 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubikSQL: Lifelong Learning Agentic Knowledge Base as an Industrial NL2SQL System
Aug 25, 2025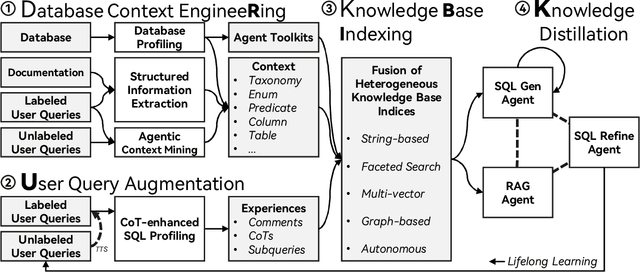
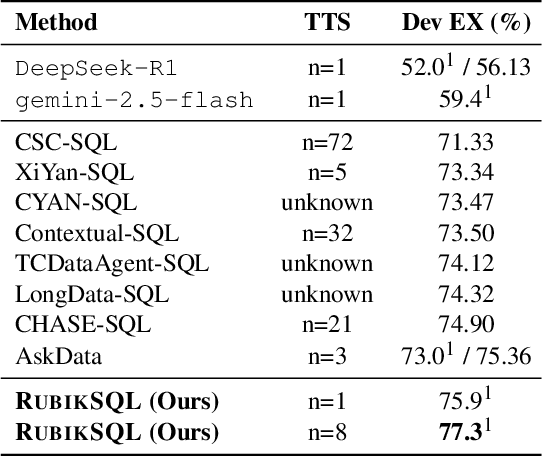
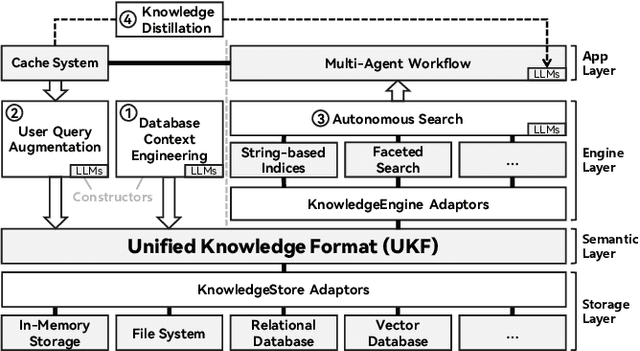
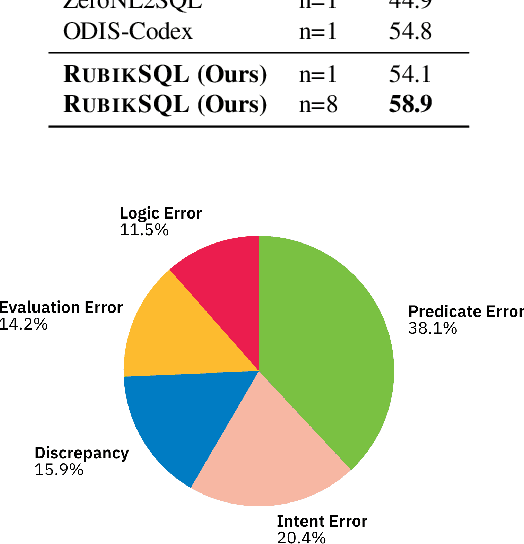
We present RubikSQL, a novel NL2SQL system designed to address key challenges in real-world enterprise-level NL2SQL, such as implicit intents and domain-specific terminology. RubikSQL frames NL2SQL as a lifelong learning task, demanding both Knowledge Base (KB) maintenance and SQL generation. RubikSQL systematically builds and refines its KB through techniques including database profiling, structured information extraction, agentic rule mining, and Chain-of-Thought (CoT)-enhanced SQL profiling. RubikSQL then employs a multi-agent workflow to leverage this curated KB, generating accurate SQLs. RubikSQL achieves SOTA performance on both the KaggleDBQA and BIRD Mini-Dev datasets. Finally, we release the RubikBench benchmark, a new benchmark specifically designed to capture vital traits of industrial NL2SQL scenarios, providing a valuable resource for future research.
