 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRHO: Your Coding Agent is Secretly a Roboticist
Jun 15, 2026Code-as-Policies (CaP) has shown that large language models (LLMs) can write code to solve robotics tasks by composing perception, planning, and control primitives. Recent CaP systems, however, rely on multi-turn code-generation loops at test time, which is often infeasible for real-time robot control. We introduce Robotics Harness Optimization (RHO), a novel paradigm in which tool-enabled coding agents, at training time, propose and search for interpretable, neurosymbolic multi-file policy repositories (Repositories-as-Policies) that compose these primitives rather than a single prompt, function, or file. RHO searches with reflective feedback from environment reward and execution rather than teleoperation demonstrations. It generalizes to perturbed pick-and-place settings like LIBERO-PRO, where OpenVLA scores 0.0% and $π_{0.5}$ averages 12.83%. Using the same low-level primitives, RHO reaches a 45.0% success rate, 2.5x higher than the strongest multi-turn agentic system, and 3.5x higher than $π_{0.5}$. On Robosuite, RHO sets a new state-of-the-art of 70.0%, exceeding the prior multi-turn record of 68.29% using single-turn execution with no corrective LLM code edits at deployment. When an LLM is used in the control loop, as on RAI's O3DE benchmark, RHO optimizes the deployed agent's multi-file harness of prompts, tools, and control code, improving held-out success from 23.5% to 44.3% with 20% less wall-clock time and 27% fewer tool calls.
optimize_anything: A Universal API for Optimizing any Text Parameter
May 19, 2026Can a single LLM-based optimization system match specialized tools across fundamentally different domains? We show that when optimization problems are formulated as improving a text artifact evaluated by a scoring function, a single AI-based optimization system-supporting single-task search, multi-task search with cross-problem transfer, and generalization to unseen inputs-achieves state-of-the-art results across six diverse tasks. Our system discovers agent architectures that nearly triple Gemini Flash's ARC-AGI accuracy (32.5% to 89.5%), finds scheduling algorithms that cut cloud costs by 40%, generates CUDA kernels where 87% match or beat PyTorch, and outperforms AlphaEvolve's reported circle packing solution (n=26). Ablations across three domains reveal that actionable side information yields faster convergence and substantially higher final scores than score-only feedback, and that multi-task search outperforms independent optimization given equivalent per-problem budget through cross-task transfer, with benefits scaling with the number of related tasks. Together, we show for the first time that text optimization with LLM-based search is a general-purpose problem-solving paradigm, unifying tasks traditionally requiring domain-specific algorithms under a single framework. We open-source optimize\_anything with support for multiple backends as part of the GEPA project at https://github.com/gepa-ai/gepa .
* 16 pages, 11 figures; Blog: https://gepa-ai.github.io/gepa/blog/2026/02/18/introducing-optimize-anything/
ScenicRules: An Autonomous Driving Benchmark with Multi-Objective Specifications and Abstract Scenarios
Feb 17, 2026Developing autonomous driving systems for complex traffic environments requires balancing multiple objectives, such as avoiding collisions, obeying traffic rules, and making efficient progress. In many situations, these objectives cannot be satisfied simultaneously, and explicit priority relations naturally arise. Also, driving rules require context, so it is important to formally model the environment scenarios within which such rules apply. Existing benchmarks for evaluating autonomous vehicles lack such combinations of multi-objective prioritized rules and formal environment models. In this work, we introduce ScenicRules, a benchmark for evaluating autonomous driving systems in stochastic environments under prioritized multi-objective specifications. We first formalize a diverse set of objectives to serve as quantitative evaluation metrics. Next, we design a Hierarchical Rulebook framework that encodes multiple objectives and their priority relations in an interpretable and adaptable manner. We then construct a compact yet representative collection of scenarios spanning diverse driving contexts and near-accident situations, formally modeled in the Scenic language. Experimental results show that our formalized objectives and Hierarchical Rulebooks align well with human driving judgments and that our benchmark effectively exposes agent failures with respect to the prioritized objectives. Our benchmark can be accessed at https://github.com/BerkeleyLearnVerify/ScenicRules/.
