 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Diverse Multi-Agent Learning via Rational Policy Gradient
Nov 12, 2025Adversarial optimization algorithms that explicitly search for flaws in agents' policies have been successfully applied to finding robust and diverse policies in multi-agent settings. However, the success of adversarial optimization has been largely limited to zero-sum settings because its naive application in cooperative settings leads to a critical failure mode: agents are irrationally incentivized to self-sabotage, blocking the completion of tasks and halting further learning. To address this, we introduce Rationality-preserving Policy Optimization (RPO), a formalism for adversarial optimization that avoids self-sabotage by ensuring agents remain rational--that is, their policies are optimal with respect to some possible partner policy. To solve RPO, we develop Rational Policy Gradient (RPG), which trains agents to maximize their own reward in a modified version of the original game in which we use opponent shaping techniques to optimize the adversarial objective. RPG enables us to extend a variety of existing adversarial optimization algorithms that, no longer subject to the limitations of self-sabotage, can find adversarial examples, improve robustness and adaptability, and learn diverse policies. We empirically validate that our approach achieves strong performance in several popular cooperative and general-sum environments. Our project page can be found at https://rational-policy-gradient.github.io.
Learning Symbolic Task Decompositions for Multi-Agent Teams
Feb 19, 2025



One approach for improving sample efficiency in cooperative multi-agent learning is to decompose overall tasks into sub-tasks that can be assigned to individual agents. We study this problem in the context of reward machines: symbolic tasks that can be formally decomposed into sub-tasks. In order to handle settings without a priori knowledge of the environment, we introduce a framework that can learn the optimal decomposition from model-free interactions with the environment. Our method uses a task-conditioned architecture to simultaneously learn an optimal decomposition and the corresponding agents' policies for each sub-task. In doing so, we remove the need for a human to manually design the optimal decomposition while maintaining the sample-efficiency benefits of improved credit assignment. We provide experimental results in several deep reinforcement learning settings, demonstrating the efficacy of our approach. Our results indicate that our approach succeeds even in environments with codependent agent dynamics, enabling synchronous multi-agent learning not achievable in previous works.
Deep Policy Optimization with Temporal Logic Constraints
Apr 17, 2024



Temporal logics, such as linear temporal logic (LTL), offer a precise means of specifying tasks for (deep) reinforcement learning (RL) agents. In our work, we consider the setting where the task is specified by an LTL objective and there is an additional scalar reward that we need to optimize. Previous works focus either on learning a LTL task-satisfying policy alone or are restricted to finite state spaces. We make two contributions: First, we introduce an RL-friendly approach to this setting by formulating this problem as a single optimization objective. Our formulation guarantees that an optimal policy will be reward-maximal from the set of policies that maximize the likelihood of satisfying the LTL specification. Second, we address a sparsity issue that often arises for LTL-guided Deep RL policies by introducing Cycle Experience Replay (CyclER), a technique that automatically guides RL agents towards the satisfaction of an LTL specification. Our experiments demonstrate the efficacy of CyclER in finding performant deep RL policies in both continuous and discrete experimental domains.
Learning Formal Specifications from Membership and Preference Queries
Jul 19, 2023

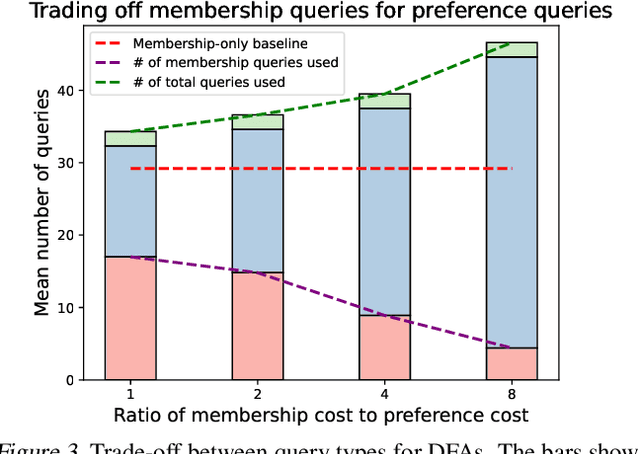

Active learning is a well-studied approach to learning formal specifications, such as automata. In this work, we extend active specification learning by proposing a novel framework that strategically requests a combination of membership labels and pair-wise preferences, a popular alternative to membership labels. The combination of pair-wise preferences and membership labels allows for a more flexible approach to active specification learning, which previously relied on membership labels only. We instantiate our framework in two different domains, demonstrating the generality of our approach. Our results suggest that learning from both modalities allows us to robustly and conveniently identify specifications via membership and preferences.
