 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense2MoE: Pushing the Pareto Frontier of On-Device LLMs via Unified Pruning and Upcycling
May 26, 2026The Mixture of Experts MoE architecture is highly promising for resource constrained on device deployments yet training these models from scratch incurs prohibitive costs Current methods attempt to alleviate this by upcycling dense models into MoEs however they often introduce parameter redundancy that degrades inference efficiency Alternatively standard layer pruning mitigates redundancy but inevitably compromises model accuracy To resolve this dilemma we propose Dense2MoE a novel framework that unifies pruning and upcycling through Layer Fusion UpCycling LF UC Guided by hardware Roofline theory Dense2MoE systematically overcomes the inference memory wall by pruning bandwidth heavy attention modules from redundant layers while repurposing their Multi Layer Perceptrons MLPs into MoE experts This structural innovation preserves the models core capabilities and strictly limits active parameters via selective token routing With a modest continual pre training budget Dense2MoE efficiently converts publicly available dense LLMs into on device ready MoE models Extensive experiments demonstrate that Dense2MoE significantly advances the Pareto frontier for on device inference latency versus model accuracy outperforming dense baselines state of the art compression and standard upcycling methods
Hardware Co-Design Scaling Laws via Roofline Modelling for On-Device LLMs
Feb 10, 2026Vision-Language-Action Models (VLAs) have emerged as a key paradigm of Physical AI and are increasingly deployed in autonomous vehicles, robots, and smart spaces. In these resource-constrained on-device settings, selecting an appropriate large language model (LLM) backbone is a critical challenge: models must balance accuracy with strict inference latency and hardware efficiency constraints. This makes hardware-software co-design a game-changing requirement for on-device LLM deployment, where each hardware platform demands a tailored architectural solution. We propose a hardware co-design law that jointly captures model accuracy and inference performance. Specifically, we model training loss as an explicit function of architectural hyperparameters and characterise inference latency via roofline modelling. We empirically evaluate 1,942 candidate architectures on NVIDIA Jetson Orin, training 170 selected models for 10B tokens each to fit a scaling law relating architecture to training loss. By coupling this scaling law with latency modelling, we establish a direct accuracy-latency correspondence and identify the Pareto frontier for hardware co-designed LLMs. We further formulate architecture search as a joint optimisation over precision and performance, deriving feasible design regions under industrial hardware and application budgets. Our approach reduces architecture selection from months to days. At the same latency as Qwen2.5-0.5B on the target hardware, our co-designed architecture achieves 19.42% lower perplexity on WikiText-2. To our knowledge, this is the first principled and operational framework for hardware co-design scaling laws in on-device LLM deployment. We will make the code and related checkpoints publicly available.
SWE-Replay: Efficient Test-Time Scaling for Software Engineering Agents
Jan 29, 2026Test-time scaling has been widely adopted to enhance the capabilities of Large Language Model (LLM) agents in software engineering (SWE) tasks. However, the standard approach of repeatedly sampling trajectories from scratch is computationally expensive. While recent methods have attempted to mitigate costs using specialized value agents, they can suffer from model miscalibration and fail to generalize to modern agents that synthesize custom bash scripts as tools. In this paper, we introduce SWE-Replay, the first efficient and generalizable test-time scaling technique for modern agents without reliance on potentially noisy value estimates. SWE-Replay optimizes the scaling process by recycling trajectories from prior trials, dynamically choosing to either explore from scratch or exploit archived experience by branching at critical intermediate steps. This selection of intermediate steps is driven by the potential and reasoning significance of repository exploration, rather than external LLM-based quality estimates. Our evaluation shows that, on SWE-Bench Verified, SWE-Replay consistently outperforms naive scaling, reducing costs by up to 17.4% while maintaining or even improving performance by up to 3.8%. Further evaluation on SWE-Bench Pro and Multilingual validates the generalizability of SWE-Replay, establishing it as a robust foundation for efficient test-time scaling of software engineering agents.