Learning Contextual Runtime Monitors for Safe AI-Based Autonomy
Jan 28, 2026We introduce a novel framework for learning context-aware runtime monitors for AI-based control ensembles. Machine-learning (ML) controllers are increasingly deployed in (autonomous) cyber-physical systems because of their ability to solve complex decision-making tasks. However, their accuracy can degrade sharply in unfamiliar environments, creating significant safety concerns. Traditional ensemble methods aim to improve robustness by averaging or voting across multiple controllers, yet this often dilutes the specialized strengths that individual controllers exhibit in different operating contexts. We argue that, rather than blending controller outputs, a monitoring framework should identify and exploit these contextual strengths. In this paper, we reformulate the design of safe AI-based control ensembles as a contextual monitoring problem. A monitor continuously observes the system's context and selects the controller best suited to the current conditions. To achieve this, we cast monitor learning as a contextual learning task and draw on techniques from contextual multi-armed bandits. Our approach comes with two key benefits: (1) theoretical safety guarantees during controller selection, and (2) improved utilization of controller diversity. We validate our framework in two simulated autonomous driving scenarios, demonstrating significant improvements in both safety and performance compared to non-contextual baselines.
Robust and Diverse Multi-Agent Learning via Rational Policy Gradient
Nov 12, 2025Adversarial optimization algorithms that explicitly search for flaws in agents' policies have been successfully applied to finding robust and diverse policies in multi-agent settings. However, the success of adversarial optimization has been largely limited to zero-sum settings because its naive application in cooperative settings leads to a critical failure mode: agents are irrationally incentivized to self-sabotage, blocking the completion of tasks and halting further learning. To address this, we introduce Rationality-preserving Policy Optimization (RPO), a formalism for adversarial optimization that avoids self-sabotage by ensuring agents remain rational--that is, their policies are optimal with respect to some possible partner policy. To solve RPO, we develop Rational Policy Gradient (RPG), which trains agents to maximize their own reward in a modified version of the original game in which we use opponent shaping techniques to optimize the adversarial objective. RPG enables us to extend a variety of existing adversarial optimization algorithms that, no longer subject to the limitations of self-sabotage, can find adversarial examples, improve robustness and adaptability, and learn diverse policies. We empirically validate that our approach achieves strong performance in several popular cooperative and general-sum environments. Our project page can be found at https://rational-policy-gradient.github.io.
MRTA-Sim: A Modular Simulator for Multi-Robot Allocation, Planning, and Control in Open-World Environments
Apr 21, 2025



This paper introduces MRTA-Sim, a Python/ROS2/Gazebo simulator for testing approaches to Multi-Robot Task Allocation (MRTA) problems on simulated robots in complex, indoor environments. Grid-based approaches to MRTA problems can be too restrictive for use in complex, dynamic environments such in warehouses, department stores, hospitals, etc. However, approaches that operate in free-space often operate at a layer of abstraction above the control and planning layers of a robot and make an assumption on approximate travel time between points of interest in the system. These abstractions can neglect the impact of the tight space and multi-agent interactions on the quality of the solution. Therefore, MRTA solutions should be tested with the navigation stacks of the robots in mind, taking into account robot planning, conflict avoidance between robots, and human interaction and avoidance. This tool connects the allocation output of MRTA solvers to individual robot planning using the NAV2 stack and local, centralized multi-robot deconfliction using Control Barrier Function-Quadrtic Programs (CBF-QPs), creating a platform closer to real-world operation for more comprehensive testing of these approaches. The simulation architecture is modular so that users can swap out methods at different levels of the stack. We show the use of our system with a Satisfiability Modulo Theories (SMT)-based approach to dynamic MRTA on a fleet of indoor delivery robots.
Provably Correct Automata Embeddings for Optimal Automata-Conditioned Reinforcement Learning
Mar 06, 2025Automata-conditioned reinforcement learning (RL) has given promising results for learning multi-task policies capable of performing temporally extended objectives given at runtime, done by pretraining and freezing automata embeddings prior to training the downstream policy. However, no theoretical guarantees were given. This work provides a theoretical framework for the automata-conditioned RL problem and shows that it is probably approximately correct learnable. We then present a technique for learning provably correct automata embeddings, guaranteeing optimal multi-task policy learning. Our experimental evaluation confirms these theoretical results.
