 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Capabilities of Large Language Models Scale with Pretraining FLOPs
Aug 24, 2025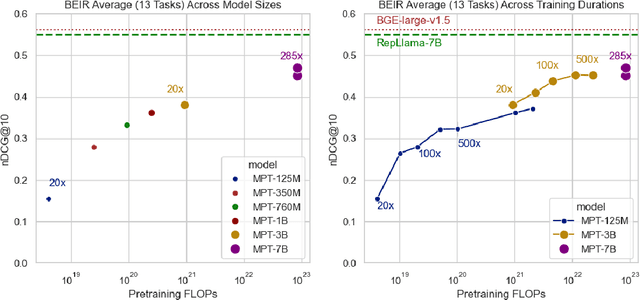
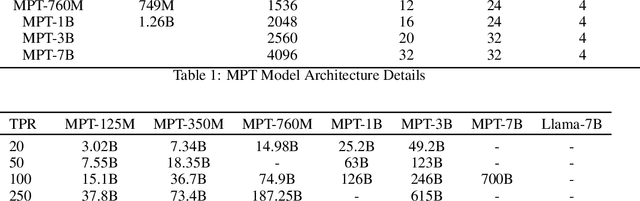


How does retrieval performance scale with pretraining FLOPs? We benchmark retrieval performance across LLM model sizes from 125 million parameters to 7 billion parameters pretrained on datasets ranging from 1 billion tokens to more than 2 trillion tokens. We find that retrieval performance on zero-shot BEIR tasks predictably scales with LLM size, training duration, and estimated FLOPs. We also show that In-Context Learning scores are strongly correlated with retrieval scores across retrieval tasks. Finally, we highlight the implications this has for the development of LLM-based retrievers.
Long Context RAG Performance of Large Language Models
Nov 05, 2024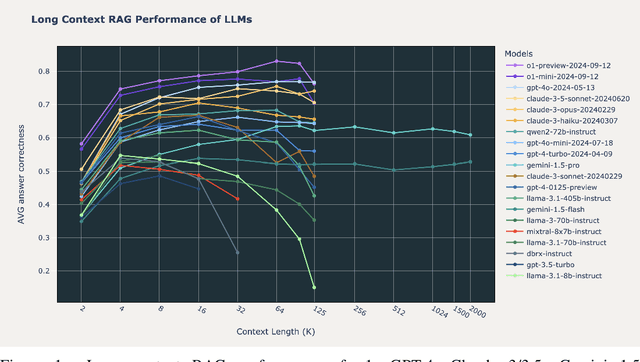
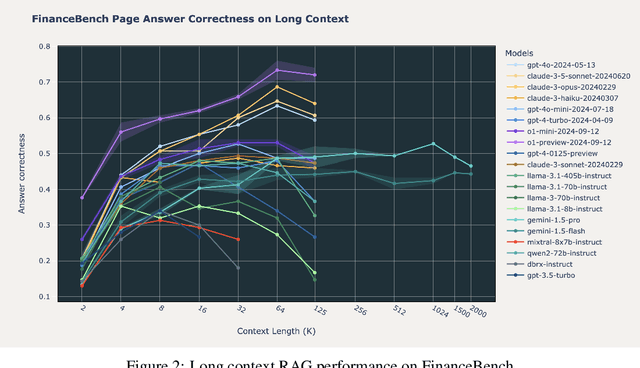
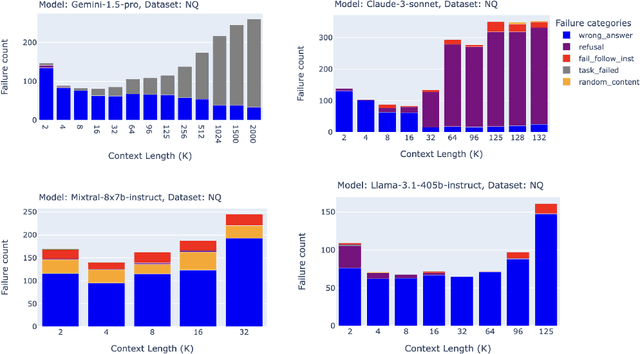
Retrieval Augmented Generation (RAG) has emerged as a crucial technique for enhancing the accuracy of Large Language Models (LLMs) by incorporating external information. With the advent of LLMs that support increasingly longer context lengths, there is a growing interest in understanding how these models perform in RAG scenarios. Can these new long context models improve RAG performance? This paper presents a comprehensive study of the impact of increased context length on RAG performance across 20 popular open source and commercial LLMs. We ran RAG workflows while varying the total context length from 2,000 to 128,000 tokens (and 2 million tokens when possible) on three domain-specific datasets, and report key insights on the benefits and limitations of long context in RAG applications. Our findings reveal that while retrieving more documents can improve performance, only a handful of the most recent state of the art LLMs can maintain consistent accuracy at long context above 64k tokens. We also identify distinct failure modes in long context scenarios, suggesting areas for future research.
