 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharing State Between Prompts and Programs
Dec 16, 2025The rise of large language models (LLMs) has introduced a new type of programming: natural language programming. By writing prompts that direct LLMs to perform natural language processing, code generation, reasoning, etc., users are writing code in natural language -- natural language code -- for the LLM to execute. An emerging area of research enables interoperability between natural language code and formal languages such as Python. We present a novel programming abstraction, shared program state, that removes the manual work required to enable interoperability between natural language code and program state. With shared program state, programmers can write natural code that directly writes program variables, computes with program objects, and implements control flow in the program. We present a schema for specifying natural function interfaces that extend programming systems to support natural code and leverage this schema to specify shared program state as a natural function interface. We implement shared program state in the Nightjar programming system. Nightjar enables programmers to write Python programs that contain natural code that shares the Python program state. We show that Nightjar programs achieve comparable or higher task accuracy than manually written implementations (+4-19%), while decreasing the lines of code by 39.6% on average. The tradeoff to using Nightjar is that it may incur runtime overhead (0.4-4.3x runtime of manual implementations).
Retrieval Capabilities of Large Language Models Scale with Pretraining FLOPs
Aug 24, 2025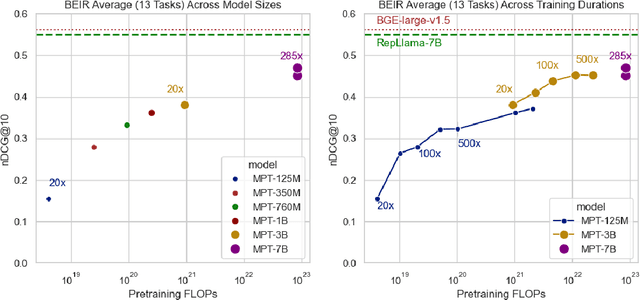


How does retrieval performance scale with pretraining FLOPs? We benchmark retrieval performance across LLM model sizes from 125 million parameters to 7 billion parameters pretrained on datasets ranging from 1 billion tokens to more than 2 trillion tokens. We find that retrieval performance on zero-shot BEIR tasks predictably scales with LLM size, training duration, and estimated FLOPs. We also show that In-Context Learning scores are strongly correlated with retrieval scores across retrieval tasks. Finally, we highlight the implications this has for the development of LLM-based retrievers.
FreshStack: Building Realistic Benchmarks for Evaluating Retrieval on Technical Documents
Apr 17, 2025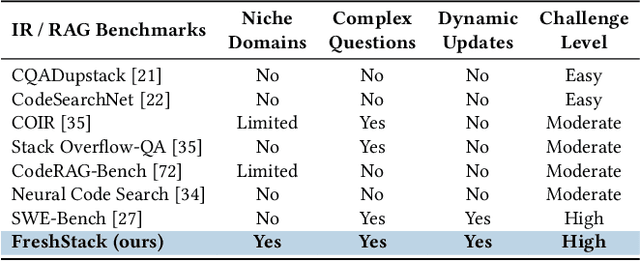
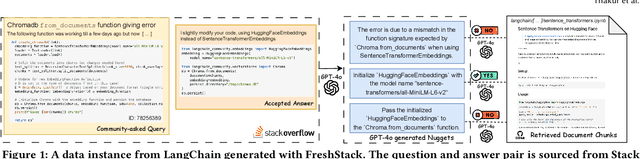
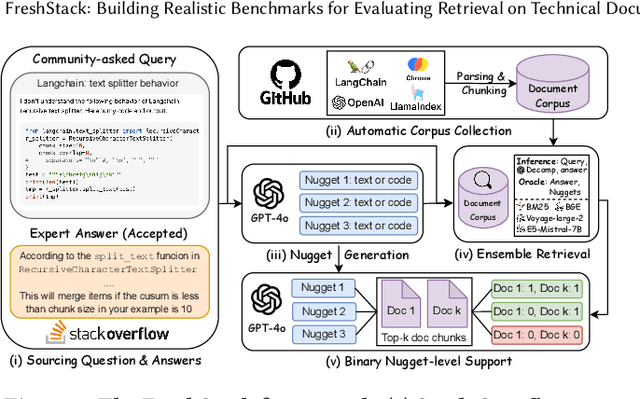

