 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradingAttack: Attacking Large Language Models Towards Short Answer Grading Ability
Feb 01, 2026Large language models (LLMs) have demonstrated remarkable potential for automatic short answer grading (ASAG), significantly boosting student assessment efficiency and scalability in educational scenarios. However, their vulnerability to adversarial manipulation raises critical concerns about automatic grading fairness and reliability. In this paper, we introduce GradingAttack, a fine-grained adversarial attack framework that systematically evaluates the vulnerability of LLM based ASAG models. Specifically, we align general-purpose attack methods with the specific objectives of ASAG by designing token-level and prompt-level strategies that manipulate grading outcomes while maintaining high camouflage. Furthermore, to quantify attack camouflage, we propose a novel evaluation metric that balances attack success and camouflage. Experiments on multiple datasets demonstrate that both attack strategies effectively mislead grading models, with prompt-level attacks achieving higher success rates and token-level attacks exhibiting superior camouflage capability. Our findings underscore the need for robust defenses to ensure fairness and reliability in ASAG. Our code and datasets are available at https://anonymous.4open.science/r/GradingAttack.
PrivacyCD: Hierarchical Unlearning for Protecting Student Privacy in Cognitive Diagnosis
Nov 06, 2025The need to remove specific student data from cognitive diagnosis (CD) models has become a pressing requirement, driven by users' growing assertion of their "right to be forgotten". However, existing CD models are largely designed without privacy considerations and lack effective data unlearning mechanisms. Directly applying general purpose unlearning algorithms is suboptimal, as they struggle to balance unlearning completeness, model utility, and efficiency when confronted with the unique heterogeneous structure of CD models. To address this, our paper presents the first systematic study of the data unlearning problem for CD models, proposing a novel and efficient algorithm: hierarchical importanceguided forgetting (HIF). Our key insight is that parameter importance in CD models exhibits distinct layer wise characteristics. HIF leverages this via an innovative smoothing mechanism that combines individual and layer, level importance, enabling a more precise distinction of parameters associated with the data to be unlearned. Experiments on three real world datasets show that HIF significantly outperforms baselines on key metrics, offering the first effective solution for CD models to respond to user data removal requests and for deploying high-performance, privacy preserving AI systems
P-MIA: A Profiled-Based Membership Inference Attack on Cognitive Diagnosis Models
Nov 06, 2025



Cognitive diagnosis models (CDMs) are pivotal for creating fine-grained learner profiles in modern intelligent education platforms. However, these models are trained on sensitive student data, raising significant privacy concerns. While membership inference attacks (MIA) have been studied in various domains, their application to CDMs remains a critical research gap, leaving their privacy risks unquantified. This paper is the first to systematically investigate MIA against CDMs. We introduce a novel and realistic grey box threat model that exploits the explainability features of these platforms, where a model's internal knowledge state vectors are exposed to users through visualizations such as radar charts. We demonstrate that these vectors can be accurately reverse-engineered from such visualizations, creating a potent attack surface. Based on this threat model, we propose a profile-based MIA (P-MIA) framework that leverages both the model's final prediction probabilities and the exposed internal knowledge state vectors as features. Extensive experiments on three real-world datasets against mainstream CDMs show that our grey-box attack significantly outperforms standard black-box baselines. Furthermore, we showcase the utility of P-MIA as an auditing tool by successfully evaluating the efficacy of machine unlearning techniques and revealing their limitations.
STAR-Rec: Making Peace with Length Variance and Pattern Diversity in Sequential Recommendation
May 06, 2025Recent deep sequential recommendation models often struggle to effectively model key characteristics of user behaviors, particularly in handling sequence length variations and capturing diverse interaction patterns. We propose STAR-Rec, a novel architecture that synergistically combines preference-aware attention and state-space modeling through a sequence-level mixture-of-experts framework. STAR-Rec addresses these challenges by: (1) employing preference-aware attention to capture both inherently similar item relationships and diverse preferences, (2) utilizing state-space modeling to efficiently process variable-length sequences with linear complexity, and (3) incorporating a mixture-of-experts component that adaptively routes different behavioral patterns to specialized experts, handling both focused category-specific browsing and diverse category exploration patterns. We theoretically demonstrate how the state space model and attention mechanisms can be naturally unified in recommendation scenarios, where SSM captures temporal dynamics through state compression while attention models both similar and diverse item relationships. Extensive experiments on four real-world datasets demonstrate that STAR-Rec consistently outperforms state-of-the-art sequential recommendation methods, particularly in scenarios involving diverse user behaviors and varying sequence lengths.
