 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposer 2 Technical Report
Mar 25, 2026Composer 2 is a specialized model designed for agentic software engineering. The model demonstrates strong long-term planning and coding intelligence while maintaining the ability to efficiently solve problems for interactive use. The model is trained in two phases: first, continued pretraining to improve the model's knowledge and latent coding ability, followed by large-scale reinforcement learning to improve end-to-end coding performance through stronger reasoning, accurate multi-step execution, and coherence on long-horizon realistic coding problems. We develop infrastructure to support training in the same Cursor harness that is used by the deployed model, with equivalent tools and structure, and use environments that match real problems closely. To measure the ability of the model on increasingly difficult tasks, we introduce a benchmark derived from real software engineering problems in large codebases including our own. Composer 2 is a frontier-level coding model and demonstrates a process for training strong domain-specialized models. On our CursorBench evaluations the model achieves a major improvement in accuracy compared to previous Composer models (61.3). On public benchmarks the model scores 61.7 on Terminal-Bench and 73.7 on SWE-bench Multilingual in our harness, comparable to state-of-the-art systems.
Reconstruction Guided Few-shot Network For Remote Sensing Image Classification
Jan 12, 2026Few-shot remote sensing image classification is challenging due to limited labeled samples and high variability in land-cover types. We propose a reconstruction-guided few-shot network (RGFS-Net) that enhances generalization to unseen classes while preserving consistency for seen categories. Our method incorporates a masked image reconstruction task, where parts of the input are occluded and reconstructed to encourage semantically rich feature learning. This auxiliary task strengthens spatial understanding and improves class discrimination under low-data settings. We evaluated the efficacy of EuroSAT and PatternNet datasets under 1-shot and 5-shot protocols, our approach consistently outperforms existing baselines. The proposed method is simple, effective, and compatible with standard backbones, offering a robust solution for few-shot remote sensing classification. Codes are available at https://github.com/stark0908/RGFS.
GSO: Challenging Software Optimization Tasks for Evaluating SWE-Agents
May 29, 2025Developing high-performance software is a complex task that requires specialized expertise. We introduce GSO, a benchmark for evaluating language models' capabilities in developing high-performance software. We develop an automated pipeline that generates and executes performance tests to analyze repository commit histories to identify 102 challenging optimization tasks across 10 codebases, spanning diverse domains and programming languages. An agent is provided with a codebase and performance test as a precise specification, and tasked to improve the runtime efficiency, which is measured against the expert developer optimization. Our quantitative evaluation reveals that leading SWE-Agents struggle significantly, achieving less than 5% success rate, with limited improvements even with inference-time scaling. Our qualitative analysis identifies key failure modes, including difficulties with low-level languages, practicing lazy optimization strategies, and challenges in accurately localizing bottlenecks. We release the code and artifacts of our benchmark along with agent trajectories to enable future research.
Waymo Driverless Car Data Analysis and Driving Modeling using CNN and LSTM
Apr 29, 2025Self driving cars has been the biggest innovation in the automotive industry, but to achieve human level accuracy or near human level accuracy is the biggest challenge that research scientists are facing today. Unlike humans autonomous vehicles do not work on instincts rather they make a decision based on the training data that has been fed to them using machine learning models using which they can make decisions in different conditions they face in the real world. With the advancements in machine learning especially deep learning the self driving car research skyrocketed. In this project we have presented multiple ways to predict acceleration of the autonomous vehicle using Waymo's open dataset. Our main approach was to using CNN to mimic human action and LSTM to treat this as a time series problem.