LoRA Learns Less and Forgets Less
May 15, 2024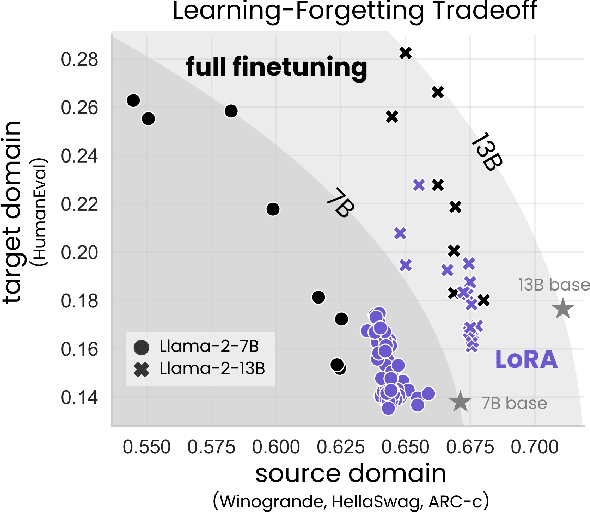

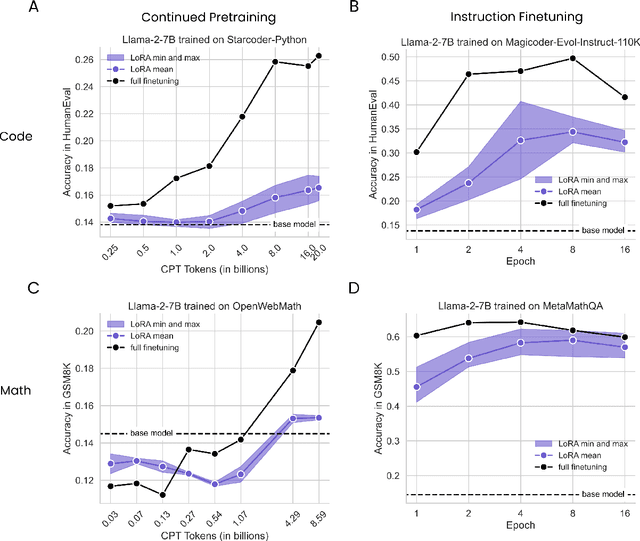

Low-Rank Adaptation (LoRA) is a widely-used parameter-efficient finetuning method for large language models. LoRA saves memory by training only low rank perturbations to selected weight matrices. In this work, we compare the performance of LoRA and full finetuning on two target domains, programming and mathematics. We consider both the instruction finetuning ($\approx$100K prompt-response pairs) and continued pretraining ($\approx$10B unstructured tokens) data regimes. Our results show that, in most settings, LoRA substantially underperforms full finetuning. Nevertheless, LoRA exhibits a desirable form of regularization: it better maintains the base model's performance on tasks outside the target domain. We show that LoRA provides stronger regularization compared to common techniques such as weight decay and dropout; it also helps maintain more diverse generations. We show that full finetuning learns perturbations with a rank that is 10-100X greater than typical LoRA configurations, possibly explaining some of the reported gaps. We conclude by proposing best practices for finetuning with LoRA.
