 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebvs. LLMs: An Empirical Study of Learning Behaviors of CS2 Students
Jan 21, 2025LLMs such as ChatGPT have been widely adopted by students in higher education as tools for learning programming and related concepts. However, it remains unclear how effective students are and what strategies students use while learning with LLMs. Since the majority of students' experiences in online self-learning have come through using search engines such as Google, evaluating AI tools in this context can help us address these gaps. In this mixed methods research, we conducted an exploratory within-subjects study to understand how CS2 students learn programming concepts using both LLMs as well as traditional online methods such as educational websites and videos to examine how students approach learning within and across both scenarios. We discovered that students found it easier to learn a more difficult concept using traditional methods than using ChatGPT. We also found that students ask fewer follow-ups and use more keyword-based queries for search engines while their prompts to LLMs tend to explicitly ask for information.
Breaking the Programming Language Barrier: Multilingual Prompting to Empower Non-Native English Learners
Dec 17, 2024


Non-native English speakers (NNES) face multiple barriers to learning programming. These barriers can be obvious, such as the fact that programming language syntax and instruction are often in English, or more subtle, such as being afraid to ask for help in a classroom full of native English speakers. However, these barriers are frustrating because many NNES students know more about programming than they can articulate in English. Advances in generative AI (GenAI) have the potential to break down these barriers because state of the art models can support interactions in multiple languages. Moreover, recent work has shown that GenAI can be highly accurate at code generation and explanation. In this paper, we provide the first exploration of NNES students prompting in their native languages (Arabic, Chinese, and Portuguese) to generate code to solve programming problems. Our results show that students are able to successfully use their native language to solve programming problems, but not without some difficulty specifying programming terminology and concepts. We discuss the challenges they faced, the implications for practice in the short term, and how this might transform computing education globally in the long term.
Quality and Trust in LLM-generated Code
Feb 09, 2024Machine learning models are widely used but can also often be wrong. Users would benefit from a reliable indication of whether a given output from a given model should be trusted, so a rational decision can be made whether to use the output or not. For example, outputs can be associated with a confidence measure; if this confidence measure is strongly associated with likelihood of correctness, then the model is said to be well-calibrated. In this case, for example, high-confidence outputs could be safely accepted, and low-confidence outputs rejected. Calibration has so far been studied in non-generative (e.g., classification) settings, especially in Software Engineering. However, generated code can quite often be wrong: Developers need to know when they should e.g., directly use, use after careful review, or discard model-generated code; thus Calibration is vital in generative settings. However, the notion of correctness of generated code is non-trivial, and thus so is Calibration. In this paper we make several contributions. We develop a framework for evaluating the Calibration of code-generating models. We consider several tasks, correctness criteria, datasets, and approaches, and find that by and large generative code models are not well-calibrated out of the box. We then show how Calibration can be improved, using standard methods such as Platt scaling. Our contributions will lead to better-calibrated decision-making in the current use of code generated by language models, and offers a framework for future research to further improve calibration methods for generative models in Software Engineering.
Question Relatedness on Stack Overflow: The Task, Dataset, and Corpus-inspired Models
May 07, 2019
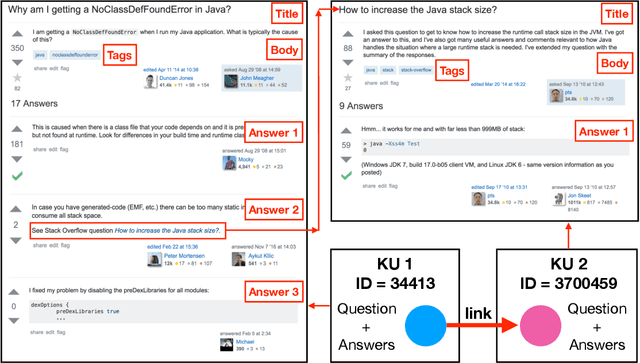
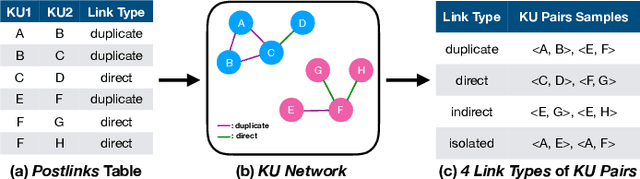

Domain-specific community question answering is becoming an integral part of professions. Finding related questions and answers in these communities can significantly improve the effectiveness and efficiency of information seeking. Stack Overflow is one of the most popular communities that is being used by millions of programmers. In this paper, we analyze the problem of predicting knowledge unit (question thread) relatedness in Stack Overflow. In particular, we formulate the question relatedness task as a multi-class classification problem with four degrees of relatedness. We present a large-scale dataset with more than 300K pairs. To the best of our knowledge, this dataset is the largest domain-specific dataset for Question-Question relatedness. We present the steps that we took to collect, clean, process, and assure the quality of the dataset. The proposed dataset Stack Overflow is a useful resource to develop novel solutions, specifically data-hungry neural network models, for the prediction of relatedness in technical community question-answering forums. We adopt a neural network architecture and a traditional model for this task that effectively utilize information from different parts of knowledge units to compute the relatedness between them. These models can be used to benchmark novel models, as they perform well in our task and in a closely similar task.