard and a partially observable version of the Overcooked environment. Theoretical and empirical results show that our algorithms are significantly more efficient than baselines. Videos are available at https://minknowledge.github.io.
No-Regret Learning in Dynamic Stackelberg Games
Feb 10, 2022



In a Stackelberg game, a leader commits to a randomized strategy, and a follower chooses their best strategy in response. We consider an extension of a standard Stackelberg game, called a discrete-time dynamic Stackelberg game, that has an underlying state space that affects the leader's rewards and available strategies and evolves in a Markovian manner depending on both the leader and follower's selected strategies. Although standard Stackelberg games have been utilized to improve scheduling in security domains, their deployment is often limited by requiring complete information of the follower's utility function. In contrast, we consider scenarios where the follower's utility function is unknown to the leader; however, it can be linearly parameterized. Our objective then is to provide an algorithm that prescribes a randomized strategy to the leader at each step of the game based on observations of how the follower responded in previous steps. We design a no-regret learning algorithm that, with high probability, achieves a regret bound (when compared to the best policy in hindsight) which is sublinear in the number of time steps; the degree of sublinearity depends on the number of features representing the follower's utility function. The regret of the proposed learning algorithm is independent of the size of the state space and polynomial in the rest of the parameters of the game. We show that the proposed learning algorithm outperforms existing model-free reinforcement learning approaches.