 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresenting Prompting Patterns with PDL: Compliance Agent Case Study
Jul 08, 2025Prompt engineering for LLMs remains complex, with existing frameworks either hiding complexity behind restrictive APIs or providing inflexible canned patterns that resist customization -- making sophisticated agentic programming challenging. We present the Prompt Declaration Language (PDL), a novel approach to prompt representation that tackles this fundamental complexity by bringing prompts to the forefront, enabling manual and automatic prompt tuning while capturing the composition of LLM calls together with rule-based code and external tools. By abstracting away the plumbing for such compositions, PDL aims at improving programmer productivity while providing a declarative representation that is amenable to optimization. This paper demonstrates PDL's utility through a real-world case study of a compliance agent. Tuning the prompting pattern of this agent yielded up to 4x performance improvement compared to using a canned agent and prompt pattern.
AutoPDL: Automatic Prompt Optimization for LLM Agents
Apr 06, 2025



The performance of large language models (LLMs) depends on how they are prompted, with choices spanning both the high-level prompting pattern (e.g., Zero-Shot, CoT, ReAct, ReWOO) and the specific prompt content (instructions and few-shot demonstrations). Manually tuning this combination is tedious, error-prone, and non-transferable across LLMs or tasks. Therefore, this paper proposes AutoPDL, an automated approach to discover good LLM agent configurations. Our method frames this as a structured AutoML problem over a combinatorial space of agentic and non-agentic prompting patterns and demonstrations, using successive halving to efficiently navigate this space. We introduce a library implementing common prompting patterns using the PDL prompt programming language. AutoPDL solutions are human-readable, editable, and executable PDL programs that use this library. This approach also enables source-to-source optimization, allowing human-in-the-loop refinement and reuse. Evaluations across three tasks and six LLMs (ranging from 8B to 70B parameters) show consistent accuracy gains ($9.5\pm17.5$ percentage points), up to 68.9pp, and reveal that selected prompting strategies vary across models and tasks.
PDL: A Declarative Prompt Programming Language
Oct 24, 2024



Large language models (LLMs) have taken the world by storm by making many previously difficult uses of AI feasible. LLMs are controlled via highly expressive textual prompts and return textual answers. Unfortunately, this unstructured text as input and output makes LLM-based applications brittle. This motivates the rise of prompting frameworks, which mediate between LLMs and the external world. However, existing prompting frameworks either have a high learning curve or take away control over the exact prompts from the developer. To overcome this dilemma, this paper introduces the Prompt Declaration Language (PDL). PDL is a simple declarative data-oriented language that puts prompts at the forefront, based on YAML. PDL works well with many LLM platforms and LLMs. It supports writing interactive applications that call LLMs and tools, and makes it easy to implement common use-cases such as chatbots, RAG, or agents. We hope PDL will make prompt programming simpler, less brittle, and more enjoyable.
Inference Plans for Hybrid Particle Filtering
Aug 21, 2024



Advanced probabilistic programming languages (PPLs) use hybrid inference systems to combine symbolic exact inference and Monte Carlo methods to improve inference performance. These systems use heuristics to partition random variables within the program into variables that are encoded symbolically and variables that are encoded with sampled values, and the heuristics are not necessarily aligned with the performance evaluation metrics used by the developer. In this work, we present inference plans, a programming interface that enables developers to control the partitioning of random variables during hybrid particle filtering. We further present Siren, a new PPL that enables developers to use annotations to specify inference plans the inference system must implement. To assist developers with statically reasoning about whether an inference plan can be implemented, we present an abstract-interpretation-based static analysis for Siren for determining inference plan satisfiability. We prove the analysis is sound with respect to Siren's semantics. Our evaluation applies inference plans to three different hybrid particle filtering algorithms on a suite of benchmarks and shows that the control provided by inference plans enables speed ups of 1.76x on average and up to 206x to reach target accuracy, compared to the inference plans implemented by default heuristics; the results also show that inference plans improve accuracy by 1.83x on average and up to 595x with less or equal runtime, compared to the default inference plans. We further show that the static analysis is precise in practice, identifying all satisfiable inference plans in 27 out of the 33 benchmark-algorithm combinations.
Ansible Lightspeed: A Code Generation Service for IT Automation
Feb 27, 2024