Behavior Modeling Space Reconstruction for E-Commerce Search
Jan 30, 2025



Delivering superior search services is crucial for enhancing customer experience and driving revenue growth. Conventionally, search systems model user behaviors by combining user preference and query item relevance statically, often through a fixed logical 'and' relationship. This paper reexamines existing approaches through a unified lens using both causal graphs and Venn diagrams, uncovering two prevalent yet significant issues: entangled preference and relevance effects, and a collapsed modeling space. To surmount these challenges, our research introduces a novel framework, DRP, which enhances search accuracy through two components to reconstruct the behavior modeling space. Specifically, we implement preference editing to proactively remove the relevance effect from preference predictions, yielding untainted user preferences. Additionally, we employ adaptive fusion, which dynamically adjusts fusion criteria to align with the varying patterns of relevance and preference, facilitating more nuanced and tailored behavior predictions within the reconstructed modeling space. Empirical validation on two public datasets and a proprietary search dataset underscores the superiority of our proposed methodology, demonstrating marked improvements in performance over existing approaches.
Advancing Math Reasoning in Language Models: The Impact of Problem-Solving Data, Data Synthesis Methods, and Training Stages
Jan 23, 2025Advancements in LLMs have significantly expanded their capabilities across various domains. However, mathematical reasoning remains a challenging area, prompting the development of math-specific LLMs. These models typically follow a two-stage training paradigm: pre-training with math-related corpora and post-training with problem datasets for SFT. Despite these efforts, the improvements in mathematical reasoning achieved through continued pre-training (CPT) are often less significant compared to those obtained via SFT. This study addresses this discrepancy by exploring alternative strategies during the pre-training phase, focusing on the use of problem-solving data over general mathematical corpora. We investigate three primary research questions: (1) Can problem-solving data enhance the model's mathematical reasoning capabilities more effectively than general mathematical corpora during CPT? (2) Are synthetic data from the same source equally effective, and which synthesis methods are most efficient? (3) How do the capabilities developed from the same problem-solving data differ between the CPT and SFT stages, and what factors contribute to these differences? Our findings indicate that problem-solving data significantly enhances the model's mathematical capabilities compared to general mathematical corpora. We also identify effective data synthesis methods, demonstrating that the tutorship amplification synthesis method achieves the best performance. Furthermore, while SFT facilitates instruction-following abilities, it underperforms compared to CPT with the same data, which can be partially attributed to its poor learning capacity for hard multi-step problem-solving data. These insights provide valuable guidance for optimizing the mathematical reasoning capabilities of LLMs, culminating in our development of a powerful mathematical base model called JiuZhang-8B.
What Are Step-Level Reward Models Rewarding? Counterintuitive Findings from MCTS-Boosted Mathematical Reasoning
Dec 20, 2024Step-level reward models (SRMs) can significantly enhance mathematical reasoning performance through process supervision or step-level preference alignment based on reinforcement learning. The performance of SRMs is pivotal, as they serve as critical guidelines, ensuring that each step in the reasoning process is aligned with desired outcomes. Recently, AlphaZero-like methods, where Monte Carlo Tree Search (MCTS) is employed for automatic step-level preference annotation, have proven particularly effective. However, the precise mechanisms behind the success of SRMs remain largely unexplored. To address this gap, this study delves into the counterintuitive aspects of SRMs, particularly focusing on MCTS-based approaches. Our findings reveal that the removal of natural language descriptions of thought processes has minimal impact on the efficacy of SRMs. Furthermore, we demonstrate that SRMs are adept at assessing the complex logical coherence present in mathematical language while having difficulty in natural language. These insights provide a nuanced understanding of the core elements that drive effective step-level reward modeling in mathematical reasoning. By shedding light on these mechanisms, this study offers valuable guidance for developing more efficient and streamlined SRMs, which can be achieved by focusing on the crucial parts of mathematical reasoning.