We introduce FreshStack, a reusable framework for automatically building information retrieval (IR) evaluation benchmarks from community-asked questions and answers. FreshStack conducts the following steps: (1) automatic corpus collection from code and technical documentation, (2) nugget generation from community-asked questions and answers, and (3) nugget-level support, retrieving documents using a fusion of retrieval techniques and hybrid architectures. We use FreshStack to build five datasets on fast-growing, recent, and niche topics to ensure the tasks are sufficiently challenging. On FreshStack, existing retrieval models, when applied out-of-the-box, significantly underperform oracle approaches on all five topics, denoting plenty of headroom to improve IR quality. In addition, we identify cases where rerankers do not clearly improve first-stage retrieval accuracy (two out of five topics). We hope that FreshStack will facilitate future work toward constructing realistic, scalable, and uncontaminated IR and RAG evaluation benchmarks. FreshStack datasets are available at: https://fresh-stack.github.io.
Learning to Keep a Promise: Scaling Language Model Decoding Parallelism with Learned Asynchronous Decoding
Feb 17, 2025

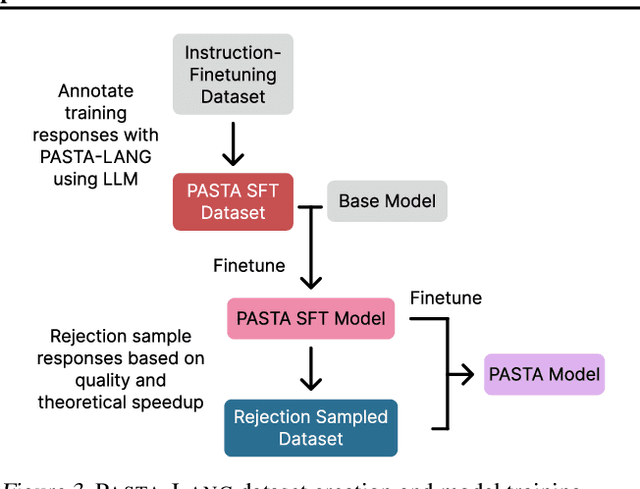
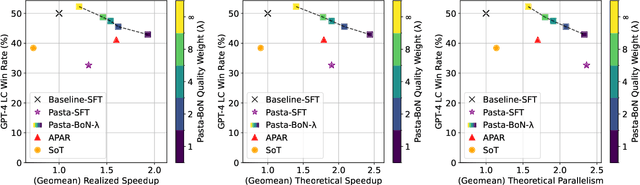
Decoding with autoregressive large language models (LLMs) traditionally occurs sequentially, generating one token after another. An emerging line of work explored parallel decoding by identifying and simultaneously generating semantically independent chunks of LLM responses. However, these techniques rely on hand-crafted heuristics tied to syntactic structures like lists and paragraphs, making them rigid and imprecise. We present PASTA, a learning-based system that teaches LLMs to identify semantic independence and express parallel decoding opportunities in their own responses. At its core are PASTA-LANG and its interpreter: PASTA-LANG is an annotation language that enables LLMs to express semantic independence in their own responses; the language interpreter acts on these annotations to orchestrate parallel decoding on-the-fly at inference time. Through a two-stage finetuning process, we train LLMs to generate PASTA-LANG annotations that optimize both response quality and decoding speed. Evaluation on AlpacaEval, an instruction following benchmark, shows that our approach Pareto-dominates existing methods in terms of decoding speed and response quality; our results demonstrate geometric mean speedups ranging from 1.21x to 1.93x with corresponding quality changes of +2.2% to -7.1%, measured by length-controlled win rates against sequential decoding baseline.
Drowning in Documents: Consequences of Scaling Reranker Inference
Nov 18, 2024



