 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel See, Model Do? Exposure-Aware Evaluation of Bug-vs-Fix Preference in Code LLMs
Jan 15, 2026Large language models are increasingly used for code generation and debugging, but their outputs can still contain bugs, that originate from training data. Distinguishing whether an LLM prefers correct code, or a familiar incorrect version might be influenced by what it's been exposed to during training. We introduce an exposure-aware evaluation framework that quantifies how prior exposure to buggy versus fixed code influences a model's preference. Using the ManySStuBs4J benchmark, we apply Data Portraits for membership testing on the Stack-V2 corpus to estimate whether each buggy and fixed variant was seen during training. We then stratify examples by exposure and compare model preference using code completion as well as multiple likelihood-based scoring metrics We find that most examples (67%) have neither variant in the training data, and when only one is present, fixes are more frequently present than bugs. In model generations, models reproduce buggy lines far more often than fixes, with bug-exposed examples amplifying this tendency and fix-exposed examples showing only marginal improvement. In likelihood scoring, minimum and maximum token-probability metrics consistently prefer the fixed code across all conditions, indicating a stable bias toward correct fixes. In contrast, metrics like the Gini coefficient reverse preference when only the buggy variant was seen. Our results indicate that exposure can skew bug-fix evaluations and highlight the risk that LLMs may propagate memorised errors in practice.
Do LLMs Trust the Code They Write?
Dec 08, 2025
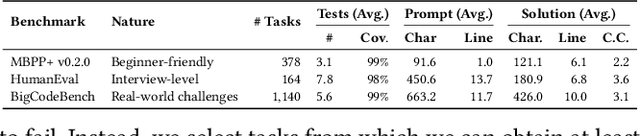
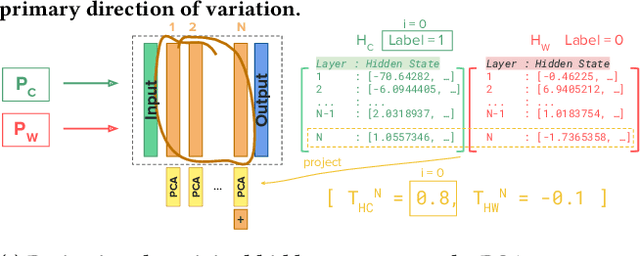
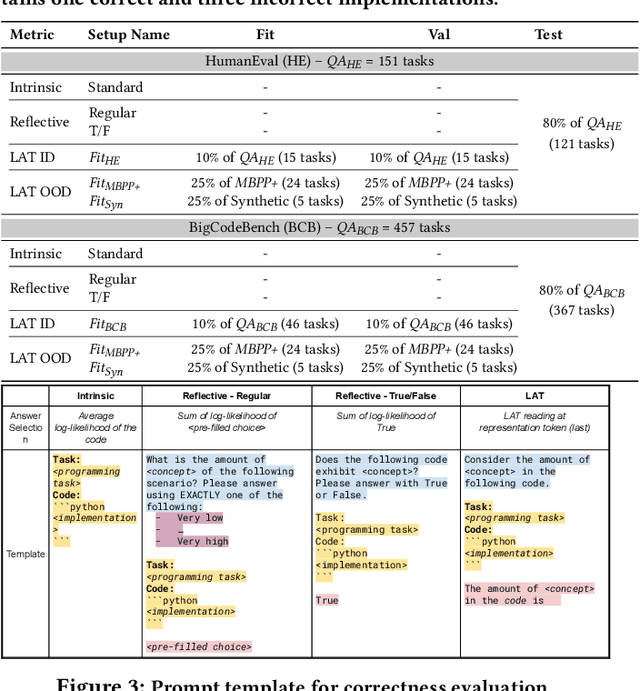
Despite the effectiveness of large language models (LLMs) for code generation, they often output incorrect code. One reason is that model output probabilities are often not well-correlated with correctness, and reflect only the final output of the generation process. Inspired by findings that LLMs internally encode concepts like truthfulness, this paper explores if LLMs similarly represent code correctness. Specifically, we identify a correctness representation inside LLMs by contrasting the hidden states between pairs of correct and incorrect code for the same programming tasks. By experimenting on four LLMs, we show that exploiting this extracted correctness representation outperforms standard log-likelihood ranking, as well as verbalized model confidence. Furthermore, we explore how this internal correctness signal can be used to select higher-quality code samples, without requiring test execution. Ultimately, this work demonstrates how leveraging internal representations can enhance code generation systems and make LLMs more reliable, thus improving confidence in automatically generated code.
Does In-IDE Calibration of Large Language Models work at Scale?
Oct 26, 2025



