 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Upcycling: Inference Inefficient Finetuning
Nov 13, 2024



Small, highly trained, open-source large language models are widely used due to their inference efficiency, but further improving their quality remains a challenge. Sparse upcycling is a promising approach that transforms a pretrained dense model into a Mixture-of-Experts (MoE) architecture, increasing the model's parameter count and quality. In this work, we compare the effectiveness of sparse upcycling against continued pretraining (CPT) across different model sizes, compute budgets, and pretraining durations. Our experiments show that sparse upcycling can achieve better quality, with improvements of over 20% relative to CPT in certain scenarios. However, this comes with a significant inference cost, leading to 40% slowdowns in high-demand inference settings for larger models. Our findings highlight the trade-off between model quality and inference efficiency, offering insights for practitioners seeking to balance model quality and deployment constraints.
MosaicBERT: A Bidirectional Encoder Optimized for Fast Pretraining
Jan 16, 2024



Although BERT-style encoder models are heavily used in NLP research, many researchers do not pretrain their own BERTs from scratch due to the high cost of training. In the past half-decade since BERT first rose to prominence, many advances have been made with other transformer architectures and training configurations that have yet to be systematically incorporated into BERT. Here, we introduce MosaicBERT, a BERT-style encoder architecture and training recipe that is empirically optimized for fast pretraining. This efficient architecture incorporates FlashAttention, Attention with Linear Biases (ALiBi), Gated Linear Units (GLU), a module to dynamically remove padded tokens, and low precision LayerNorm into the classic transformer encoder block. The training recipe includes a 30% masking ratio for the Masked Language Modeling (MLM) objective, bfloat16 precision, and vocabulary size optimized for GPU throughput, in addition to best-practices from RoBERTa and other encoder models. When pretrained from scratch on the C4 dataset, this base model achieves a downstream average GLUE (dev) score of 79.6 in 1.13 hours on 8 A100 80 GB GPUs at a cost of roughly $20. We plot extensive accuracy vs. pretraining speed Pareto curves and show that MosaicBERT base and large are consistently Pareto optimal when compared to a competitive BERT base and large. This empirical speed up in pretraining enables researchers and engineers to pretrain custom BERT-style models at low cost instead of finetune on existing generic models. We open source our model weights and code.
* 10 pages, 4 figures in main text. 25 pages total
Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws
Dec 31, 2023



Large language model (LLM) scaling laws are empirical formulas that estimate changes in model quality as a result of increasing parameter count and training data. However, these formulas, including the popular DeepMind Chinchilla scaling laws, neglect to include the cost of inference. We modify the Chinchilla scaling laws to calculate the optimal LLM parameter count and pre-training data size to train and deploy a model of a given quality and inference demand. We conduct our analysis both in terms of a compute budget and real-world costs and find that LLM researchers expecting reasonably large inference demand (~1B requests) should train models smaller and longer than Chinchilla-optimal.
Autonomous Reinforcement Learning: Formalism and Benchmarking
Dec 17, 2021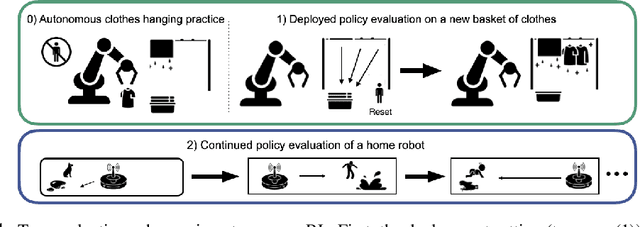

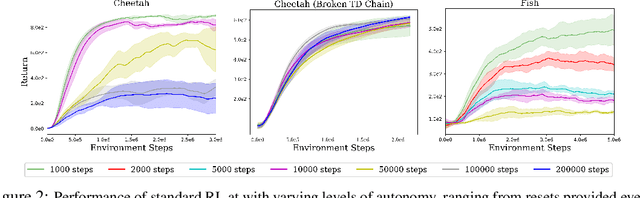

Reinforcement learning (RL) provides a naturalistic framing for learning through trial and error, which is appealing both because of its simplicity and effectiveness and because of its resemblance to how humans and animals acquire skills through experience. However, real-world embodied learning, such as that performed by humans and animals, is situated in a continual, non-episodic world, whereas common benchmark tasks in RL are episodic, with the environment resetting between trials to provide the agent with multiple attempts. This discrepancy presents a major challenge when attempting to take RL algorithms developed for episodic simulated environments and run them on real-world platforms, such as robots. In this paper, we aim to address this discrepancy by laying out a framework for Autonomous Reinforcement Learning (ARL): reinforcement learning where the agent not only learns through its own experience, but also contends with lack of human supervision to reset between trials. We introduce a simulated benchmark EARL around this framework, containing a set of diverse and challenging simulated tasks reflective of the hurdles introduced to learning when only a minimal reliance on extrinsic intervention can be assumed. We show that standard approaches to episodic RL and existing approaches struggle as interventions are minimized, underscoring the need for developing new algorithms for reinforcement learning with a greater focus on autonomy.
Bayesian Meta-Learning Through Variational Gaussian Processes
Oct 21, 2021


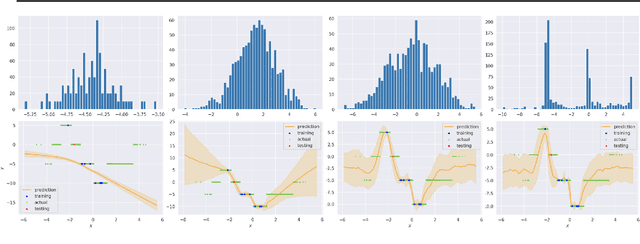
Recent advances in the field of meta-learning have tackled domains consisting of large numbers of small ("few-shot") supervised learning tasks. Meta-learning algorithms must be able to rapidly adapt to any individual few-shot task, fitting to a small support set within a task and using it to predict the labels of the task's query set. This problem setting can be extended to the Bayesian context, wherein rather than predicting a single label for each query data point, a model predicts a distribution of labels capturing its uncertainty. Successful methods in this domain include Bayesian ensembling of MAML-based models, Bayesian neural networks, and Gaussian processes with learned deep kernel and mean functions. While Gaussian processes have a robust Bayesian interpretation in the meta-learning context, they do not naturally model non-Gaussian predictive posteriors for expressing uncertainty. In this paper, we design a theoretically principled method, VMGP, extending Gaussian-process-based meta-learning to allow for high-quality, arbitrary non-Gaussian uncertainty predictions. On benchmark environments with complex non-smooth or discontinuous structure, we find our VMGP method performs significantly better than existing Bayesian meta-learning baselines.