 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive-SWE-agent: Can Software Engineering Agents Self-Evolve on the Fly?
Nov 17, 2025



Large Language Models (LLMs) are reshaping almost all industries, including software engineering. In recent years, a number of LLM agents have been proposed to solve real-world software problems. Such software agents are typically equipped with a suite of coding tools and can autonomously decide the next actions to form complete trajectories to solve end-to-end software tasks. While promising, they typically require dedicated design and may still be suboptimal, since it can be extremely challenging and costly to exhaust the entire agent scaffold design space. Recognizing that software agents are inherently software themselves that can be further refined/modified, researchers have proposed a number of self-improving software agents recently, including the Darwin-Gödel Machine (DGM). Meanwhile, such self-improving agents require costly offline training on specific benchmarks and may not generalize well across different LLMs or benchmarks. In this paper, we propose Live-SWE-agent, the first live software agent that can autonomously and continuously evolve itself on-the-fly during runtime when solving real-world software problems. More specifically, Live-SWE-agent starts with the most basic agent scaffold with only access to bash tools (e.g., mini-SWE-agent), and autonomously evolves its own scaffold implementation while solving real-world software problems. Our evaluation on the widely studied SWE-bench Verified benchmark shows that Live-SWE-agent can achieve an impressive solve rate of 75.4% without test-time scaling, outperforming all existing open-source software agents and approaching the performance of the best proprietary solution. Moreover, Live-SWE-agent outperforms state-of-the-art manually crafted software agents on the recent SWE-Bench Pro benchmark, achieving the best-known solve rate of 45.8%.
Agentless: Demystifying LLM-based Software Engineering Agents
Jul 01, 2024



Recent advancements in large language models (LLMs) have significantly advanced the automation of software development tasks, including code synthesis, program repair, and test generation. More recently, researchers and industry practitioners have developed various autonomous LLM agents to perform end-to-end software development tasks. These agents are equipped with the ability to use tools, run commands, observe feedback from the environment, and plan for future actions. However, the complexity of these agent-based approaches, together with the limited abilities of current LLMs, raises the following question: Do we really have to employ complex autonomous software agents? To attempt to answer this question, we build Agentless -- an agentless approach to automatically solve software development problems. Compared to the verbose and complex setup of agent-based approaches, Agentless employs a simplistic two-phase process of localization followed by repair, without letting the LLM decide future actions or operate with complex tools. Our results on the popular SWE-bench Lite benchmark show that surprisingly the simplistic Agentless is able to achieve both the highest performance (27.33%) and lowest cost (\$0.34) compared with all existing open-source software agents! Furthermore, we manually classified the problems in SWE-bench Lite and found problems with exact ground truth patch or insufficient/misleading issue descriptions. As such, we construct SWE-bench Lite-S by excluding such problematic issues to perform more rigorous evaluation and comparison. Our work highlights the current overlooked potential of a simple, interpretable technique in autonomous software development. We hope Agentless will help reset the baseline, starting point, and horizon for autonomous software agents, and inspire future work along this crucial direction.
Top Leaderboard Ranking = Top Coding Proficiency, Always? EvoEval: Evolving Coding Benchmarks via LLM
Mar 28, 2024LLMs have become the go-to choice for code generation tasks, with an exponential increase in the training, development, and usage of LLMs specifically for code generation. To evaluate the ability of LLMs on code, both academic and industry practitioners rely on popular handcrafted benchmarks. However, prior benchmarks contain only a very limited set of problems, both in quantity and variety. Further, due to popularity and age, many benchmarks are prone to data leakage where example solutions can be readily found on the web and thus potentially in training data. Such limitations inevitably lead us to inquire: Is the leaderboard performance on existing benchmarks reliable and comprehensive enough to measure the program synthesis ability of LLMs? To address this, we