 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-Aided Design for Dynamic CAD Models
Apr 16, 2026In the past year, researchers have started to create agentic systems that can design real-world CAD-style objects in a training-free setting, a new variety of system that we call Agent-Aided Design. Generally speaking, these systems place an agent in a feedback loop in which it can write code, compile that code to an assembly of CAD model(s), visualize the model, and then iteratively refine its code based on visual and other feedback. Despite rapid progress, a key problem remains: none of these systems can build complex 3D assemblies with moving parts. For example, no existing system can build a piston, a pendulum, or even a pair of scissors. In order for Agent-Aided Design to make a real impact in industrial manufacturing, we need a system that is capable of generating such 3D assemblies. In this paper we present a prototype of AADvark, an agentic system designed for this task. Unlike previous state-of-the-art systems, AADvark captures the dynamic part interactions with one or more degrees-of-freedom. This design decision allows AADvark to reason directly about assemblies with moving parts and can thereby achieve cross-cutting goals, including but not limited to mechanical movements. Unfortunately, current LLMs are imperfect spatial reasoners, a problem that AADvark addresses by incorporating external constraint solver tools with a specialized visual feedback mechanism. We demonstrate that, by modifying the agent's tools (FreeCAD and the assembly solver), we are able to create a strong verification signal which enables our system to build 3D assemblies with movable parts.
CONCUR: A Framework for Continual Constrained and Unconstrained Routing
Dec 10, 2025AI tasks differ in complexity and are best addressed with different computation strategies (e.g., combinations of models and decoding methods). Hence, an effective routing system that maps tasks to the appropriate strategies is crucial. Most prior methods build the routing framework by training a single model across all strategies, which demands full retraining whenever new strategies appear and leads to high overhead. Attempts at such continual routing, however, often face difficulties with generalization. Prior models also typically use a single input representation, limiting their ability to capture the full complexity of the routing problem and leading to sub-optimal routing decisions. To address these gaps, we propose CONCUR, a continual routing framework that supports both constrained and unconstrained routing (i.e., routing with or without a budget). Our modular design trains a separate predictor model for each strategy, enabling seamless incorporation of new strategies with low additional training cost. Our predictors also leverage multiple representations of both tasks and computation strategies to better capture overall problem complexity. Experiments on both in-distribution and out-of-distribution, knowledge- and reasoning-intensive tasks show that our method outperforms the best single strategy and strong existing routing techniques with higher end-to-end accuracy and lower inference cost in both continual and non-continual settings, while also reducing training cost in the continual setting.
Abacus: A Cost-Based Optimizer for Semantic Operator Systems
May 20, 2025LLMs enable an exciting new class of data processing applications over large collections of unstructured documents. Several new programming frameworks have enabled developers to build these applications by composing them out of semantic operators: a declarative set of AI-powered data transformations with natural language specifications. These include LLM-powered maps, filters, joins, etc. used for document processing tasks such as information extraction, summarization, and more. While systems of semantic operators have achieved strong performance on benchmarks, they can be difficult to optimize. An optimizer for this setting must determine how to physically implement each semantic operator in a way that optimizes the system globally. Existing optimizers are limited in the number of optimizations they can apply, and most (if not all) cannot optimize system quality, cost, or latency subject to constraint(s) on the other dimensions. In this paper we present Abacus, an extensible, cost-based optimizer which searches for the best implementation of a semantic operator system given a (possibly constrained) optimization objective. Abacus estimates operator performance by leveraging a minimal set of validation examples and, if available, prior beliefs about operator performance. We evaluate Abacus on document processing workloads in the biomedical and legal domains (BioDEX; CUAD) and multi-modal question answering (MMQA). We demonstrate that systems optimized by Abacus achieve 18.7%-39.2% better quality and up to 23.6x lower cost and 4.2x lower latency than the next best system.
Log-Augmented Generation: Scaling Test-Time Reasoning with Reusable Computation
May 20, 2025While humans naturally learn and adapt from past experiences, large language models (LLMs) and their agentic counterparts struggle to retain reasoning from previous tasks and apply them in future contexts. To address this limitation, we propose a novel framework, log-augmented generation (LAG) that directly reuses prior computation and reasoning from past logs at test time to enhance model's ability to learn from previous tasks and perform better on new, unseen challenges, all while keeping the system efficient and scalable. Specifically, our system represents task logs using key-value (KV) caches, encoding the full reasoning context of prior tasks while storing KV caches for only a selected subset of tokens. When a new task arises, LAG retrieves the KV values from relevant logs to augment generation. Our approach differs from reflection-based memory mechanisms by directly reusing prior reasoning and computations without requiring additional steps for knowledge extraction or distillation. Our method also goes beyond existing KV caching techniques, which primarily target efficiency gains rather than improving accuracy. Experiments on knowledge- and reasoning-intensive datasets demonstrate that our method significantly outperforms standard agentic systems that do not utilize logs, as well as existing solutions based on reflection and KV cache techniques.
