 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentStepper: Interactive Debugging of Software Development Agents
Feb 06, 2026Software development agents powered by large language models (LLMs) have shown great promise in automating tasks like environment setup, issue solving, and program repair. Unfortunately, understanding and debugging such agents remain challenging due to their complex and dynamic nature. Developers must reason about trajectories of LLM queries, tool calls, and code modifications, but current techniques reveal little of this intermediate process in a comprehensible format. The key insight of this paper is that debugging software development agents shares many similarities with conventional debugging of software programs, yet requires a higher level of abstraction that raises the level from low-level implementation details to high-level agent actions. Drawing on this insight, we introduce AgentStepper, the first interactive debugger for LLM-based software engineering agents. AgentStepper enables developers to inspect, control, and interactively manipulate agent trajectories. AgentStepper represents trajectories as structured conversations among an LLM, the agent program, and tools. It supports breakpoints, stepwise execution, and live editing of prompts and tool invocations, while capturing and displaying intermediate repository-level code changes. Our evaluation applies AgentStepper to three state-of-the-art software development agents, ExecutionAgent, SWE-Agent, and RepairAgent, showing that integrating the approach into existing agents requires minor code changes (39-42 edited lines). Moreover, we report on a user study with twelve participants, indicating that AgentStepper improves the ability of participants to interpret trajectories (64% vs. 67% mean performance) and identify bugs in the agent's implementation (17% vs. 60% success rate), while reducing perceived workload (e.g., frustration reduced from 5.4/7.0 to 2.4/7.0) compared to conventional tools.
Understanding Software Engineering Agents: A Study of Thought-Action-Result Trajectories
Jun 23, 2025Large Language Model (LLM)-based agents are increasingly employed to automate complex software engineering tasks such as program repair and issue resolution. These agents operate by autonomously generating natural language thoughts, invoking external tools, and iteratively refining their solutions. Despite their widespread adoption, the internal decision-making processes of these agents remain largely unexplored, limiting our understanding of their operational dynamics and failure modes. In this paper, we present a large-scale empirical study of the thought-action-result trajectories of three state-of-the-art LLM-based agents: \textsc{RepairAgent}, \textsc{AutoCodeRover}, and \textsc{OpenHands}. We unify their interaction logs into a common format, capturing 120 trajectories and 2822 LLM interactions focused on program repair and issue resolution. Our study combines quantitative analyses of structural properties, action patterns, and token usage with qualitative assessments of reasoning coherence and feedback integration. We identify key trajectory characteristics such as iteration counts and token consumption, recurring action sequences, and the semantic coherence linking thoughts, actions, and their results. Our findings reveal behavioral motifs and anti-patterns that distinguish successful from failed executions, providing actionable insights for improving agent design, including prompting strategies, failure diagnosis, and anti-pattern detection. We release our dataset and annotation framework to support further research on transparent and robust autonomous software engineering agents.
AI Software Engineer: Programming with Trust
Feb 19, 2025
Large Language Models (LLMs) have shown surprising proficiency in generating code snippets, promising to automate large parts of software engineering via artificial intelligence (AI). We argue that successfully deploying AI software engineers requires a level of trust equal to or even greater than the trust established by human-driven software engineering practices. The recent trend toward LLM agents offers a path toward integrating the power of LLMs to create new code with the power of analysis tools to increase trust in the code. This opinion piece comments on whether LLM agents could dominate software engineering workflows in the future and whether the focus of programming will shift from programming at scale to programming with trust.