R2E-Gym: Procedural Environments and Hybrid Verifiers for Scaling Open-Weights SWE Agents
Apr 09, 2025Improving open-source models on real-world SWE tasks (solving GITHUB issues) faces two key challenges: 1) scalable curation of execution environments to train these models, and, 2) optimal scaling of test-time compute. We introduce AgentGym, the largest procedurally-curated executable gym environment for training real-world SWE-agents, consisting of more than 8.7K tasks. AgentGym is powered by two main contributions: 1) SYNGEN: a synthetic data curation recipe that enables scalable curation of executable environments using test-generation and back-translation directly from commits, thereby reducing reliance on human-written issues or unit tests. We show that this enables more scalable training leading to pass@1 performance of 34.4% on SWE-Bench Verified benchmark with our 32B model. 2) Hybrid Test-time Scaling: we provide an in-depth analysis of two test-time scaling axes; execution-based and execution-free verifiers, demonstrating that they exhibit complementary strengths and limitations. Test-based verifiers suffer from low distinguishability, while execution-free verifiers are biased and often rely on stylistic features. Surprisingly, we find that while each approach individually saturates around 42-43%, significantly higher gains can be obtained by leveraging their complementary strengths. Overall, our approach achieves 51% on the SWE-Bench Verified benchmark, reflecting a new state-of-the-art for open-weight SWE-agents and for the first time showing competitive performance with proprietary models such as o1, o1-preview and sonnet-3.5-v2 (with tools). We will open-source our environments, models, and agent trajectories.
Challenges and Paths Towards AI for Software Engineering
Mar 28, 2025AI for software engineering has made remarkable progress recently, becoming a notable success within generative AI. Despite this, there are still many challenges that need to be addressed before automated software engineering reaches its full potential. It should be possible to reach high levels of automation where humans can focus on the critical decisions of what to build and how to balance difficult tradeoffs while most routine development effort is automated away. Reaching this level of automation will require substantial research and engineering efforts across academia and industry. In this paper, we aim to discuss progress towards this in a threefold manner. First, we provide a structured taxonomy of concrete tasks in AI for software engineering, emphasizing the many other tasks in software engineering beyond code generation and completion. Second, we outline several key bottlenecks that limit current approaches. Finally, we provide an opinionated list of promising research directions toward making progress on these bottlenecks, hoping to inspire future research in this rapidly maturing field.
Syzygy: Dual Code-Test C to (safe) Rust Translation using LLMs and Dynamic Analysis
Dec 18, 2024Despite extensive usage in high-performance, low-level systems programming applications, C is susceptible to vulnerabilities due to manual memory management and unsafe pointer operations. Rust, a modern systems programming language, offers a compelling alternative. Its unique ownership model and type system ensure memory safety without sacrificing performance. In this paper, we present Syzygy, an automated approach to translate C to safe Rust. Our technique uses a synergistic combination of LLM-driven code and test translation guided by dynamic-analysis-generated execution information. This paired translation runs incrementally in a loop over the program in dependency order of the code elements while maintaining per-step correctness. Our approach exposes novel insights on combining the strengths of LLMs and dynamic analysis in the context of scaling and combining code generation with testing. We apply our approach to successfully translate Zopfli, a high-performance compression library with ~3000 lines of code and 98 functions. We validate the translation by testing equivalence with the source C program on a set of inputs. To our knowledge, this is the largest automated and test-validated C to safe Rust code translation achieved so far.
SelfCodeAlign: Self-Alignment for Code Generation
Oct 31, 2024



Instruction tuning is a supervised fine-tuning approach that significantly improves the ability of large language models (LLMs) to follow human instructions. We propose SelfCodeAlign, the first fully transparent and permissive pipeline for self-aligning code LLMs without extensive human annotations or distillation. SelfCodeAlign employs the same base model for inference throughout the data generation process. It first extracts diverse coding concepts from high-quality seed snippets to generate new tasks. It then samples multiple responses per task, pairs each with test cases, and validates them in a sandbox environment. Finally, passing examples are selected for instruction tuning. In our primary experiments, we use SelfCodeAlign with CodeQwen1.5-7B to generate a dataset of 74k instruction-response pairs. Finetuning on this dataset leads to a model that achieves a 67.1 pass@1 on HumanEval+, surpassing CodeLlama-70B-Instruct despite being ten times smaller. Across all benchmarks, this finetuned model consistently outperforms the original version trained with OctoPack, the previous state-of-the-art method for instruction tuning without human annotations or distillation. Additionally, we show that SelfCodeAlign is effective across LLMs of various sizes, from 3B to 33B, and that the base models can benefit more from alignment with their own data distribution. We further validate each component's effectiveness in our pipeline, showing that SelfCodeAlign outperforms both direct distillation from GPT-4o and leading GPT-3.5-based distillation methods, such as OSS-Instruct and Evol-Instruct. SelfCodeAlign has also led to the creation of StarCoder2-Instruct, the first fully transparent, permissively licensed, and self-aligned code LLM that achieves state-of-the-art coding performance.