MosaicBERT: A Bidirectional Encoder Optimized for Fast Pretraining
Jan 16, 2024



Although BERT-style encoder models are heavily used in NLP research, many researchers do not pretrain their own BERTs from scratch due to the high cost of training. In the past half-decade since BERT first rose to prominence, many advances have been made with other transformer architectures and training configurations that have yet to be systematically incorporated into BERT. Here, we introduce MosaicBERT, a BERT-style encoder architecture and training recipe that is empirically optimized for fast pretraining. This efficient architecture incorporates FlashAttention, Attention with Linear Biases (ALiBi), Gated Linear Units (GLU), a module to dynamically remove padded tokens, and low precision LayerNorm into the classic transformer encoder block. The training recipe includes a 30% masking ratio for the Masked Language Modeling (MLM) objective, bfloat16 precision, and vocabulary size optimized for GPU throughput, in addition to best-practices from RoBERTa and other encoder models. When pretrained from scratch on the C4 dataset, this base model achieves a downstream average GLUE (dev) score of 79.6 in 1.13 hours on 8 A100 80 GB GPUs at a cost of roughly $20. We plot extensive accuracy vs. pretraining speed Pareto curves and show that MosaicBERT base and large are consistently Pareto optimal when compared to a competitive BERT base and large. This empirical speed up in pretraining enables researchers and engineers to pretrain custom BERT-style models at low cost instead of finetune on existing generic models. We open source our model weights and code.
* 10 pages, 4 figures in main text. 25 pages total
LIMIT: Less Is More for Instruction Tuning Across Evaluation Paradigms
Nov 22, 2023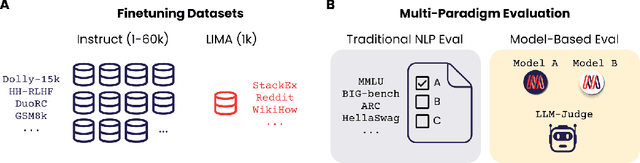

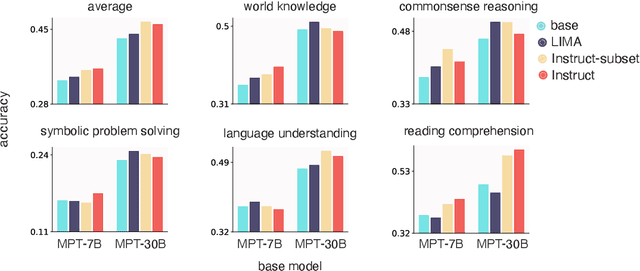
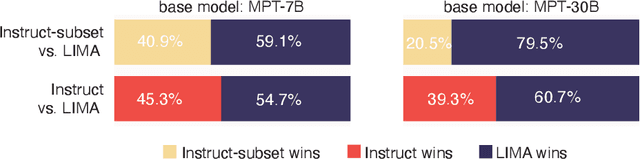
Large Language Models are traditionally finetuned on large instruction datasets. However recent studies suggest that small, high-quality datasets can suffice for general purpose instruction following. This lack of consensus surrounding finetuning best practices is in part due to rapidly diverging approaches to LLM evaluation. In this study, we ask whether a small amount of diverse finetuning samples can improve performance on both traditional perplexity-based NLP benchmarks, and on open-ended, model-based evaluation. We finetune open-source MPT-7B and MPT-30B models on instruction finetuning datasets of various sizes ranging from 1k to 60k samples. We find that subsets of 1k-6k instruction finetuning samples are sufficient to achieve good performance on both (1) traditional NLP benchmarks and (2) model-based evaluation. Finally, we show that mixing textbook-style and open-ended QA finetuning datasets optimizes performance on both evaluation paradigms.