Treefix: Enabling Execution with a Tree of Prefixes
Jan 21, 2025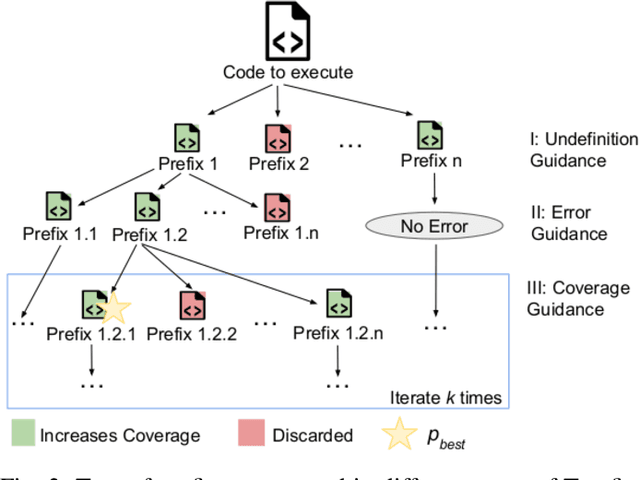



The ability to execute code is a prerequisite for various dynamic program analyses. Learning-guided execution has been proposed as an approach to enable the execution of arbitrary code snippets by letting a neural model predict likely values for any missing variables. Although state-of-the-art learning-guided execution approaches, such as LExecutor, can enable the execution of a relative high amount of code, they are limited to predicting a restricted set of possible values and do not use any feedback from previous executions to execute even more code. This paper presents Treefix, a novel learning-guided execution approach that leverages LLMs to iteratively create code prefixes that enable the execution of a given code snippet. The approach addresses the problem in a multi-step fashion, where each step uses feedback about the code snippet and its execution to instruct an LLM to improve a previously generated prefix. This process iteratively creates a tree of prefixes, a subset of which is returned to the user as prefixes that maximize the number of executed lines in the code snippet. In our experiments with two datasets of Python code snippets, Treefix achieves 25% and 7% more coverage relative to the current state of the art in learning-guided execution, covering a total of 84% and 82% of all lines in the code snippets.
You Name It, I Run It: An LLM Agent to Execute Tests of Arbitrary Projects
Dec 13, 2024The ability to execute the test suite of a project is essential in many scenarios, e.g., to assess code quality and code coverage, to validate code changes made by developers or automated tools, and to ensure compatibility with dependencies. Despite its importance, executing the test suite of a project can be challenging in practice because different projects use different programming languages, software ecosystems, build systems, testing frameworks, and other tools. These challenges make it difficult to create a reliable, universal test execution method that works across different projects. This paper presents ExecutionAgent, an automated technique that installs arbitrary projects, configures them to run test cases, and produces project-specific scripts to reproduce the setup. Inspired by the way a human developer would address this task, our approach is a large language model-based agent that autonomously executes commands and interacts with the host system. The agent uses meta-prompting to gather guidelines on the latest technologies related to the given project, and it iteratively refines its process based on feedback from the previous steps. Our evaluation applies ExecutionAgent to 50 open-source projects that use 14 different programming languages and many different build and testing tools. The approach successfully executes the test suites of 33/55 projects, while matching the test results of ground truth test suite executions with a deviation of only 7.5\%. These results improve over the best previously available technique by 6.6x. The costs imposed by the approach are reasonable, with an execution time of 74 minutes and LLM costs of 0.16 dollars, on average per project. We envision ExecutionAgent to serve as a valuable tool for developers, automated programming tools, and researchers that need to execute tests across a wide variety of projects.
Can LLMs Replace Manual Annotation of Software Engineering Artifacts?
Aug 10, 2024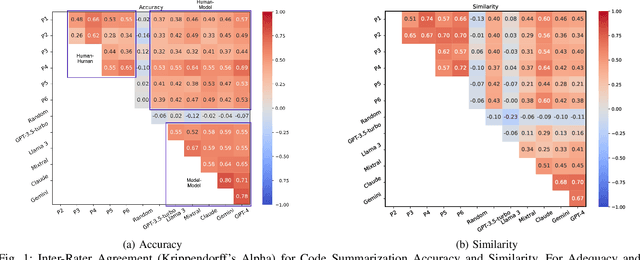
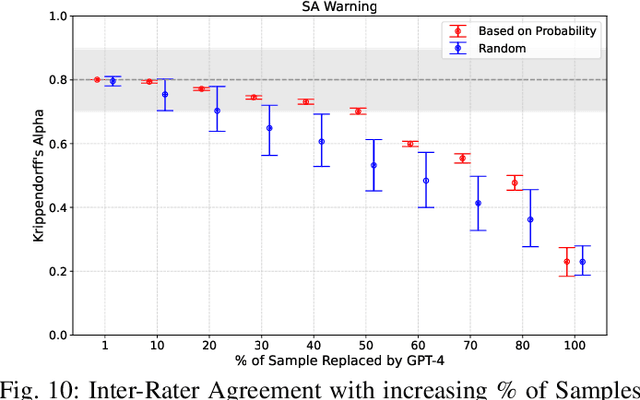
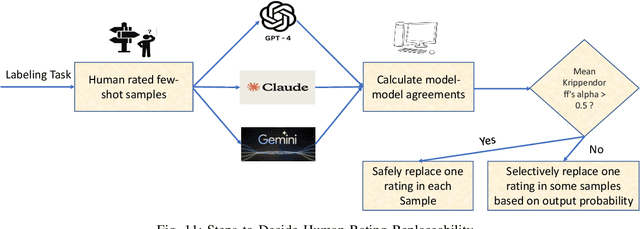
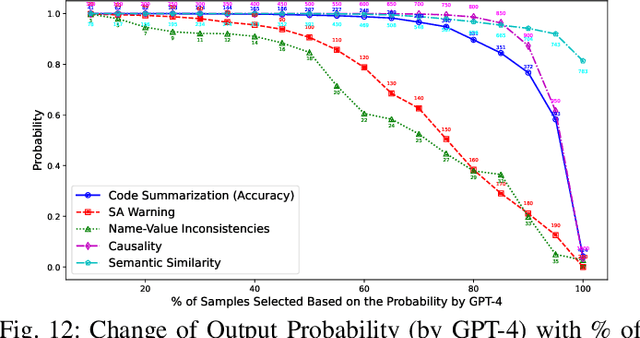