The availability of Large Language Models (LLMs) which can generate code, has made it possible to create tools that improve developer productivity. Integrated development environments or IDEs which developers use to write software are often used as an interface to interact with LLMs. Although many such tools have been released, almost all of them focus on general-purpose programming languages. Domain-specific languages, such as those crucial for IT automation, have not received much attention. Ansible is one such YAML-based IT automation-specific language. Red Hat Ansible Lightspeed with IBM Watson Code Assistant, further referred to as Ansible Lightspeed, is an LLM-based service designed explicitly for natural language to Ansible code generation. In this paper, we describe the design and implementation of the Ansible Lightspeed service and analyze feedback from thousands of real users. We examine diverse performance indicators, classified according to both immediate and extended utilization patterns along with user sentiments. The analysis shows that the user acceptance rate of Ansible Lightspeed suggestions is higher than comparable tools that are more general and not specific to a programming language. This remains true even after we use much more stringent criteria for what is considered an accepted model suggestion, discarding suggestions which were heavily edited after being accepted. The relatively high acceptance rate results in higher-than-expected user retention and generally positive user feedback. This paper provides insights on how a comparatively small, dedicated model performs on a domain-specific language and more importantly, how it is received by users.
Learning Transfers over Several Programming Languages
Oct 25, 2023



Large language models (LLMs) have recently become remarkably good at improving developer productivity for high-resource programming languages. These models use two kinds of data: large amounts of unlabeled code samples for pretraining and relatively smaller amounts of labeled code samples for fine-tuning or in-context learning. Unfortunately, many programming languages are low-resource, lacking labeled samples for most tasks and often even lacking unlabeled samples. Therefore, users of low-resource languages (e.g., legacy or new languages) miss out on the benefits of LLMs. Cross-lingual transfer learning uses data from a source language to improve model performance on a target language. It has been well-studied for natural languages, but has received little attention for programming languages. This paper reports extensive experiments on four tasks using a transformer-based LLM and 11 to 41 programming languages to explore the following questions. First, how well cross-lingual transfer works for a given task across different language pairs. Second, given a task and target language, how to best choose a source language. Third, the characteristics of a language pair that are predictive of transfer performance, and fourth, how that depends on the given task.
Learning GraphQL Query Costs (Extended Version)
Aug 26, 2021
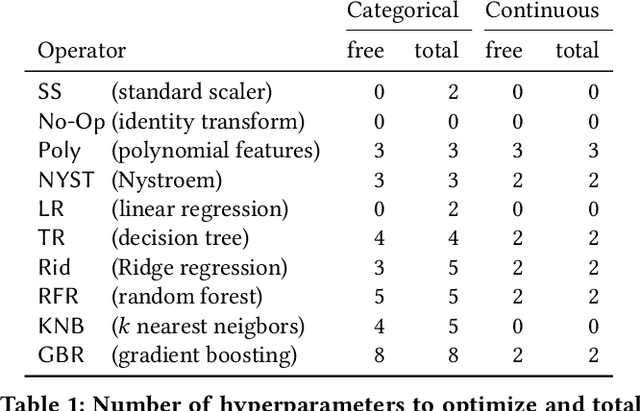
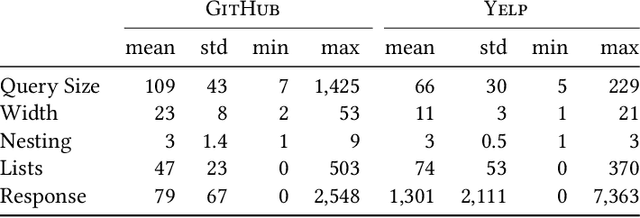