Advancing Math Reasoning in Language Models: The Impact of Problem-Solving Data, Data Synthesis Methods, and Training Stages
Jan 23, 2025Advancements in LLMs have significantly expanded their capabilities across various domains. However, mathematical reasoning remains a challenging area, prompting the development of math-specific LLMs. These models typically follow a two-stage training paradigm: pre-training with math-related corpora and post-training with problem datasets for SFT. Despite these efforts, the improvements in mathematical reasoning achieved through continued pre-training (CPT) are often less significant compared to those obtained via SFT. This study addresses this discrepancy by exploring alternative strategies during the pre-training phase, focusing on the use of problem-solving data over general mathematical corpora. We investigate three primary research questions: (1) Can problem-solving data enhance the model's mathematical reasoning capabilities more effectively than general mathematical corpora during CPT? (2) Are synthetic data from the same source equally effective, and which synthesis methods are most efficient? (3) How do the capabilities developed from the same problem-solving data differ between the CPT and SFT stages, and what factors contribute to these differences? Our findings indicate that problem-solving data significantly enhances the model's mathematical capabilities compared to general mathematical corpora. We also identify effective data synthesis methods, demonstrating that the tutorship amplification synthesis method achieves the best performance. Furthermore, while SFT facilitates instruction-following abilities, it underperforms compared to CPT with the same data, which can be partially attributed to its poor learning capacity for hard multi-step problem-solving data. These insights provide valuable guidance for optimizing the mathematical reasoning capabilities of LLMs, culminating in our development of a powerful mathematical base model called JiuZhang-8B.
What Are Step-Level Reward Models Rewarding? Counterintuitive Findings from MCTS-Boosted Mathematical Reasoning
Dec 20, 2024Step-level reward models (SRMs) can significantly enhance mathematical reasoning performance through process supervision or step-level preference alignment based on reinforcement learning. The performance of SRMs is pivotal, as they serve as critical guidelines, ensuring that each step in the reasoning process is aligned with desired outcomes. Recently, AlphaZero-like methods, where Monte Carlo Tree Search (MCTS) is employed for automatic step-level preference annotation, have proven particularly effective. However, the precise mechanisms behind the success of SRMs remain largely unexplored. To address this gap, this study delves into the counterintuitive aspects of SRMs, particularly focusing on MCTS-based approaches. Our findings reveal that the removal of natural language descriptions of thought processes has minimal impact on the efficacy of SRMs. Furthermore, we demonstrate that SRMs are adept at assessing the complex logical coherence present in mathematical language while having difficulty in natural language. These insights provide a nuanced understanding of the core elements that drive effective step-level reward modeling in mathematical reasoning. By shedding light on these mechanisms, this study offers valuable guidance for developing more efficient and streamlined SRMs, which can be achieved by focusing on the crucial parts of mathematical reasoning.
Expediting and Elevating Large Language Model Reasoning via Hidden Chain-of-Thought Decoding
Sep 13, 2024Large language models (LLMs) have demonstrated remarkable capabilities in tasks requiring reasoning and multi-step problem-solving through the use of chain-of-thought (CoT) prompting. However, generating the full CoT process results in significantly longer output sequences, leading to increased computational costs and latency during inference. To address this challenge, we propose a novel approach to compress the CoT process through semantic alignment, enabling more efficient decoding while preserving the benefits of CoT reasoning. Our method introduces an auxiliary CoT model that learns to generate and compress the full thought process into a compact special token representation semantically aligned with the original CoT output. This compressed representation is then integrated into the input of the Hidden Chain-of-Thought (HCoT) model. The training process follows a two-stage procedure: First, the CoT model is optimized to generate the compressed token representations aligned with the ground-truth CoT outputs using a contrastive loss. Subsequently, with the CoT model parameters frozen, the HCoT model is fine-tuned to generate accurate subsequent predictions conditioned on the prefix instruction and the compressed CoT representations from the CoT model. Extensive experiments across three challenging domains - mathematical reasoning, agent invocation, and question answering - demonstrate that our semantic compression approach achieves competitive or improved performance compared to the full CoT baseline, while providing significant speedups of at least 1.5x in decoding time. Moreover, incorporating contrastive learning objectives further enhances the quality of the compressed representations, leading to better CoT prompting and improved task accuracy. Our work paves the way for more efficient exploitation of multi-step reasoning capabilities in LLMs across a wide range of applications.