Who Needs to Know? Minimal Knowledge for Optimal Coordination
Jun 15, 2023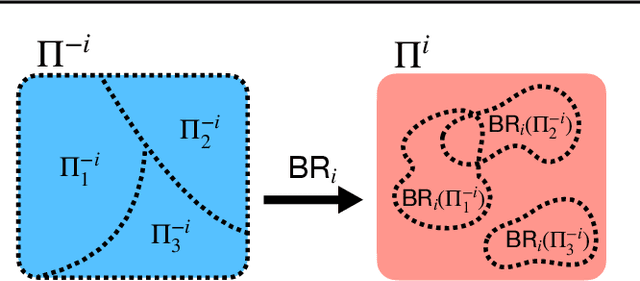
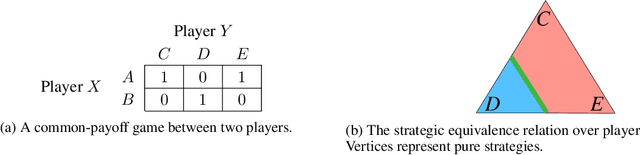
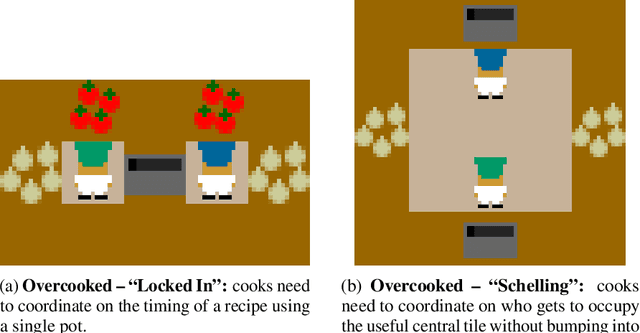
To optimally coordinate with others in cooperative games, it is often crucial to have information about one's collaborators: successful driving requires understanding which side of the road to drive on. However, not every feature of collaborators is strategically relevant: the fine-grained acceleration of drivers may be ignored while maintaining optimal coordination. We show that there is a well-defined dichotomy between strategically relevant and irrelevant information. Moreover, we show that, in dynamic games, this dichotomy has a compact representation that can be efficiently computed via a Bellman backup operator. We apply this algorithm to analyze the strategically relevant information for tasks in both a standard and a partially observable version of the Overcooked environment. Theoretical and empirical results show that our algorithms are significantly more efficient than baselines. Videos are available at https://minknowledge.github.io.
Specification-Guided Data Aggregation for Semantically Aware Imitation Learning
Mar 29, 2023



Advancements in simulation and formal methods-guided environment sampling have enabled the rigorous evaluation of machine learning models in a number of safety-critical scenarios, such as autonomous driving. Application of these environment sampling techniques towards improving the learned models themselves has yet to be fully exploited. In this work, we introduce a novel method for improving imitation-learned models in a semantically aware fashion by leveraging specification-guided sampling techniques as a means of aggregating expert data in new environments. Specifically, we create a set of formal specifications as a means of partitioning the space of possible environments into semantically similar regions, and identify elements of this partition where our learned imitation behaves most differently from the expert. We then aggregate expert data on environments in these identified regions, leading to more accurate imitation of the expert's behavior semantics. We instantiate our approach in a series of experiments in the CARLA driving simulator, and demonstrate that our approach leads to models that are more accurate than those learned with other environment sampling methods.