The introduction of large language models into integrated development environments (IDEs) is revolutionizing software engineering, yet it poses challenges to the usefulness and reliability of Artificial Intelligence-generated code. Post-hoc calibration of internal model confidences aims to align probabilities with an acceptability measure. Prior work suggests calibration can improve alignment, but at-scale evidence is limited. In this work, we investigate the feasibility of applying calibration of code models to an in-IDE context. We study two aspects of the problem: (1) the technical method for implementing confidence calibration and improving the reliability of code generation models, and (2) the human-centered design principles for effectively communicating reliability signal to developers. First, we develop a scalable and flexible calibration framework which can be used to obtain calibration weights for open-source models using any dataset, and evaluate whether calibrators improve the alignment between model confidence and developer acceptance behavior. Through a large-scale analysis of over 24 million real-world developer interactions across multiple programming languages, we find that a general, post-hoc calibration model based on Platt-scaling does not, on average, improve the reliability of model confidence signals. We also find that while dynamically personalizing calibration to individual users can be effective, its effectiveness is highly dependent on the volume of user interaction data. Second, we conduct a multi-phase design study with 3 expert designers and 153 professional developers, combining scenario-based design, semi-structured interviews, and survey validation, revealing a clear preference for presenting reliability signals via non-numerical, color-coded indicators within the in-editor code generation workflow.
AutoPDL: Automatic Prompt Optimization for LLM Agents
Apr 06, 2025



The performance of large language models (LLMs) depends on how they are prompted, with choices spanning both the high-level prompting pattern (e.g., Zero-Shot, CoT, ReAct, ReWOO) and the specific prompt content (instructions and few-shot demonstrations). Manually tuning this combination is tedious, error-prone, and non-transferable across LLMs or tasks. Therefore, this paper proposes AutoPDL, an automated approach to discover good LLM agent configurations. Our method frames this as a structured AutoML problem over a combinatorial space of agentic and non-agentic prompting patterns and demonstrations, using successive halving to efficiently navigate this space. We introduce a library implementing common prompting patterns using the PDL prompt programming language. AutoPDL solutions are human-readable, editable, and executable PDL programs that use this library. This approach also enables source-to-source optimization, allowing human-in-the-loop refinement and reuse. Evaluations across three tasks and six LLMs (ranging from 8B to 70B parameters) show consistent accuracy gains ($9.5\pm17.5$ percentage points), up to 68.9pp, and reveal that selected prompting strategies vary across models and tasks.
PDL: A Declarative Prompt Programming Language
Oct 24, 2024



Large language models (LLMs) have taken the world by storm by making many previously difficult uses of AI feasible. LLMs are controlled via highly expressive textual prompts and return textual answers. Unfortunately, this unstructured text as input and output makes LLM-based applications brittle. This motivates the rise of prompting frameworks, which mediate between LLMs and the external world. However, existing prompting frameworks either have a high learning curve or take away control over the exact prompts from the developer. To overcome this dilemma, this paper introduces the Prompt Declaration Language (PDL). PDL is a simple declarative data-oriented language that puts prompts at the forefront, based on YAML. PDL works well with many LLM platforms and LLMs. It supports writing interactive applications that call LLMs and tools, and makes it easy to implement common use-cases such as chatbots, RAG, or agents. We hope PDL will make prompt programming simpler, less brittle, and more enjoyable.
Quality and Trust in LLM-generated Code
Feb 09, 2024



Machine learning models are widely used but can also often be wrong. Users would benefit from a reliable indication of whether a given output from a given model should be trusted, so a rational decision can be made whether to use the output or not. For example, outputs can be associated with a confidence measure; if this confidence measure is strongly associated with likelihood of correctness, then the model is said to be well-calibrated. In this case, for example, high-confidence outputs could be safely accepted, and low-confidence outputs rejected. Calibration has so far been studied in non-generative (e.g., classification) settings, especially in Software Engineering. However, generated code can quite often be wrong: Developers need to know when they should e.g., directly use, use after careful review, or discard model-generated code; thus Calibration is vital in generative settings. However, the notion of correctness of generated code is non-trivial, and thus so is Calibration. In this paper we make several contributions. We develop a framework for evaluating the Calibration of code-generating models. We consider several tasks, correctness criteria, datasets, and approaches, and find that by and large generative code models are not well-calibrated out of the box. We then show how Calibration can be improved, using standard methods such as Platt scaling. Our contributions will lead to better-calibrated decision-making in the current use of code generated by language models, and offers a framework for future research to further improve calibration methods for generative models in Software Engineering.
STraceBERT: Source Code Retrieval using Semantic Application Traces
Dec 07, 2023

Software reverse engineering is an essential task in software engineering and security, but it can be a challenging process, especially for adversarial artifacts. To address this challenge, we present STraceBERT, a novel approach that utilizes a Java dynamic analysis tool to record calls to core Java libraries, and pretrain a BERT-style model on the recorded application traces for effective method source code retrieval from a candidate set. Our experiments demonstrate the effectiveness of STraceBERT in retrieving the source code compared to existing approaches. Our proposed approach offers a promising solution to the problem of code retrieval in software reverse engineering and opens up new avenues for further research in this area.