A Declarative System for Optimizing AI Workloads
May 23, 2024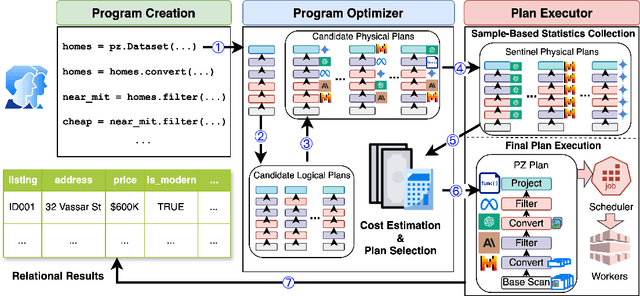
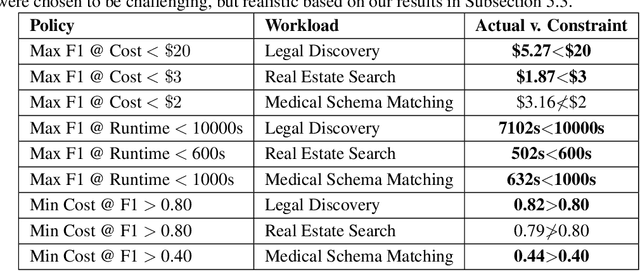
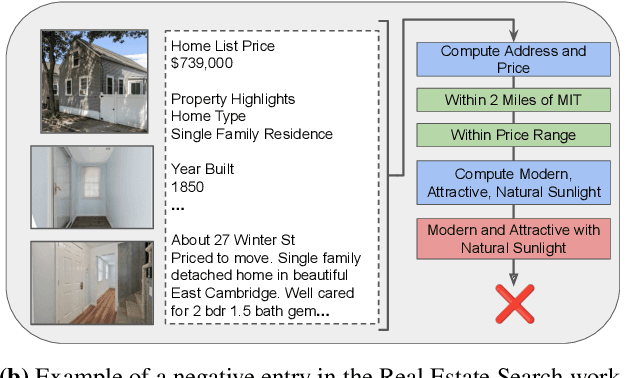
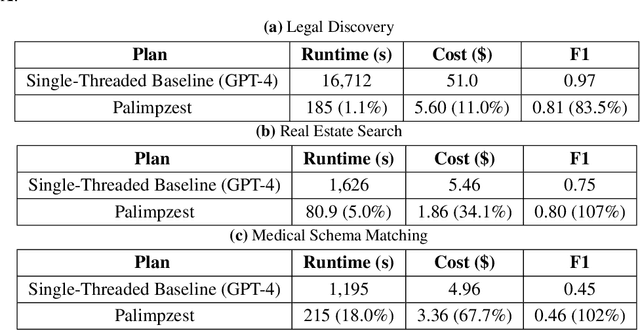
Modern AI models provide the key to a long-standing dream: processing analytical queries about almost any kind of data. Until recently, it was difficult and expensive to extract facts from company documents, data from scientific papers, or insights from image and video corpora. Today's models can accomplish these tasks with high accuracy. However, a programmer who wants to answer a substantive AI-powered query must orchestrate large numbers of models, prompts, and data operations. For even a single query, the programmer has to make a vast number of decisions such as the choice of model, the right inference method, the most cost-effective inference hardware, the ideal prompt design, and so on. The optimal set of decisions can change as the query changes and as the rapidly-evolving technical landscape shifts. In this paper we present Palimpzest, a system that enables anyone to process AI-powered analytical queries simply by defining them in a declarative language. The system uses its cost optimization framework -- which explores the search space of AI models, prompting techniques, and related foundation model optimizations -- to implement the query with the best trade-offs between runtime, financial cost, and output data quality. We describe the workload of AI-powered analytics tasks, the optimization methods that Palimpzest uses, and the prototype system itself. We evaluate Palimpzest on tasks in Legal Discovery, Real Estate Search, and Medical Schema Matching. We show that even our simple prototype offers a range of appealing plans, including one that is 3.3x faster, 2.9x cheaper, and offers better data quality than the baseline method. With parallelism enabled, Palimpzest can produce plans with up to a 90.3x speedup at 9.1x lower cost relative to a single-threaded GPT-4 baseline, while obtaining an F1-score within 83.5% of the baseline. These require no additional work by the user.