Causal DAG Summarization (Full Version)
Apr 21, 2025



Causal inference aids researchers in discovering cause-and-effect relationships, leading to scientific insights. Accurate causal estimation requires identifying confounding variables to avoid false discoveries. Pearl's causal model uses causal DAGs to identify confounding variables, but incorrect DAGs can lead to unreliable causal conclusions. However, for high dimensional data, the causal DAGs are often complex beyond human verifiability. Graph summarization is a logical next step, but current methods for general-purpose graph summarization are inadequate for causal DAG summarization. This paper addresses these challenges by proposing a causal graph summarization objective that balances graph simplification for better understanding while retaining essential causal information for reliable inference. We develop an efficient greedy algorithm and show that summary causal DAGs can be directly used for inference and are more robust to misspecification of assumptions, enhancing robustness for causal inference. Experimenting with six real-life datasets, we compared our algorithm to three existing solutions, showing its effectiveness in handling high-dimensional data and its ability to generate summary DAGs that ensure both reliable causal inference and robustness against misspecifications.
EnrichIndex: Using LLMs to Enrich Retrieval Indices Offline
Apr 04, 2025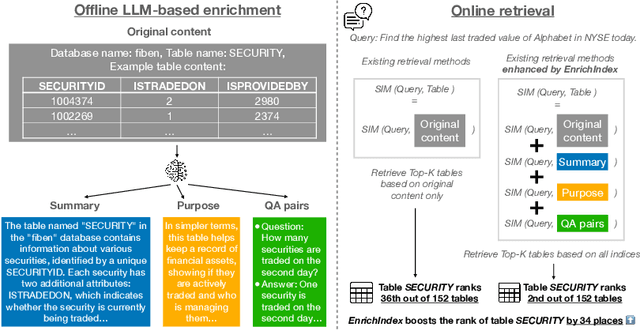
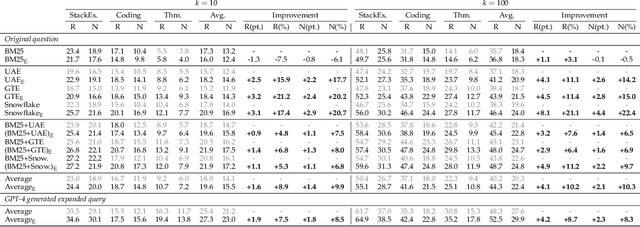
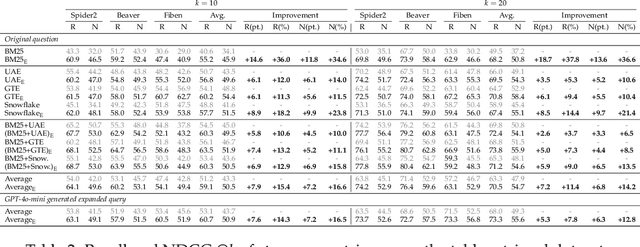
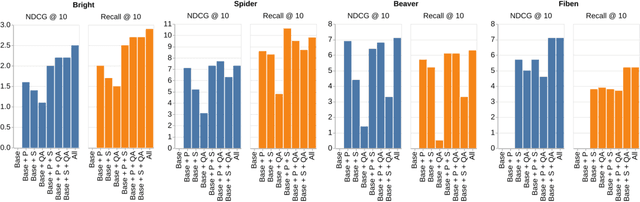
Existing information retrieval systems excel in cases where the language of target documents closely matches that of the user query. However, real-world retrieval systems are often required to implicitly reason whether a document is relevant. For example, when retrieving technical texts or tables, their relevance to the user query may be implied through a particular jargon or structure, rather than explicitly expressed in their content. Large language models (LLMs) hold great potential in identifying such implied relevance by leveraging their reasoning skills. Nevertheless, current LLM-augmented retrieval is hindered by high latency and computation cost, as the LLM typically computes the query-document relevance online, for every query anew. To tackle this issue we introduce EnrichIndex, a retrieval approach which instead uses the LLM offline to build semantically-enriched retrieval indices, by performing a single pass over all documents in the retrieval corpus once during ingestion time. Furthermore, the semantically-enriched indices can complement existing online retrieval approaches, boosting the performance of LLM re-rankers. We evaluated EnrichIndex on five retrieval tasks, involving passages and tables, and found that it outperforms strong online LLM-based retrieval systems, with an average improvement of 11.7 points in recall @ 10 and 10.6 points in NDCG @ 10 compared to strong baselines. In terms of online calls to the LLM, it processes 293.3 times fewer tokens which greatly reduces the online latency and cost. Overall, EnrichIndex is an effective way to build better retrieval indices offline by leveraging the strong reasoning skills of LLMs.