Empowering Multi-Turn Tool-Integrated Reasoning with Group Turn Policy Optimization
Nov 18, 2025
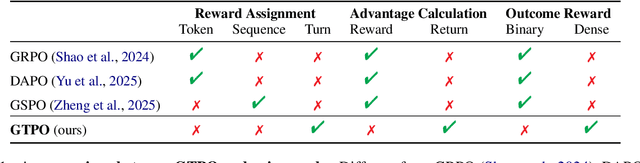
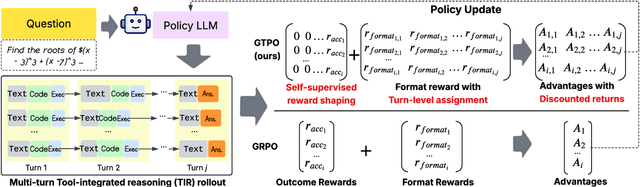
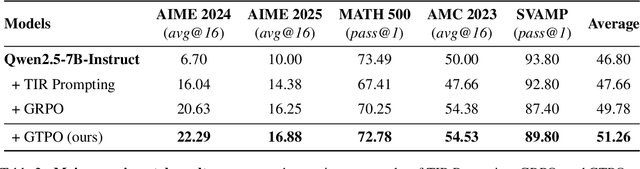
Training Large Language Models (LLMs) for multi-turn Tool-Integrated Reasoning (TIR) - where models iteratively reason, generate code, and verify through execution - remains challenging for existing reinforcement learning (RL) approaches. Current RL methods, exemplified by Group Relative Policy Optimization (GRPO), suffer from coarse-grained, trajectory-level rewards that provide insufficient learning signals for complex multi-turn interactions, leading to training stagnation. To address this issue, we propose Group Turn Policy Optimization (GTPO), a novel RL algorithm specifically designed for training LLMs on multi-turn TIR tasks. GTPO introduces three key innovations: (1) turn-level reward assignment that provides fine-grained feedback for individual turns, (2) return-based advantage estimation where normalized discounted returns are calculated as advantages, and (3) self-supervised reward shaping that exploits self-supervision signals from generated code to densify sparse binary outcome-based rewards. Our comprehensive evaluation demonstrates that GTPO outperforms GRPO by 3.0% on average across diverse reasoning benchmarks, establishing its effectiveness for advancing complex mathematical reasoning in the real world.
SMAR: Soft Modality-Aware Routing Strategy for MoE-based Multimodal Large Language Models Preserving Language Capabilities
Jun 06, 2025Mixture of Experts (MoE) architectures have become a key approach for scaling large language models, with growing interest in extending them to multimodal tasks. Existing methods to build multimodal MoE models either incur high training costs or suffer from degraded language capabilities when adapting pretrained models. To address this, we propose Soft ModalityAware Routing (SMAR), a novel regularization technique that uses Kullback Leibler divergence to control routing probability distributions across modalities, encouraging expert specialization without modifying model architecture or heavily relying on textual data. Experiments on visual instruction tuning show that SMAR preserves language ability at 86.6% retention with only 2.5% pure text, outperforming baselines while maintaining strong multimodal performance. Our approach offers a practical and efficient solution to balance modality differentiation and language capabilities in multimodal MoE models.
SelfCodeAlign: Self-Alignment for Code Generation
Oct 31, 2024



Instruction tuning is a supervised fine-tuning approach that significantly improves the ability of large language models (LLMs) to follow human instructions. We propose SelfCodeAlign, the first fully transparent and permissive pipeline for self-aligning code LLMs without extensive human annotations or distillation. SelfCodeAlign employs the same base model for inference throughout the data generation process. It first extracts diverse coding concepts from high-quality seed snippets to generate new tasks. It then samples multiple responses per task, pairs each with test cases, and validates them in a sandbox environment. Finally, passing examples are selected for instruction tuning. In our primary experiments, we use SelfCodeAlign with CodeQwen1.5-7B to generate a dataset of 74k instruction-response pairs. Finetuning on this dataset leads to a model that achieves a 67.1 pass@1 on HumanEval+, surpassing CodeLlama-70B-Instruct despite being ten times smaller. Across all benchmarks, this finetuned model consistently outperforms the original version trained with OctoPack, the previous state-of-the-art method for instruction tuning without human annotations or distillation. Additionally, we show that SelfCodeAlign is effective across LLMs of various sizes, from 3B to 33B, and that the base models can benefit more from alignment with their own data distribution. We further validate each component's effectiveness in our pipeline, showing that SelfCodeAlign outperforms both direct distillation from GPT-4o and leading GPT-3.5-based distillation methods, such as OSS-Instruct and Evol-Instruct. SelfCodeAlign has also led to the creation of StarCoder2-Instruct, the first fully transparent, permissively licensed, and self-aligned code LLM that achieves state-of-the-art coding performance.