Learning Symbolic Task Decompositions for Multi-Agent Teams
Feb 19, 2025



One approach for improving sample efficiency in cooperative multi-agent learning is to decompose overall tasks into sub-tasks that can be assigned to individual agents. We study this problem in the context of reward machines: symbolic tasks that can be formally decomposed into sub-tasks. In order to handle settings without a priori knowledge of the environment, we introduce a framework that can learn the optimal decomposition from model-free interactions with the environment. Our method uses a task-conditioned architecture to simultaneously learn an optimal decomposition and the corresponding agents' policies for each sub-task. In doing so, we remove the need for a human to manually design the optimal decomposition while maintaining the sample-efficiency benefits of improved credit assignment. We provide experimental results in several deep reinforcement learning settings, demonstrating the efficacy of our approach. Our results indicate that our approach succeeds even in environments with codependent agent dynamics, enabling synchronous multi-agent learning not achievable in previous works.
Syzygy: Dual Code-Test C to (safe) Rust Translation using LLMs and Dynamic Analysis
Dec 18, 2024Despite extensive usage in high-performance, low-level systems programming applications, C is susceptible to vulnerabilities due to manual memory management and unsafe pointer operations. Rust, a modern systems programming language, offers a compelling alternative. Its unique ownership model and type system ensure memory safety without sacrificing performance. In this paper, we present Syzygy, an automated approach to translate C to safe Rust. Our technique uses a synergistic combination of LLM-driven code and test translation guided by dynamic-analysis-generated execution information. This paired translation runs incrementally in a loop over the program in dependency order of the code elements while maintaining per-step correctness. Our approach exposes novel insights on combining the strengths of LLMs and dynamic analysis in the context of scaling and combining code generation with testing. We apply our approach to successfully translate Zopfli, a high-performance compression library with ~3000 lines of code and 98 functions. We validate the translation by testing equivalence with the source C program on a set of inputs. To our knowledge, this is the largest automated and test-validated C to safe Rust code translation achieved so far.
Compositional Automata Embeddings for Goal-Conditioned Reinforcement Learning
Oct 31, 2024
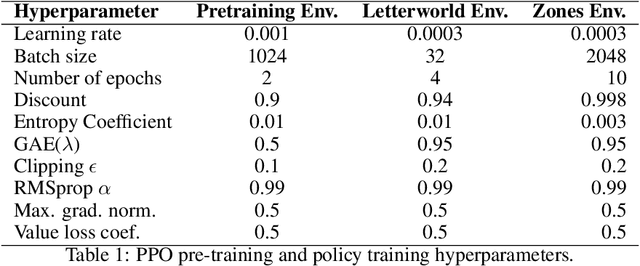
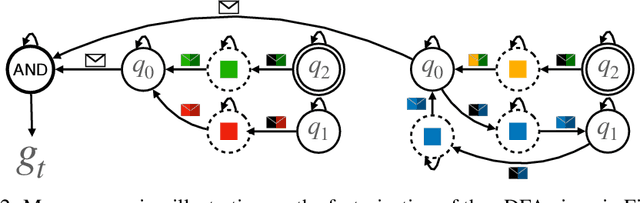
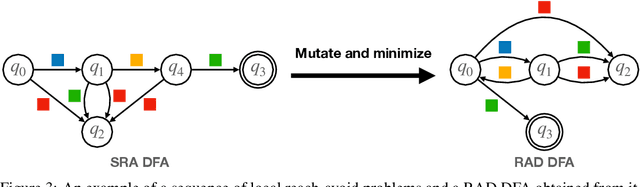
Goal-conditioned reinforcement learning is a powerful way to control an AI agent's behavior at runtime. That said, popular goal representations, e.g., target states or natural language, are either limited to Markovian tasks or rely on ambiguous task semantics. We propose representing temporal goals using compositions of deterministic finite automata (cDFAs) and use cDFAs to guide RL agents. cDFAs balance the need for formal temporal semantics with ease of interpretation: if one can understand a flow chart, one can understand a cDFA. On the other hand, cDFAs form a countably infinite concept class with Boolean semantics, and subtle changes to the automaton can result in very different tasks, making them difficult to condition agent behavior on. To address this, we observe that all paths through a DFA correspond to a series of reach-avoid tasks and propose pre-training graph neural network embeddings on "reach-avoid derived" DFAs. Through empirical evaluation, we demonstrate that the proposed pre-training method enables zero-shot generalization to various cDFA task classes and accelerated policy specialization without the myopic suboptimality of hierarchical methods.