GraphQL is a query language for APIs and a runtime for executing those queries, fetching the requested data from existing microservices, REST APIs, databases, or other sources. Its expressiveness and its flexibility have made it an attractive candidate for API providers in many industries, especially through the web. A major drawback to blindly servicing a client's query in GraphQL is that the cost of a query can be unexpectedly large, creating computation and resource overload for the provider, and API rate-limit overages and infrastructure overload for the client. To mitigate these drawbacks, it is necessary to efficiently estimate the cost of a query before executing it. Estimating query cost is challenging, because GraphQL queries have a nested structure, GraphQL APIs follow different design conventions, and the underlying data sources are hidden. Estimates based on worst-case static query analysis have had limited success because they tend to grossly overestimate cost. We propose a machine-learning approach to efficiently and accurately estimate the query cost. We also demonstrate the power of this approach by testing it on query-response data from publicly available commercial APIs. Our framework is efficient and predicts query costs with high accuracy, consistently outperforming the static analysis by a large margin.
Extending Stan for Deep Probabilistic Programming
Sep 30, 2018
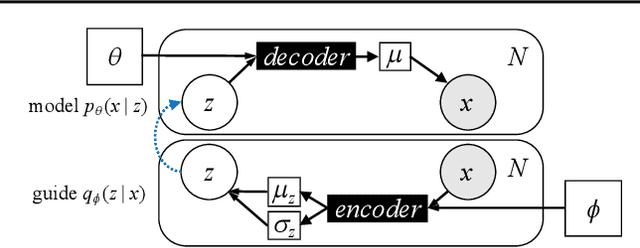

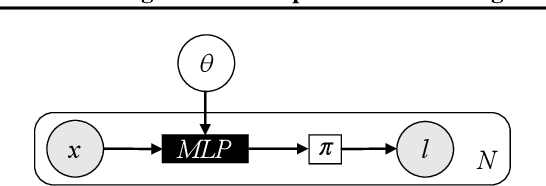
Deep probabilistic programming combines deep neural networks (for automatic hierarchical representation learning) with probabilistic models (for principled handling of uncertainty). Unfortunately, it is difficult to write deep probabilistic models, because existing programming frameworks lack concise, high-level, and clean ways to express them. To ease this task, we extend Stan, a popular high-level probabilistic programming language, to use deep neural networks written in PyTorch. Training deep probabilistic models works best with variational inference, so we also extend Stan for that. We implement these extensions by translating Stan programs to Pyro. Our translation clarifies the relationship between different families of probabilistic programming languages. Overall, our paper is a step towards making deep probabilistic programming easier.
Deep Probabilistic Programming Languages: A Qualitative Study
Apr 17, 2018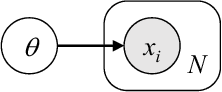

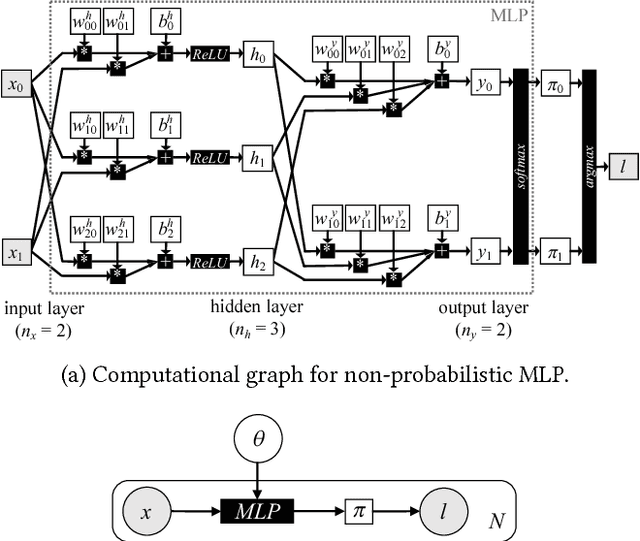

Deep probabilistic programming languages try to combine the advantages of deep learning with those of probabilistic programming languages. If successful, this would be a big step forward in machine learning and programming languages. Unfortunately, as of now, this new crop of languages is hard to use and understand. This paper addresses this problem directly by explaining deep probabilistic programming languages and indirectly by characterizing their current strengths and weaknesses.