 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs the GPU Half-Empty or Half-Full? Practical Scheduling Techniques for LLMs
Oct 23, 2024



Serving systems for Large Language Models (LLMs) improve throughput by processing several requests concurrently. However, multiplexing hardware resources between concurrent requests involves non-trivial scheduling decisions. Practical serving systems typically implement these decisions at two levels: First, a load balancer routes requests to different servers which each hold a replica of the LLM. Then, on each server, an engine-level scheduler decides when to run a request, or when to queue or preempt it. Improved scheduling policies may benefit a wide range of LLM deployments and can often be implemented as "drop-in replacements" to a system's current policy. In this work, we survey scheduling techniques from the literature and from practical serving systems. We find that schedulers from the literature often achieve good performance but introduce significant complexity. In contrast, schedulers in practical deployments often leave easy performance gains on the table but are easy to implement, deploy and configure. This finding motivates us to introduce two new scheduling techniques, which are both easy to implement, and outperform current techniques on production workload traces.
MosaicBERT: A Bidirectional Encoder Optimized for Fast Pretraining
Jan 16, 2024



Although BERT-style encoder models are heavily used in NLP research, many researchers do not pretrain their own BERTs from scratch due to the high cost of training. In the past half-decade since BERT first rose to prominence, many advances have been made with other transformer architectures and training configurations that have yet to be systematically incorporated into BERT. Here, we introduce MosaicBERT, a BERT-style encoder architecture and training recipe that is empirically optimized for fast pretraining. This efficient architecture incorporates FlashAttention, Attention with Linear Biases (ALiBi), Gated Linear Units (GLU), a module to dynamically remove padded tokens, and low precision LayerNorm into the classic transformer encoder block. The training recipe includes a 30% masking ratio for the Masked Language Modeling (MLM) objective, bfloat16 precision, and vocabulary size optimized for GPU throughput, in addition to best-practices from RoBERTa and other encoder models. When pretrained from scratch on the C4 dataset, this base model achieves a downstream average GLUE (dev) score of 79.6 in 1.13 hours on 8 A100 80 GB GPUs at a cost of roughly $20. We plot extensive accuracy vs. pretraining speed Pareto curves and show that MosaicBERT base and large are consistently Pareto optimal when compared to a competitive BERT base and large. This empirical speed up in pretraining enables researchers and engineers to pretrain custom BERT-style models at low cost instead of finetune on existing generic models. We open source our model weights and code.
* 10 pages, 4 figures in main text. 25 pages total
Low-Precision Hardware Architectures Meet Recommendation Model Inference at Scale
May 26, 2021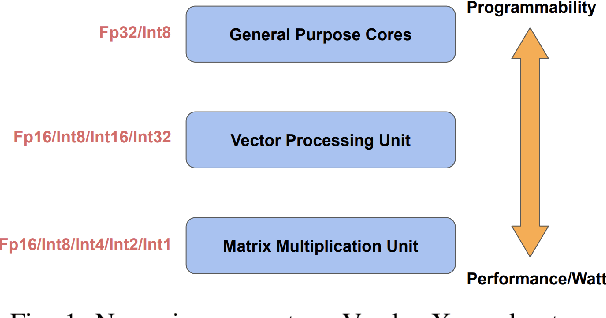
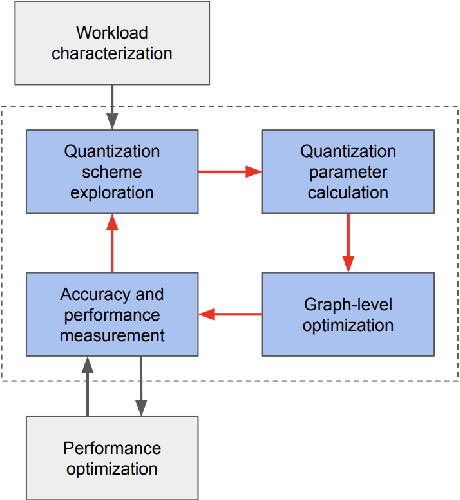
Tremendous success of machine learning (ML) and the unabated growth in ML model complexity motivated many ML-specific designs in both CPU and accelerator architectures to speed up the model inference. While these architectures are diverse, highly optimized low-precision arithmetic is a component shared by most. Impressive compute throughputs are indeed often exhibited by these architectures on benchmark ML models. Nevertheless, production models such as recommendation systems important to Facebook's personalization services are demanding and complex: These systems must serve billions of users per month responsively with low latency while maintaining high prediction accuracy, notwithstanding computations with many tens of billions parameters per inference. Do these low-precision architectures work well with our production recommendation systems? They do. But not without significant effort. We share in this paper our search strategies to adapt reference recommendation models to low-precision hardware, our optimization of low-precision compute kernels, and the design and development of tool chain so as to maintain our models' accuracy throughout their lifespan during which topic trends and users' interests inevitably evolve. Practicing these low-precision technologies helped us save datacenter capacities while deploying models with up to 5X complexity that would otherwise not be deployed on traditional general-purpose CPUs. We believe these lessons from the trenches promote better co-design between hardware architecture and software engineering and advance the state of the art of ML in industry.