Rerankers, typically cross-encoders, are often used to re-score the documents retrieved by cheaper initial IR systems. This is because, though expensive, rerankers are assumed to be more effective. We challenge this assumption by measuring reranker performance for full retrieval, not just re-scoring first-stage retrieval. Our experiments reveal a surprising trend: the best existing rerankers provide diminishing returns when scoring progressively more documents and actually degrade quality beyond a certain limit. In fact, in this setting, rerankers can frequently assign high scores to documents with no lexical or semantic overlap with the query. We hope that our findings will spur future research to improve reranking.
Long Context RAG Performance of Large Language Models
Nov 05, 2024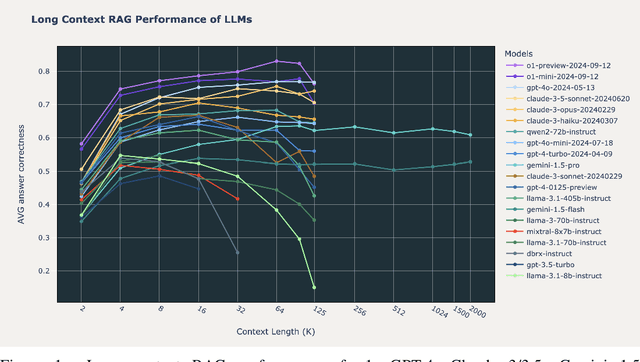
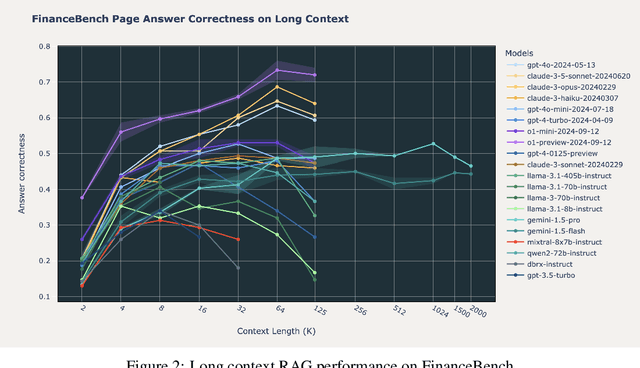
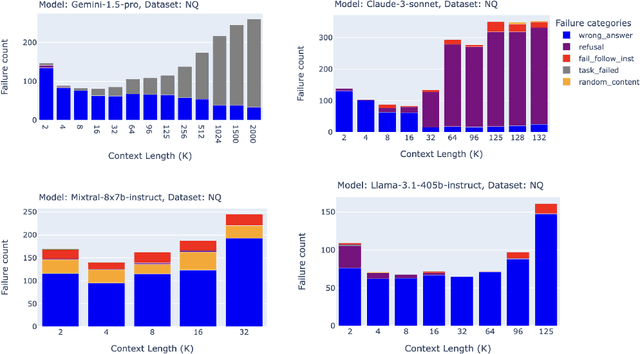
Retrieval Augmented Generation (RAG) has emerged as a crucial technique for enhancing the accuracy of Large Language Models (LLMs) by incorporating external information. With the advent of LLMs that support increasingly longer context lengths, there is a growing interest in understanding how these models perform in RAG scenarios. Can these new long context models improve RAG performance? This paper presents a comprehensive study of the impact of increased context length on RAG performance across 20 popular open source and commercial LLMs. We ran RAG workflows while varying the total context length from 2,000 to 128,000 tokens (and 2 million tokens when possible) on three domain-specific datasets, and report key insights on the benefits and limitations of long context in RAG applications. Our findings reveal that while retrieving more documents can improve performance, only a handful of the most recent state of the art LLMs can maintain consistent accuracy at long context above 64k tokens. We also identify distinct failure modes in long context scenarios, suggesting areas for future research.
Inference Plans for Hybrid Particle Filtering
Aug 21, 2024



Advanced probabilistic programming languages (PPLs) use hybrid inference systems to combine symbolic exact inference and Monte Carlo methods to improve inference performance. These systems use heuristics to partition random variables within the program into variables that are encoded symbolically and variables that are encoded with sampled values, and the heuristics are not necessarily aligned with the performance evaluation metrics used by the developer. In this work, we present inference plans, a programming interface that enables developers to control the partitioning of random variables during hybrid particle filtering. We further present Siren, a new PPL that enables developers to use annotations to specify inference plans the inference system must implement. To assist developers with statically reasoning about whether an inference plan can be implemented, we present an abstract-interpretation-based static analysis for Siren for determining inference plan satisfiability. We prove the analysis is sound with respect to Siren's semantics. Our evaluation applies inference plans to three different hybrid particle filtering algorithms on a suite of benchmarks and shows that the control provided by inference plans enables speed ups of 1.76x on average and up to 206x to reach target accuracy, compared to the inference plans implemented by default heuristics; the results also show that inference plans improve accuracy by 1.83x on average and up to 595x with less or equal runtime, compared to the default inference plans. We further show that the static analysis is precise in practice, identifying all satisfiable inference plans in 27 out of the 33 benchmark-algorithm combinations.
Learning to Compile Programs to Neural Networks
Jul 21, 2024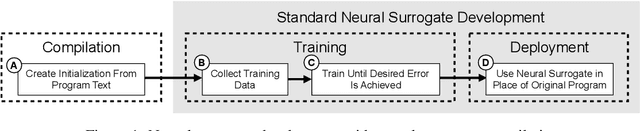