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Jun 26, 2024



Automated software engineering has been greatly empowered by the recent advances in Large Language Models (LLMs) for programming. While current benchmarks have shown that LLMs can perform various software engineering tasks like human developers, the majority of their evaluations are limited to short and self-contained algorithmic tasks. Solving challenging and practical programming tasks requires the capability of utilizing diverse function calls as tools to efficiently implement functionalities like data analysis and web development. In addition, using multiple tools to solve a task needs compositional reasoning by accurately understanding complex instructions. Fulfilling both of these characteristics can pose a great challenge for LLMs. To assess how well LLMs can solve challenging and practical programming tasks, we introduce Bench, a benchmark that challenges LLMs to invoke multiple function calls as tools from 139 libraries and 7 domains for 1,140 fine-grained programming tasks. To evaluate LLMs rigorously, each programming task encompasses 5.6 test cases with an average branch coverage of 99%. In addition, we propose a natural-language-oriented variant of Bench, Benchi, that automatically transforms the original docstrings into short instructions only with essential information. Our extensive evaluation of 60 LLMs shows that LLMs are not yet capable of following complex instructions to use function calls precisely, with scores up to 60%, significantly lower than the human performance of 97%. The results underscore the need for further advancements in this area.
RAFT: Adapting Language Model to Domain Specific RAG
Mar 15, 2024
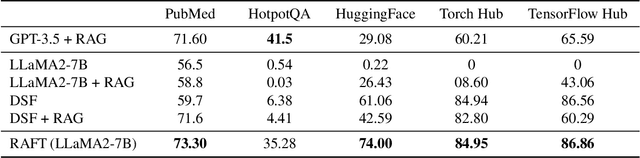
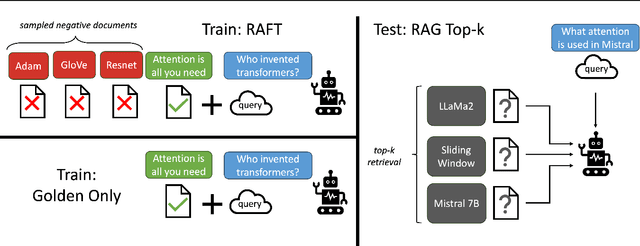
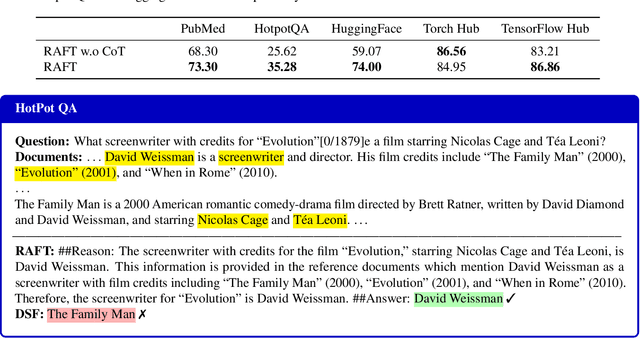
Pretraining Large Language Models (LLMs) on large corpora of textual data is now a standard paradigm. When using these LLMs for many downstream applications, it is common to additionally bake in new knowledge (e.g., time-critical news, or private domain knowledge) into the pretrained model either through RAG-based-prompting, or fine-tuning. However, the optimal methodology for the model to gain such new knowledge remains an open question. In this paper, we present Retrieval Augmented FineTuning (RAFT), a training recipe that improves the model's ability to answer questions in a "open-book" in-domain settings. In RAFT, given a question, and a set of retrieved documents, we train the model to ignore those documents that don't help in answering the question, which we call, distractor documents. RAFT accomplishes this by citing verbatim the right sequence from the relevant document that would help answer the question. This coupled with RAFT's chain-of-thought-style response helps improve the model's ability to reason. In domain-specific RAG, RAFT consistently improves the model's performance across PubMed, HotpotQA, and Gorilla datasets, presenting a post-training recipe to improve pre-trained LLMs to in-domain RAG. RAFT's code and demo are open-sourced at github.com/ShishirPatil/gorilla.