FBGEMM: Enabling High-Performance Low-Precision Deep Learning Inference
Jan 13, 2021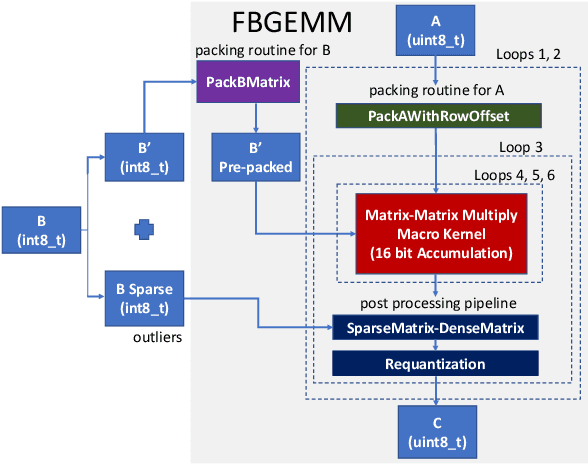
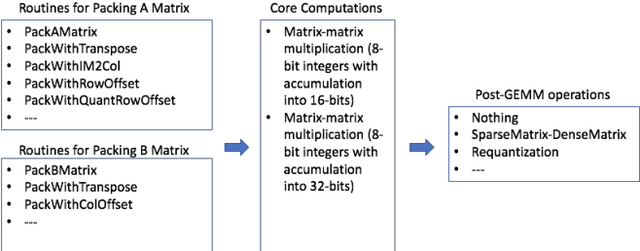
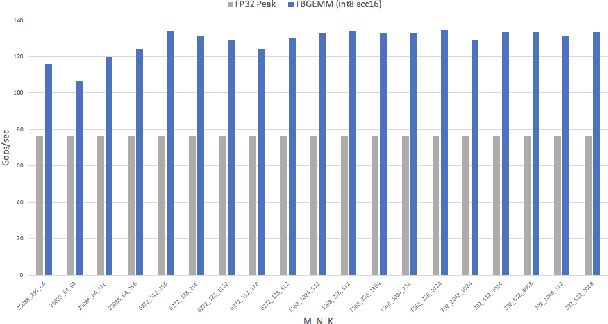
Deep learning models typically use single-precision (FP32) floating point data types for representing activations and weights, but a slew of recent research work has shown that computations with reduced-precision data types (FP16, 16-bit integers, 8-bit integers or even 4- or 2-bit integers) are enough to achieve same accuracy as FP32 and are much more efficient. Therefore, we designed fbgemm, a high-performance kernel library, from ground up to perform high-performance quantized inference on current generation CPUs. fbgemm achieves efficiency by fusing common quantization operations with a high-performance gemm implementation and by shape- and size-specific kernel code generation at runtime. The library has been deployed at Facebook, where it delivers greater than 2x performance gains with respect to our current production baseline.
Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations and Hardware Implications
Nov 29, 2018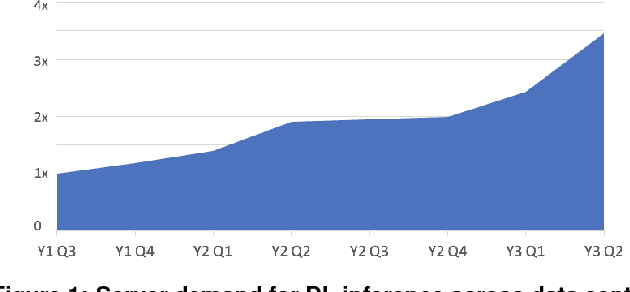
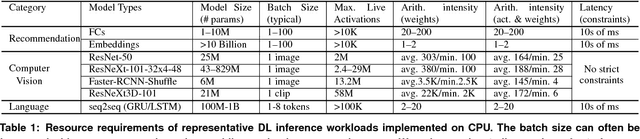
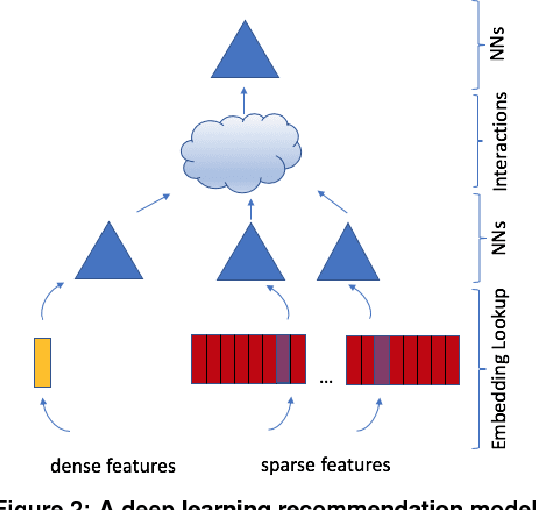
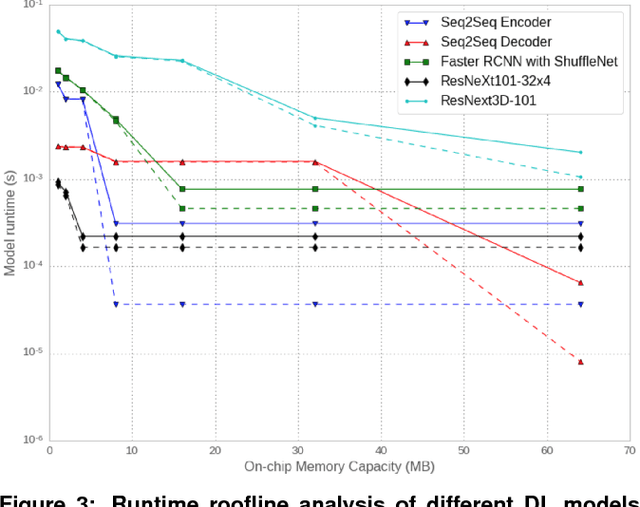
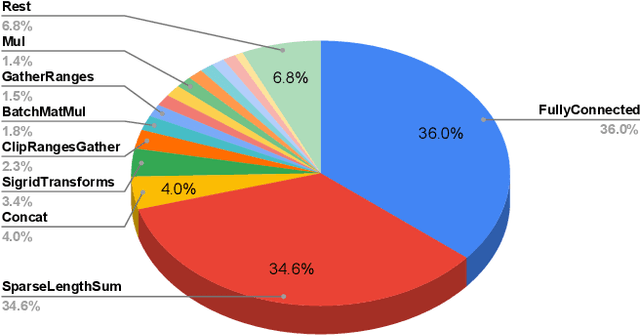
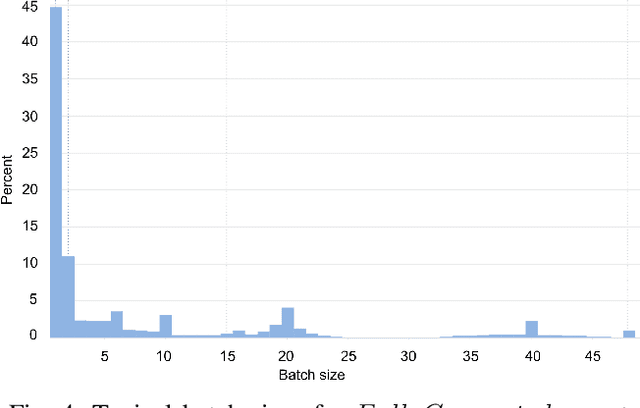
The application of deep learning techniques resulted in remarkable improvement of machine learning models. In this paper provides detailed characterizations of deep learning models used in many Facebook social network services. We present computational characteristics of our models, describe high performance optimizations targeting existing systems, point out their limitations and make suggestions for the future general-purpose/accelerated inference hardware. Also, we highlight the need for better co-design of algorithms, numerics and computing platforms to address the challenges of workloads often run in data centers.