introduce EvoEval -- a program synthesis benchmark suite created by evolving existing benchmarks into different targeted domains for a comprehensive evaluation of LLM coding abilities. Our study on 51 LLMs shows that compared to the high performance obtained on standard benchmarks like HumanEval, there is a significant drop in performance (on average 39.4%) when using EvoEval. Additionally, the decrease in performance can range from 19.6% to 47.7%, leading to drastic ranking changes amongst LLMs and showing potential overfitting of existing benchmarks. Furthermore, we showcase various insights, including the brittleness of instruction-following models when encountering rewording or subtle changes as well as the importance of learning problem composition and decomposition. EvoEval not only provides comprehensive benchmarks, but can be used to further evolve arbitrary problems to keep up with advances and the ever-changing landscape of LLMs for code. We have open-sourced our benchmarks, tools, and complete LLM generations at https://github.com/evo-eval/evoeval
Copiloting the Copilots: Fusing Large Language Models with Completion Engines for Automated Program Repair
Sep 01, 2023During Automated Program Repair (APR), it can be challenging to synthesize correct patches for real-world systems in general-purpose programming languages. Recent Large Language Models (LLMs) have been shown to be helpful "copilots" in assisting developers with various coding tasks, and have also been directly applied for patch synthesis. However, most LLMs treat programs as sequences of tokens, meaning that they are ignorant of the underlying semantics constraints of the target programming language. This results in plenty of statically invalid generated patches, impeding the practicality of the technique. Therefore, we propose Repilot, a framework to further copilot the AI "copilots" (i.e., LLMs) by synthesizing more valid patches during the repair process. Our key insight is that many LLMs produce outputs autoregressively (i.e., token by token), resembling human writing programs, which can be significantly boosted and guided through a Completion Engine. Repilot synergistically synthesizes a candidate patch through the interaction between an LLM and a Completion Engine, which 1) prunes away infeasible tokens suggested by the LLM and 2) proactively completes the token based on the suggestions provided by the Completion Engine. Our evaluation on a subset of the widely-used Defects4j 1.2 and 2.0 datasets shows that Repilot fixes 66 and 50 bugs, respectively, surpassing the best-performing baseline by 14 and 16 bugs fixed. More importantly, Repilot is capable of producing more valid and correct patches than the base LLM when given the same generation budget.
Universal Fuzzing via Large Language Models
Aug 09, 2023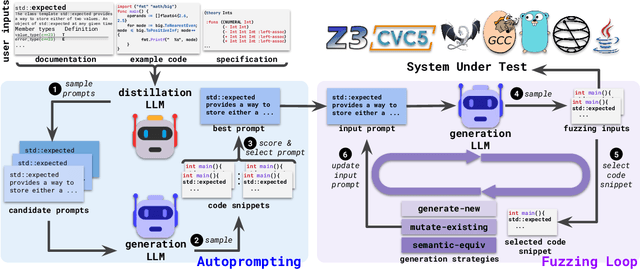


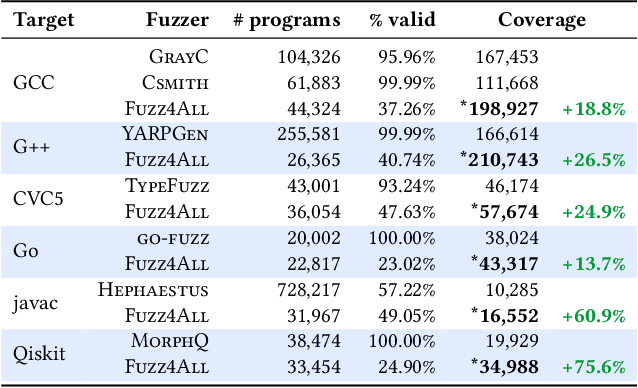
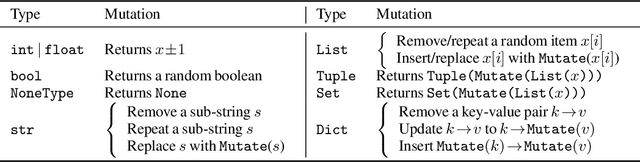
Fuzzing has achieved tremendous success in discovering bugs and vulnerabilities in various software systems. Systems under test (SUTs) that take in programming or formal language as inputs, e.g., compilers, runtime engines, constraint solvers, and software libraries with accessible APIs, are especially important as they are fundamental building blocks of software development. However, existing fuzzers for such systems often target a specific language, and thus cannot be easily applied to other languages or even other versions of the same language. Moreover, the inputs generated by existing fuzzers are often limited to specific features of the input language, and thus can hardly reveal bugs related to other or new features. This paper presents Fuzz4All, the first fuzzer that is universal in the sense that it can target many different input languages and many different features of these languages. The key idea behind Fuzz4All is to leverage large language models (LLMs) as an input generation and mutation engine, which enables the approach to produce diverse and realistic inputs for any practically relevant language. To realize this potential, we present a novel autoprompting technique, which creates LLM prompts that are wellsuited for fuzzing, and a novel LLM-powered fuzzing loop, which iteratively updates the prompt to create new fuzzing inputs. We evaluate Fuzz4All on nine systems under test that take in six different languages (C, C++, Go, SMT2, Java and Python) as inputs. The evaluation shows, across all six languages, that universal fuzzing achieves higher coverage than existing, language-specific fuzzers. Furthermore, Fuzz4All has identified 76 bugs in widely used systems, such as GCC, Clang, Z3, CVC5, OpenJDK, and the Qiskit quantum computing platform, with 47 bugs already confirmed by developers as previously unknown.
Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation
May 02, 2023
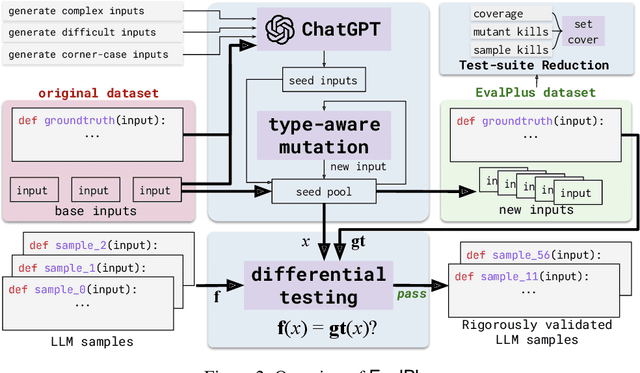
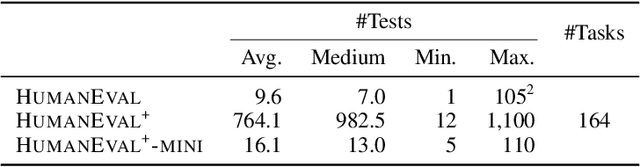
Program synthesis has been long studied with recent approaches focused on directly using the power of Large Language Models (LLMs) to generate code according to user intent written in natural language. Code evaluation datasets, containing curated synthesis problems with input/output test-cases, are used to measure the performance of various LLMs on code synthesis. However, test-cases in these datasets can be limited in both quantity and quality for fully assessing the functional correctness of the generated code. Such limitation in the existing benchmarks begs the following question: In the era of LLMs, is the code generated really correct? To answer this, we propose EvalPlus -- a code synthesis benchmarking framework to rigorously evaluate the functional correctness of LLM-synthesized code. In short, EvalPlus takes in the base evaluation dataset and uses an automatic input generation step to produce and diversify large amounts of new test inputs using both LLM-based and mutation-based input generators to further validate the synthesized code. We extend the popular HUMANEVAL benchmark and build HUMANEVAL+ with 81x additionally generated tests. Our extensive evaluation across 14 popular LLMs demonstrates that HUMANEVAL+ is able to catch significant amounts of previously undetected wrong code synthesized by LLMs, reducing the pass@k by 15.1% on average! Moreover, we even found several incorrect ground-truth implementations in HUMANEVAL. Our work not only indicates that prior popular code synthesis evaluation results do not accurately reflect the true performance of LLMs for code synthesis but also opens up a new direction to improve programming benchmarks through automated test input generation.