Experimental evaluations of software engineering innovations, e.g., tools and processes, often include human-subject studies as a component of a multi-pronged strategy to obtain greater generalizability of the findings. However, human-subject studies in our field are challenging, due to the cost and difficulty of finding and employing suitable subjects, ideally, professional programmers with varying degrees of experience. Meanwhile, large language models (LLMs) have recently started to demonstrate human-level performance in several areas. This paper explores the possibility of substituting costly human subjects with much cheaper LLM queries in evaluations of code and code-related artifacts. We study this idea by applying six state-of-the-art LLMs to ten annotation tasks from five datasets created by prior work, such as judging the accuracy of a natural language summary of a method or deciding whether a code change fixes a static analysis warning. Our results show that replacing some human annotation effort with LLMs can produce inter-rater agreements equal or close to human-rater agreement. To help decide when and how to use LLMs in human-subject studies, we propose model-model agreement as a predictor of whether a given task is suitable for LLMs at all, and model confidence as a means to select specific samples where LLMs can safely replace human annotators. Overall, our work is the first step toward mixed human-LLM evaluations in software engineering.
RepairAgent: An Autonomous, LLM-Based Agent for Program Repair
Mar 25, 2024



Automated program repair has emerged as a powerful technique to mitigate the impact of software bugs on system reliability and user experience. This paper introduces RepairAgent, the first work to address the program repair challenge through an autonomous agent based on a large language model (LLM). Unlike existing deep learning-based approaches, which prompt a model with a fixed prompt or in a fixed feedback loop, our work treats the LLM as an agent capable of autonomously planning and executing actions to fix bugs by invoking suitable tools. RepairAgent freely interleaves gathering information about the bug, gathering repair ingredients, and validating fixes, while deciding which tools to invoke based on the gathered information and feedback from previous fix attempts. Key contributions that enable RepairAgent include a set of tools that are useful for program repair, a dynamically updated prompt format that allows the LLM to interact with these tools, and a finite state machine that guides the agent in invoking the tools. Our evaluation on the popular Defects4J dataset demonstrates RepairAgent's effectiveness in autonomously repairing 164 bugs, including 39 bugs not fixed by prior techniques. Interacting with the LLM imposes an average cost of 270,000 tokens per bug, which, under the current pricing of OpenAI's GPT-3.5 model, translates to 14 cents of USD per bug. To the best of our knowledge, this work is the first to present an autonomous, LLM-based agent for program repair, paving the way for future agent-based techniques in software engineering.
Quality and Trust in LLM-generated Code
Feb 09, 2024



Machine learning models are widely used but can also often be wrong. Users would benefit from a reliable indication of whether a given output from a given model should be trusted, so a rational decision can be made whether to use the output or not. For example, outputs can be associated with a confidence measure; if this confidence measure is strongly associated with likelihood of correctness, then the model is said to be well-calibrated. In this case, for example, high-confidence outputs could be safely accepted, and low-confidence outputs rejected. Calibration has so far been studied in non-generative (e.g., classification) settings, especially in Software Engineering. However, generated code can quite often be wrong: Developers need to know when they should e.g., directly use, use after careful review, or discard model-generated code; thus Calibration is vital in generative settings. However, the notion of correctness of generated code is non-trivial, and thus so is Calibration. In this paper we make several contributions. We develop a framework for evaluating the Calibration of code-generating models. We consider several tasks, correctness criteria, datasets, and approaches, and find that by and large generative code models are not well-calibrated out of the box. We then show how Calibration can be improved, using standard methods such as Platt scaling. Our contributions will lead to better-calibrated decision-making in the current use of code generated by language models, and offers a framework for future research to further improve calibration methods for generative models in Software Engineering.