Horizon-Length Prediction: Advancing Fill-in-the-Middle Capabilities for Code Generation with Lookahead Planning
Oct 04, 2024Fill-in-the-Middle (FIM) has become integral to code language models, enabling generation of missing code given both left and right contexts. However, the current FIM training paradigm, which reorders original training sequences and then performs regular next-token prediction (NTP), often leads to models struggling to generate content that aligns smoothly with the surrounding context. Crucially, while existing works rely on rule-based post-processing to circumvent this weakness, such methods are not practically usable in open-domain code completion tasks as they depend on restrictive, dataset-specific assumptions (e.g., generating the same number of lines as in the ground truth). Moreover, model performance on FIM tasks deteriorates significantly without these unrealistic assumptions. We hypothesize that NTP alone is insufficient for models to learn effective planning conditioned on the distant right context, a critical factor for successful code infilling. To overcome this, we propose Horizon-Length Prediction (HLP), a novel training objective that teaches models to predict the number of remaining middle tokens (i.e., horizon length) at each step. HLP advances FIM with lookahead planning, enabling models to inherently learn infilling boundaries for arbitrary left and right contexts without relying on dataset-specific post-processing. Our evaluation across different models and sizes shows that HLP significantly improves FIM performance by up to 24% relatively on diverse benchmarks, across file-level and repository-level, and without resorting to unrealistic post-processing methods. Furthermore, the enhanced planning capability gained through HLP boosts model performance on code reasoning. Importantly, HLP only incurs negligible training overhead and no additional inference cost, ensuring its practicality for real-world scenarios.
Evaluating Language Models for Efficient Code Generation
Aug 12, 2024We introduce Differential Performance Evaluation (DPE), a framework designed to reliably evaluate Large Language Models (LLMs) for efficient code generation. Traditional coding benchmarks often fail to provide reliable insights into code efficiency, due to their reliance on simplistic test inputs and the absence of effective compound metrics. DPE addresses these issues by focusing on efficiency-demanding programming tasks and establishing an insightful compound metric for performance evaluation. DPE operates in two phases: To curate efficiency datasets, it selects efficiency-demanding tasks from existing coding benchmarks and generates computationally expensive inputs to stress the efficiency of LLM solutions. To assess the code efficiency, DPE profiles the new solution and compares it globally against a set of reference solutions that exhibit distinct efficiency levels, where the matched level defines its efficiency score. As a proof of concept, we use DPE to create EvalPerf, a benchmark with 121 performance-challenging coding tasks. Our comprehensive evaluation draws interesting findings on the efficiency impact of model sizes, instruction tuning, and prompting. For example, while the scaling law fails to account for code efficiency, general instruction tuning benefits both code correctness and efficiency. We also evaluate the evaluation by examining the effectiveness of DPE, showing that EvalPerf is reliable and convenient to use even across platforms.