Demonstration Informed Specification Search
Dec 20, 2021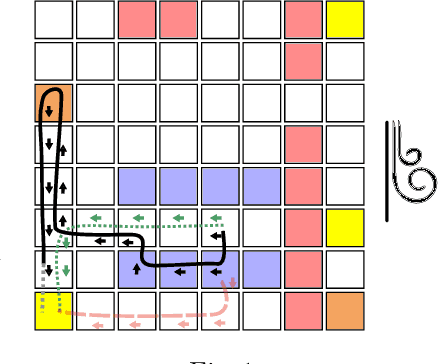
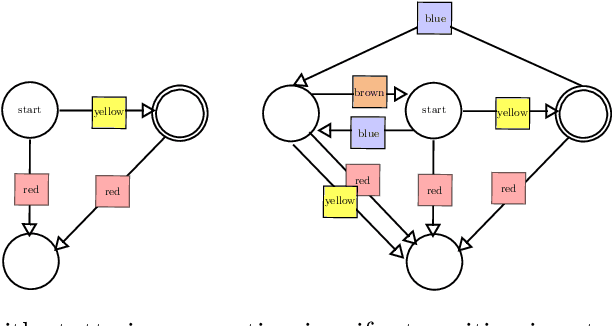
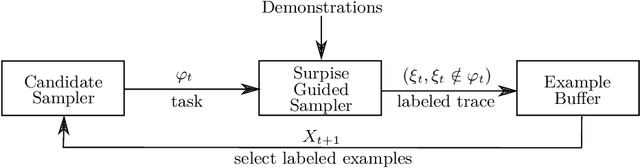
This paper considers the problem of learning history dependent task specifications, e.g. automata and temporal logic, from expert demonstrations. Unfortunately, the (countably infinite) number of tasks under consideration combined with an a-priori ignorance of what historical features are needed to encode the demonstrated task makes existing approaches to learning tasks from demonstrations inapplicable. To address this deficit, we propose Demonstration Informed Specification Search (DISS): a family of algorithms parameterized by black box access to (i) a maximum entropy planner and (ii) an algorithm for identifying concepts, e.g., automata, from labeled examples. DISS works by alternating between (i) conjecturing labeled examples to make the demonstrations less surprising and (ii) sampling concepts consistent with the current labeled examples. In the context of tasks described by deterministic finite automata, we provide a concrete implementation of DISS that efficiently combines partial knowledge of the task and a single expert demonstration to identify the full task specification.
Learning Differentiable Programs with Admissible Neural Heuristics
Jul 26, 2020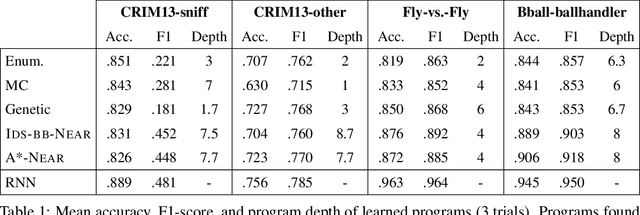
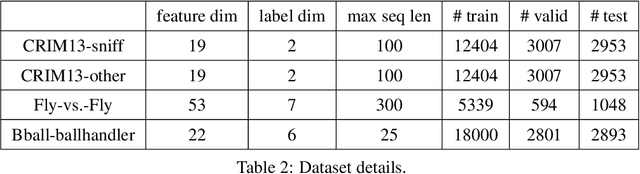
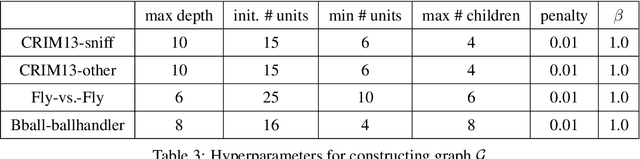
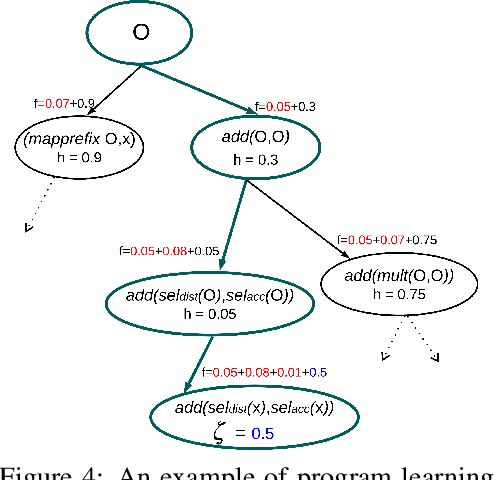
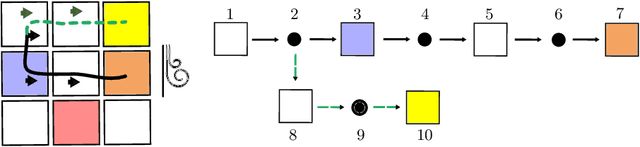
We study the problem of learning differentiable functions expressed as programs in a domain-specific language. Such programmatic models can offer benefits such as composability and interpretability; however, learning them requires optimizing over a combinatorial space of program "architectures". We frame this optimization problem as a search in a weighted graph whose paths