Universal Fuzzing via Large Language Models
Aug 09, 2023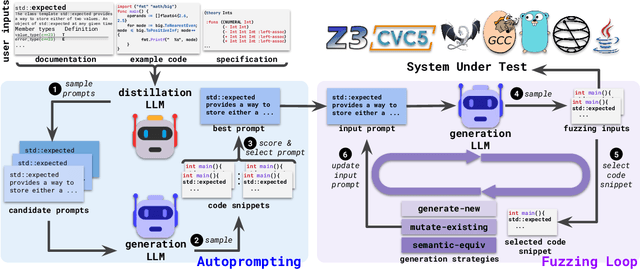


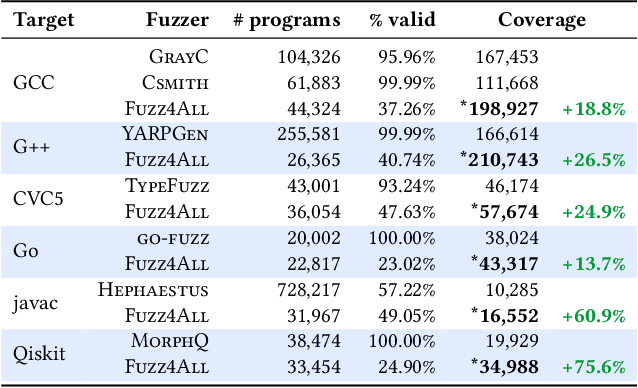
Fuzzing has achieved tremendous success in discovering bugs and vulnerabilities in various software systems. Systems under test (SUTs) that take in programming or formal language as inputs, e.g., compilers, runtime engines, constraint solvers, and software libraries with accessible APIs, are especially important as they are fundamental building blocks of software development. However, existing fuzzers for such systems often target a specific language, and thus cannot be easily applied to other languages or even other versions of the same language. Moreover, the inputs generated by existing fuzzers are often limited to specific features of the input language, and thus can hardly reveal bugs related to other or new features. This paper presents Fuzz4All, the first fuzzer that is universal in the sense that it can target many different input languages and many different features of these languages. The key idea behind Fuzz4All is to leverage large language models (LLMs) as an input generation and mutation engine, which enables the approach to produce diverse and realistic inputs for any practically relevant language. To realize this potential, we present a novel autoprompting technique, which creates LLM prompts that are wellsuited for fuzzing, and a novel LLM-powered fuzzing loop, which iteratively updates the prompt to create new fuzzing inputs. We evaluate Fuzz4All on nine systems under test that take in six different languages (C, C++, Go, SMT2, Java and Python) as inputs. The evaluation shows, across all six languages, that universal fuzzing achieves higher coverage than existing, language-specific fuzzers. Furthermore, Fuzz4All has identified 76 bugs in widely used systems, such as GCC, Clang, Z3, CVC5, OpenJDK, and the Qiskit quantum computing platform, with 47 bugs already confirmed by developers as previously unknown.
LExecutor: Learning-Guided Execution
Feb 07, 2023Executing code is essential for various program analysis tasks, e.g., to detect bugs that manifest through exceptions or to obtain execution traces for further dynamic analysis. However, executing an arbitrary piece of code is often difficult in practice, e.g., because of missing variable definitions, missing user inputs, and missing third-party dependencies. This paper presents LExecutor, a learning-guided approach for executing arbitrary code snippets in an underconstrained way. The key idea is to let a neural model predict missing values that otherwise would cause the program to get stuck, and to inject these values into the execution. For example, LExecutor injects likely values for otherwise undefined variables and likely return values of calls to otherwise missing functions. We evaluate the approach on Python code from popular open-source projects and on code snippets extracted from Stack Overflow. The neural model predicts realistic values with an accuracy between 80.1% and 94.2%, allowing LExecutor to closely mimic real executions. As a result, the approach successfully executes significantly more code than any available technique, such as simply executing the code as-is. For example, executing the open-source code snippets as-is covers only 4.1% of all lines, because the code crashes early on, whereas LExecutor achieves a coverage of 50.1%.