Keep the Conversation Going: Fixing 162 out of 337 bugs for $0.42 each using ChatGPT
Apr 01, 2023
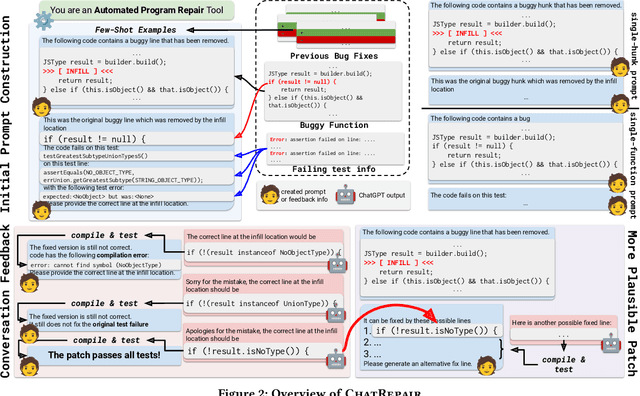

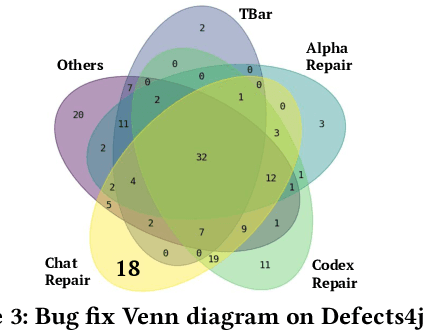
Automated Program Repair (APR) aims to automatically generate patches for buggy programs. Recent APR work has been focused on leveraging modern Large Language Models (LLMs) to directly generate patches for APR. Such LLM-based APR tools work by first constructing an input prompt built using the original buggy code and then queries the LLM to generate patches. While the LLM-based APR tools are able to achieve state-of-the-art results, it still follows the classic Generate and Validate repair paradigm of first generating lots of patches and then validating each one afterwards. This not only leads to many repeated patches that are incorrect but also miss the crucial information in test failures as well as in plausible patches. To address these limitations, we propose ChatRepair, the first fully automated conversation-driven APR approach that interleaves patch generation with instant feedback to perform APR in a conversational style. ChatRepair first feeds the LLM with relevant test failure information to start with, and then learns from both failures and successes of earlier patching attempts of the same bug for more powerful APR. For earlier patches that failed to pass all tests, we combine the incorrect patches with their corresponding relevant test failure information to construct a new prompt for the LLM to generate the next patch. In this way, we can avoid making the same mistakes. For earlier patches that passed all the tests, we further ask the LLM to generate alternative variations of the original plausible patches. In this way, we can further build on and learn from earlier successes to generate more plausible patches to increase the chance of having correct patches. While our approach is general, we implement ChatRepair using state-of-the-art dialogue-based LLM -- ChatGPT. By calculating the cost of accessing ChatGPT, we can fix 162 out of 337 bugs for \$0.42 each!
Revisiting the Plastic Surgery Hypothesis via Large Language Models
Mar 18, 2023Automated Program Repair (APR) aspires to automatically generate patches for an input buggy program. Traditional APR tools typically focus on specific bug types and fixes through the use of templates, heuristics, and formal specifications. However, these techniques are limited in terms of the bug types and patch variety they can produce. As such, researchers have designed various learning-based APR tools with recent work focused on directly using Large Language Models (LLMs) for APR. While LLM-based APR tools are able to achieve state-of-the-art performance on many repair datasets, the LLMs used for direct repair are not fully aware of the project-specific information such as unique variable or method names. The plastic surgery hypothesis is a well-known insight for APR, which states that the code ingredients to fix the bug usually already exist within the same project. Traditional APR tools have largely leveraged the plastic surgery hypothesis by designing manual or heuristic-based approaches to exploit such existing code ingredients. However, as recent APR research starts focusing on LLM-based approaches, the plastic surgery hypothesis has been largely ignored. In this paper, we ask the following question: How useful is the plastic surgery hypothesis in the era of LLMs? Interestingly, LLM-based APR presents a unique opportunity to fully automate the plastic surgery hypothesis via fine-tuning and prompting. To this end, we propose FitRepair, which combines the direct usage of LLMs with two domain-specific fine-tuning strategies and one prompting strategy for more powerful APR. Our experiments on the widely studied Defects4j 1.2 and 2.0 datasets show that FitRepair fixes 89 and 44 bugs (substantially outperforming the best-performing baseline by 15 and 8), respectively, demonstrating a promising future of the plastic surgery hypothesis in the era of LLMs.
Conversational Automated Program Repair
Jan 30, 2023



Automated Program Repair (APR) can help developers automatically generate patches for bugs. Due to the impressive performance obtained using Large Pre-Trained Language Models (LLMs) on many code related tasks, researchers have started to directly use LLMs for APR. However, prior approaches simply repeatedly sample the LLM given the same constructed input/prompt created from the original buggy code, which not only leads to generating the same incorrect patches repeatedly but also miss the critical information in testcases. To address these limitations, we propose conversational APR, a new paradigm for program repair that alternates between patch generation and validation in a conversational manner. In conversational APR, we iteratively build the input to the model by combining previously generated patches with validation feedback. As such, we leverage the long-term context window of LLMs to not only avoid generating previously incorrect patches but also incorporate validation feedback to help the model understand the semantic meaning of the program under test. We evaluate 10 different LLM including the newly developed ChatGPT model to demonstrate the improvement of conversational APR over the prior LLM for APR approach.