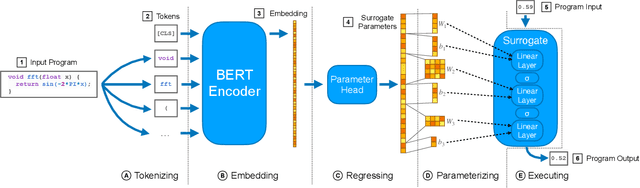
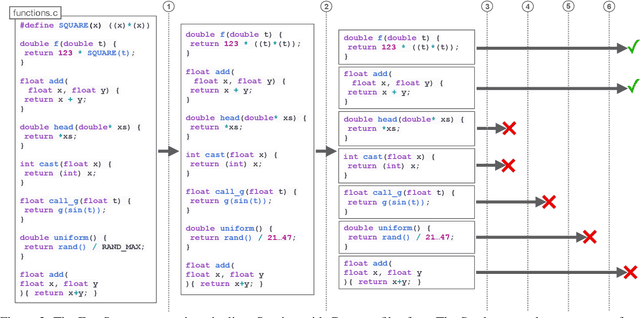
A $\textit{neural surrogate of a program}$ is a neural network that mimics the behavior of a program. Researchers have used these neural surrogates to automatically tune program inputs, adapt programs to new settings, and accelerate computations. Researchers traditionally develop neural surrogates by training on input-output examples from a single program. Alternatively, language models trained on a large dataset including many programs can consume program text, to act as a neural surrogate. Using a language model to both generate a surrogate and act as a surrogate, however, leading to a trade-off between resource consumption and accuracy. We present $\textit{neural surrogate compilation}$, a technique for producing neural surrogates directly from program text without coupling neural surrogate generation and execution. We implement neural surrogate compilers using hypernetworks trained on a dataset of C programs and find that they produce neural surrogates that are $1.9$-$9.5\times$ as data-efficient, produce visual results that are $1.0$-$1.3\times$ more similar to ground truth, and train in $4.3$-$7.3\times$ fewer epochs than neural surrogates trained from scratch.
BioMedLM: A 2.7B Parameter Language Model Trained On Biomedical Text
Mar 27, 2024Models such as GPT-4 and Med-PaLM 2 have demonstrated impressive performance on a wide variety of biomedical NLP tasks. However, these models have hundreds of billions of parameters, are computationally expensive to run, require users to send their input data over the internet, and are trained on unknown data sources. Can smaller, more targeted models compete? To address this question, we build and release BioMedLM, a 2.7 billion parameter GPT-style autoregressive model trained exclusively on PubMed abstracts and full articles. When fine-tuned, BioMedLM can produce strong multiple-choice biomedical question-answering results competitive with much larger models, such as achieving a score of 57.3% on MedMCQA (dev) and 69.0% on the MMLU Medical Genetics exam. BioMedLM can also be fine-tuned to produce useful answers to patient questions on medical topics. This demonstrates that smaller models can potentially serve as transparent, privacy-preserving, economical and environmentally friendly foundations for particular NLP applications, such as in biomedicine. The model is available on the Hugging Face Hub: https://huggingface.co/stanford-crfm/BioMedLM.
The Cost of Down-Scaling Language Models: Fact Recall Deteriorates before In-Context Learning
Oct 07, 2023



How does scaling the number of parameters in large language models (LLMs) affect their core capabilities? We study two natural scaling techniques -- weight pruning and simply training a smaller or larger model, which we refer to as dense scaling -- and their effects on two core capabilities of LLMs: (a) recalling facts presented during pre-training and (b) processing information presented in-context during inference. By curating a suite of tasks that help disentangle these two capabilities, we find a striking difference in how these two abilities evolve due to scaling. Reducing the model size by more than 30\% (via either scaling approach) significantly decreases the ability to recall facts seen in pre-training. Yet, a 60--70\% reduction largely preserves the various ways the model can process in-context information, ranging from retrieving answers from a long context to learning parameterized functions from in-context exemplars. The fact that both dense scaling and weight pruning exhibit this behavior suggests that scaling model size has an inherently disparate effect on fact recall and in-context learning.