Fast Benchmarking of Accuracy vs. Training Time with Cyclic Learning Rates
Jun 02, 2022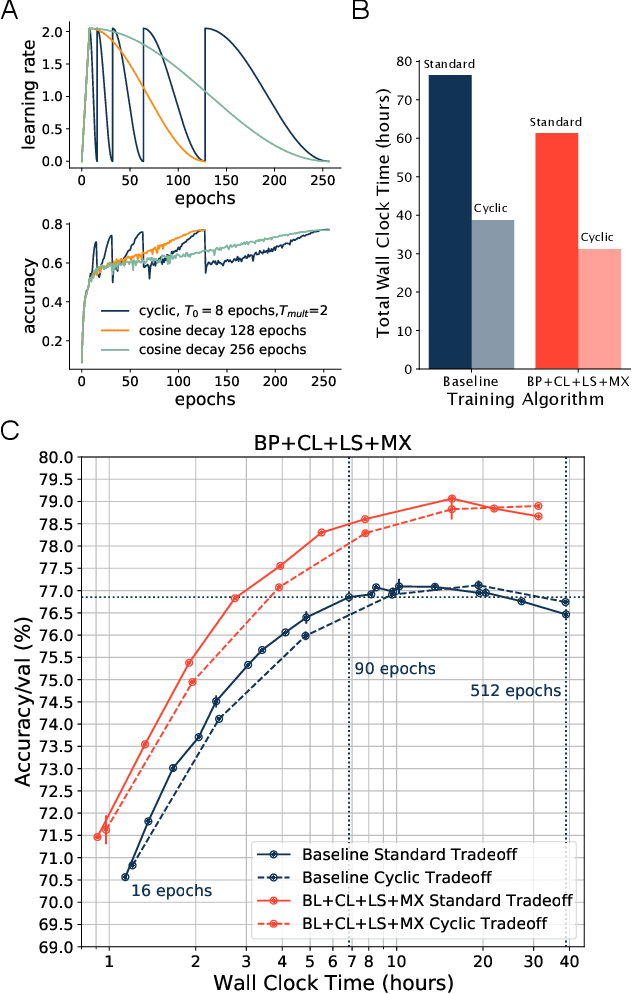
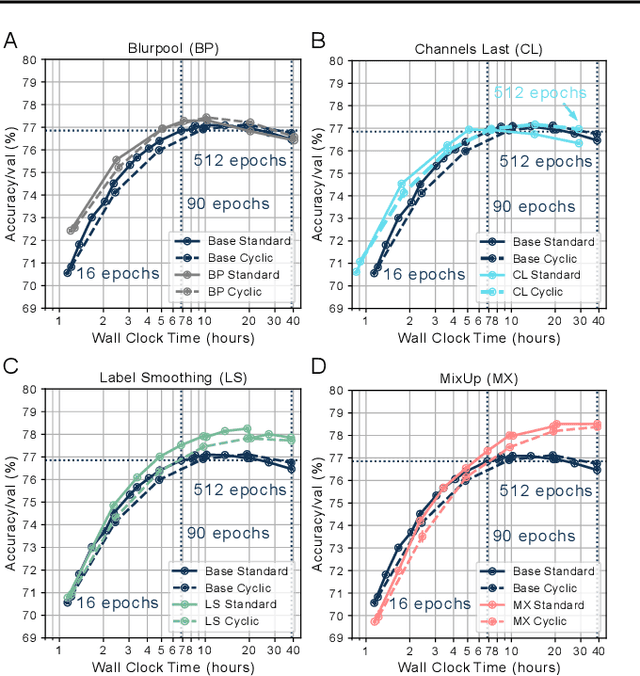
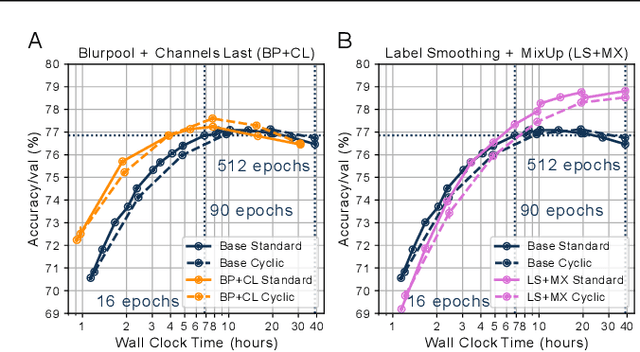
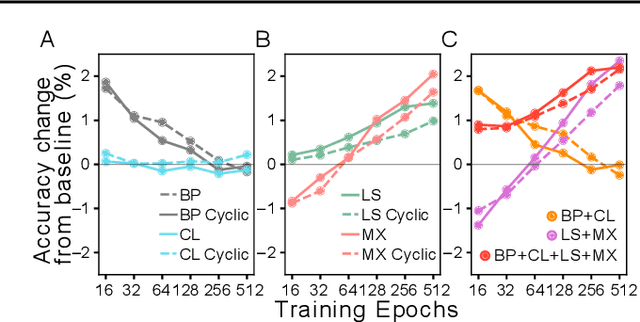
Benchmarking the tradeoff between neural network accuracy and training time is computationally expensive. Here we show how a multiplicative cyclic learning rate schedule can be used to construct a tradeoff curve in a single training run. We generate cyclic tradeoff curves for combinations of training methods such as Blurpool, Channels Last, Label Smoothing and MixUp, and highlight how these cyclic tradeoff curves can be used to evaluate the effects of algorithmic choices on network training efficiency.