An Empirical Study of Data Ability Boundary in LLMs' Math Reasoning
Feb 23, 2024Large language models (LLMs) are displaying emergent abilities for math reasoning tasks,and there is a growing attention on enhancing the ability of open-source LLMs through supervised fine-tuning (SFT).In this paper, we aim to explore a general data strategy for supervised data to help optimize and expand math reasoning ability.Firstly, we determine the ability boundary of reasoning paths augmentation by identifying these paths' minimal optimal set.Secondly, we validate that different abilities of the model can be cumulatively enhanced by Mix of Minimal Optimal Sets of corresponding types of data, while our models MMOS achieve SOTA performance on series base models under much lower construction costs.Besides, we point out GSM-HARD is not really hard and today's LLMs no longer lack numerical robustness.Also, we provide an Auto Problem Generator for robustness testing and educational applications.Our code and data are publicly available at https://github.com/cyzhh/MMOS.
Brain-Inspired Two-Stage Approach: Enhancing Mathematical Reasoning by Imitating Human Thought Processes
Feb 23, 2024Although large language models demonstrate emergent abilities in solving math word problems, there is a challenging task in complex multi-step mathematical reasoning tasks. To improve model performance on mathematical reasoning tasks, previous work has conducted supervised fine-tuning on open-source models by improving the quality and quantity of data. In this paper, we propose a novel approach, named Brain, to imitate human thought processes to enhance mathematical reasoning abilities, using the Frontal Lobe Model to generate plans, and then employing the Parietal Lobe Model to generate code and execute to obtain answers. First, we achieve SOTA performance in comparison with Code LLaMA 7B based models through this method. Secondly, we find that plans can be explicitly extracted from natural language, code, or formal language. Our code and data are publicly available at https://github.com/cyzhh/Brain.
RoTaR: Efficient Row-Based Table Representation Learning via Teacher-Student Training
Jun 20, 2023We propose RoTaR, a row-based table representation learning method, to address the efficiency and scalability issues faced by existing table representation learning methods. The key idea of RoTaR is to generate query-agnostic row representations that could be re-used via query-specific aggregation. In addition to the row-based architecture, we introduce several techniques: cell-aware position embedding, teacher-student training paradigm, and selective backward to improve the performance of RoTaR model.
Lingua Manga: A Generic Large Language Model Centric System for Data Curation
Jun 20, 2023Data curation is a wide-ranging area which contains many critical but time-consuming data processing tasks. However, the diversity of such tasks makes it challenging to develop a general-purpose data curation system. To address this issue, we present Lingua Manga, a user-friendly and versatile system that utilizes pre-trained large language models. Lingua Manga offers automatic optimization for achieving high performance and label efficiency while facilitating flexible and rapid development. Through three example applications with distinct objectives and users of varying levels of technical proficiency, we demonstrate that Lingua Manga can effectively assist both skilled programmers and low-code or even no-code users in addressing data curation challenges.
Interleaving Pre-Trained Language Models and Large Language Models for Zero-Shot NL2SQL Generation
Jun 15, 2023Zero-shot NL2SQL is crucial in achieving natural language to SQL that is adaptive to new environments (e.g., new databases, new linguistic phenomena or SQL structures) with zero annotated NL2SQL samples from such environments. Existing approaches either fine-tune pre-trained language models (PLMs) based on annotated data or use prompts to guide fixed large language models (LLMs) such as ChatGPT. PLMs can perform well in schema alignment but struggle to achieve complex reasoning, while LLMs is superior in complex reasoning tasks but cannot achieve precise schema alignment. In this paper, we propose a ZeroNL2SQL framework that combines the complementary advantages of PLMs and LLMs for supporting zero-shot NL2SQL. ZeroNL2SQL first uses PLMs to generate an SQL sketch via schema alignment, then uses LLMs to fill the missing information via complex reasoning. Moreover, in order to better align the generated SQL queries with values in the given database instances, we design a predicate calibration method to guide the LLM in completing the SQL sketches based on the database instances and select the optimal SQL query via an execution-based strategy. Comprehensive experiments show that ZeroNL2SQL can achieve the best zero-shot NL2SQL performance on real-world benchmarks. Specifically, ZeroNL2SQL outperforms the state-of-the-art PLM-based methods by 3.2% to 13% and exceeds LLM-based methods by 10% to 20% on execution accuracy.