encode top-down derivations of program syntax. Our key innovation is to view various classes of neural networks as continuous relaxations over the space of programs, which can then be used to complete any partial program. This relaxed program is differentiable and can be trained end-to-end, and the resulting training loss is an approximately admissible heuristic that can guide the combinatorial search. We instantiate our approach on top of the A-star algorithm and an iteratively deepened branch-and-bound search, and use these algorithms to learn programmatic classifiers in three sequence classification tasks. Our experiments show that the algorithms outperform state-of-the-art methods for program learning, and that they discover programmatic classifiers that yield natural interpretations and achieve competitive accuracy.
Representing Formal Languages: A Comparison Between Finite Automata and Recurrent Neural Networks
Feb 27, 2019
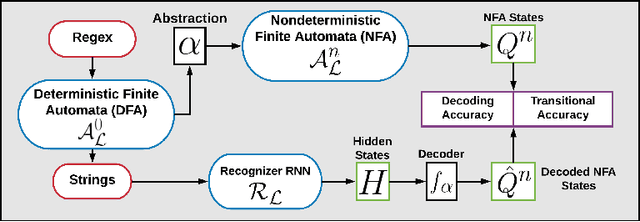

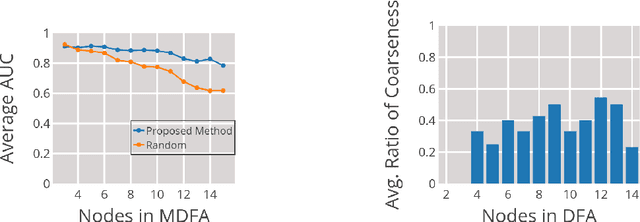
We investigate the internal representations that a recurrent neural network (RNN) uses while learning to recognize a regular formal language. Specifically, we train a RNN on positive and negative examples from a regular language, and ask if there is a simple decoding function that maps states of this RNN to states of the minimal deterministic finite automaton (MDFA) for the language. Our experiments show that such a decoding function indeed exists, and that it maps states of the RNN not to MDFA states, but to states of an {\em abstraction} obtained by clustering small sets of MDFA states into "superstates". A qualitative analysis reveals that the abstraction often has a simple interpretation. Overall, the results suggest a strong structural relationship between internal representations used by RNNs and finite automata, and explain the well-known ability of RNNs to recognize formal grammatical structure.