RepoQA: Evaluating Long Context Code Understanding
Jun 10, 2024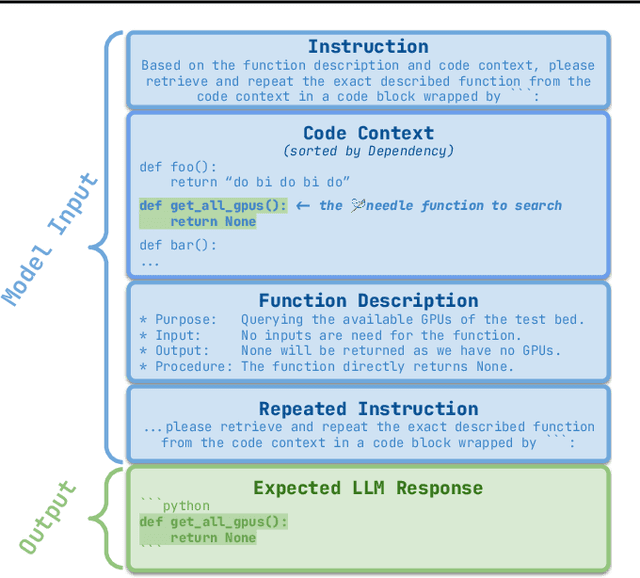
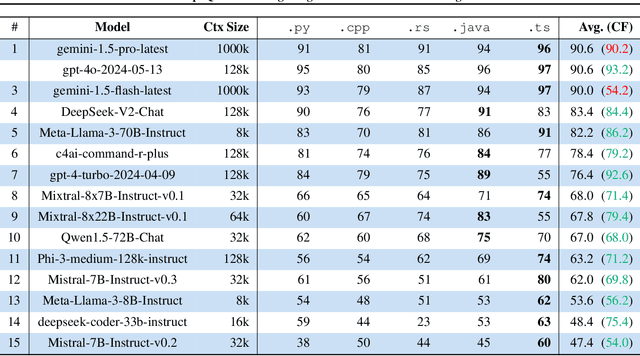
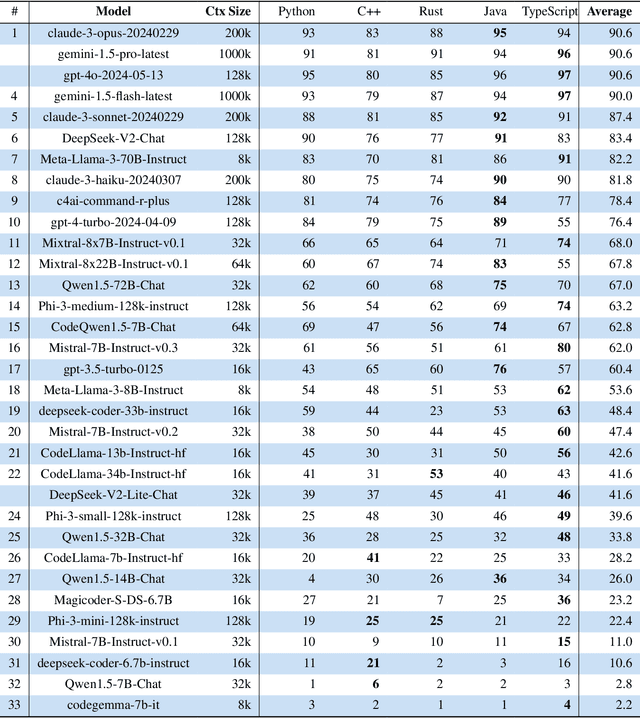
Recent advances have been improving the context windows of Large Language Models (LLMs). To quantify the real long-context capabilities of LLMs, evaluators such as the popular Needle in a Haystack have been developed to test LLMs over a large chunk of raw texts. While effective, current evaluations overlook the insight of how LLMs work with long-context code, i.e., repositories. To this end, we initiate the RepoQA benchmark to evaluate LLMs on long-context code understanding. Traditional needle testers ask LLMs to directly retrieve the answer from the context without necessary deep understanding. In RepoQA, we built our initial task, namely Searching Needle Function (SNF), which exercises LLMs to search functions given their natural-language description, i.e., LLMs cannot find the desired function if they cannot understand the description and code. RepoQA is multilingual and comprehensive: it includes 500 code search tasks gathered from 50 popular repositories across 5 modern programming languages. By evaluating 26 general and code-specific LLMs on RepoQA, we show (i) there is still a small gap between the best open and proprietary models; (ii) different models are good at different languages; and (iii) models may understand code better without comments.
XFT: Unlocking the Power of Code Instruction Tuning by Simply Merging Upcycled Mixture-of-Experts
Apr 23, 2024



We introduce XFT, a simple yet powerful training scheme, by simply merging upcycled Mixture-of-Experts (MoE) to unleash the performance limit of instruction-tuned code Large Language Models (LLMs). While vanilla sparse upcycling fails to improve instruction tuning, XFT introduces a shared expert mechanism with a novel routing weight normalization strategy into sparse upcycling, which significantly boosts instruction tuning. After fine-tuning the upcycled MoE model, XFT introduces a learnable model merging mechanism to compile the upcycled MoE model back to a dense model, achieving upcycled MoE-level performance with only dense-model compute. By applying XFT to a 1.3B model, we create a new state-of-the-art tiny code LLM (<3B) with 67.1 and 64.6 pass@1 on HumanEval and HumanEval+ respectively. With the same data and model architecture, XFT improves supervised fine-tuning (SFT) by 13% on HumanEval+, along with consistent improvements from 2% to 13% on MBPP+, MultiPL-E, and DS-1000, demonstrating its generalizability. XFT is fully orthogonal to existing techniques such as Evol-Instruct and OSS-Instruct, opening a new dimension for improving code instruction tuning. Codes are available at https://github.com/ise-uiuc/xft .