PalimpChat: Declarative and Interactive AI analytics
Feb 05, 2025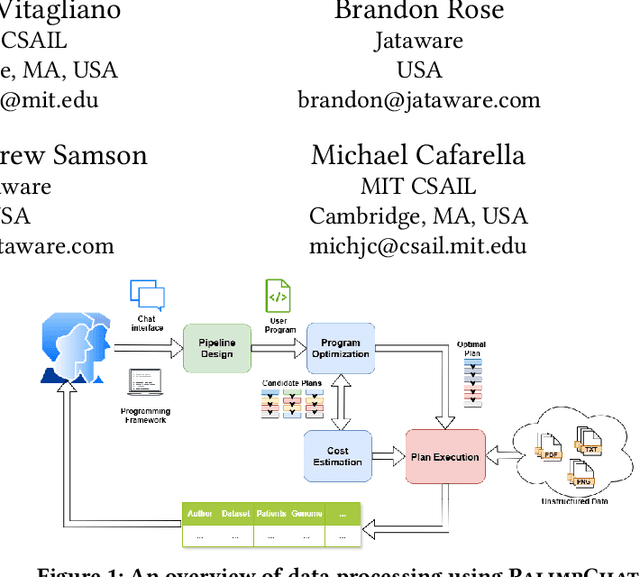

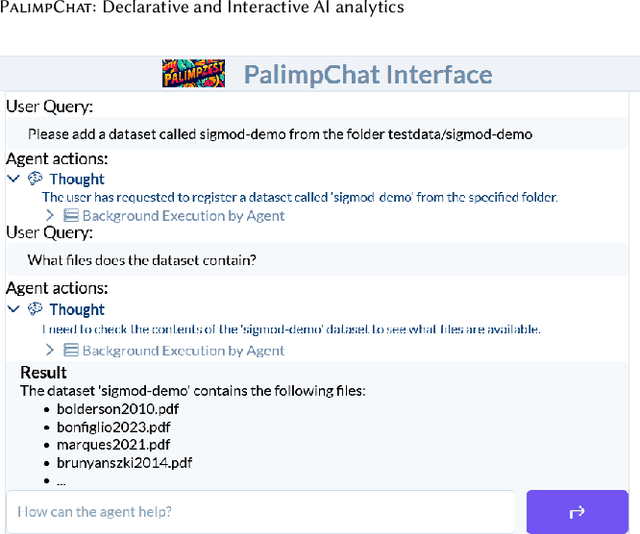
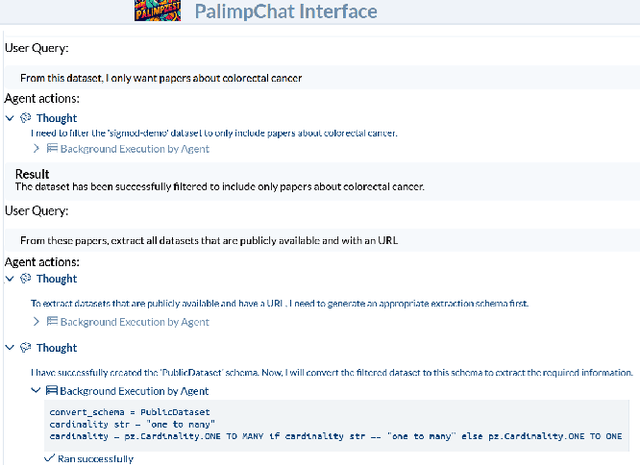
Thanks to the advances in generative architectures and large language models, data scientists can now code pipelines of machine-learning operations to process large collections of unstructured data. Recent progress has seen the rise of declarative AI frameworks (e.g., Palimpzest, Lotus, and DocETL) to build optimized and increasingly complex pipelines, but these systems often remain accessible only to expert programmers. In this demonstration, we present PalimpChat, a chat-based interface to Palimpzest that bridges this gap by letting users create and run sophisticated AI pipelines through natural language alone. By integrating Archytas, a ReAct-based reasoning agent, and Palimpzest's suite of relational and LLM-based operators, PalimpChat provides a practical illustration of how a chat interface can make declarative AI frameworks truly accessible to non-experts. Our demo system is publicly available online. At SIGMOD'25, participants can explore three real-world scenarios--scientific discovery, legal discovery, and real estate search--or apply PalimpChat to their own datasets. In this paper, we focus on how PalimpChat, supported by the Palimpzest optimizer, simplifies complex AI workflows such as extracting and analyzing biomedical data.
Can we Retrieve Everything All at Once? ARM: An Alignment-Oriented LLM-based Retrieval Method
Jan 30, 2025Real-world open-domain questions can be complicated, particularly when answering them involves information from multiple information sources. LLMs have demonstrated impressive performance in decomposing complex tasks into simpler steps, and previous work has used it for better retrieval in support of complex questions. However, LLM's decomposition of questions is unaware of what data is available and how data is organized, often leading to a sub-optimal retrieval performance. Recent effort in agentic RAG proposes to perform retrieval in an iterative fashion, where a followup query is derived as an action based on previous rounds of retrieval. While this provides one way of interacting with the data collection, agentic RAG's exploration of data is inefficient because successive queries depend on previous results rather than being guided by the organization of available data in the collection. To address this problem, we propose an LLM-based retrieval method -- ARM, that aims to better align the question with the organization of the data collection by exploring relationships among data objects beyond matching the utterance of the query, thus leading to a retrieve-all-at-once solution for complex queries. We evaluated ARM on two datasets, Bird and OTT-QA. On Bird, it outperforms standard RAG with query decomposition by up to 5.2 pt in execution accuracy and agentic RAG (ReAct) by up to 15.9 pt. On OTT-QA, it achieves up to 5.5 pt and 19.3 pt higher F1 match scores compared to these approaches.
Is the GPU Half-Empty or Half-Full? Practical Scheduling Techniques for LLMs
Oct 23, 2024



Serving systems for Large Language Models (LLMs) improve throughput by processing several requests concurrently. However, multiplexing hardware resources between concurrent requests involves non-trivial scheduling decisions. Practical serving systems typically implement these decisions at two levels: First, a load balancer routes requests to different servers which each hold a replica of the LLM. Then, on each server, an engine-level scheduler decides when to run a request, or when to queue or preempt it. Improved scheduling policies may benefit a wide range of LLM deployments and can often be implemented as "drop-in replacements" to a system's current policy. In this work, we survey scheduling techniques from the literature and from practical serving systems. We find that schedulers from the literature often achieve good performance but introduce significant complexity. In contrast, schedulers in practical deployments often leave easy performance gains on the table but are easy to implement, deploy and configure. This finding motivates us to introduce two new scheduling techniques, which are both easy to implement, and outperform current techniques on production workload traces.
BEAVER: An Enterprise Benchmark for Text-to-SQL
Sep 03, 2024Existing text-to-SQL benchmarks have largely been constructed using publicly available tables from the web with human-generated tests containing question and SQL statement pairs. They typically show very good results and lead people to think that LLMs are effective at text-to-SQL tasks. In this paper, we apply off-the-shelf LLMs to a benchmark containing enterprise data warehouse data. In this environment, LLMs perform poorly, even when standard prompt engineering and RAG techniques are utilized. As we will show, the reasons for poor performance are largely due to three characteristics: (1) public LLMs cannot train on enterprise data warehouses because they are largely in the "dark web", (2) schemas of enterprise tables are more complex than the schemas in public data, which leads the SQL-generation task innately harder, and (3) business-oriented questions are often more complex, requiring joins over multiple tables and aggregations. As a result, we propose a new dataset BEAVER, sourced from real enterprise data warehouses together with natural language queries and their correct SQL statements which we collected from actual user history. We evaluated this dataset using recent LLMs and demonstrated their poor performance on this task. We hope this dataset will facilitate future researchers building more sophisticated text-to-SQL systems which can do better on this important class of data.