Efficient and Robust Regularized Federated Recommendation
Nov 03, 2024



Recommender systems play a pivotal role across practical scenarios, showcasing remarkable capabilities in user preference modeling. However, the centralized learning paradigm predominantly used raises serious privacy concerns. The federated recommender system (FedRS) addresses this by updating models on clients, while a central server orchestrates training without accessing private data. Existing FedRS approaches, however, face unresolved challenges, including non-convex optimization, vulnerability, potential privacy leakage risk, and communication inefficiency. This paper addresses these challenges by reformulating the federated recommendation problem as a convex optimization issue, ensuring convergence to the global optimum. Based on this, we devise a novel method, RFRec, to tackle this optimization problem efficiently. In addition, we propose RFRecF, a highly efficient version that incorporates non-uniform stochastic gradient descent to improve communication efficiency. In user preference modeling, both methods learn local and global models, collaboratively learning users' common and personalized interests under the federated learning setting. Moreover, both methods significantly enhance communication efficiency, robustness, and privacy protection, with theoretical support. Comprehensive evaluations on four benchmark datasets demonstrate RFRec and RFRecF's superior performance compared to diverse baselines.
LinRec: Linear Attention Mechanism for Long-term Sequential Recommender Systems
Nov 03, 2024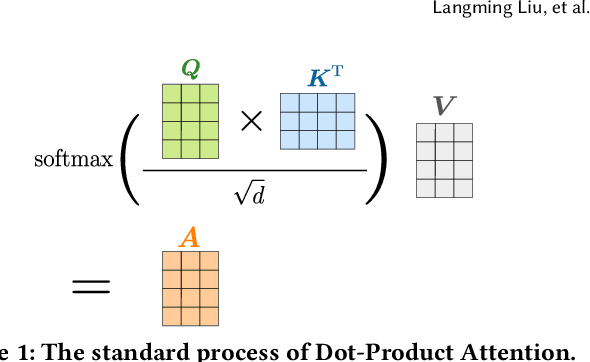
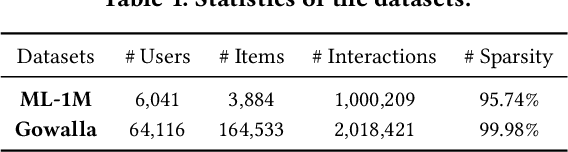
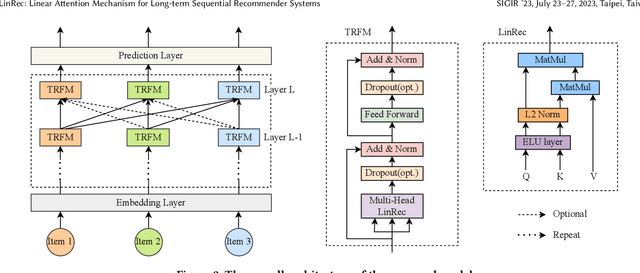
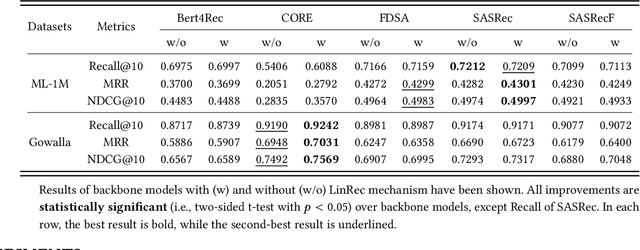
Transformer models have achieved remarkable success in sequential recommender systems (SRSs). However, computing the attention matrix in traditional dot-product attention mechanisms results in a quadratic complexity with sequence lengths, leading to high computational costs for long-term sequential recommendation. Motivated by the above observation, we propose a novel L2-Normalized Linear Attention for the Transformer-based Sequential Recommender Systems (LinRec), which theoretically improves efficiency while preserving the learning capabilities of the traditional dot-product attention. Specifically, by thoroughly examining the equivalence conditions of efficient attention mechanisms, we show that LinRec possesses linear complexity while preserving the property of attention mechanisms. In addition, we reveal its latent efficiency properties by interpreting the proposed LinRec mechanism through a statistical lens. Extensive experiments are conducted based on two public benchmark datasets, demonstrating that the combination of LinRec and Transformer models achieves comparable or even superior performance than state-of-the-art Transformer-based SRS models while significantly improving time and memory efficiency.
Expediting and Elevating Large Language Model Reasoning via Hidden Chain-of-Thought Decoding
Sep 13, 2024Large language models (LLMs) have demonstrated remarkable capabilities in tasks requiring reasoning and multi-step problem-solving through the use of chain-of-thought (CoT) prompting. However, generating the full CoT process results in significantly longer output sequences, leading to increased computational costs and latency during inference. To address this challenge, we propose a novel approach to compress the CoT process through semantic alignment, enabling more efficient decoding while preserving the benefits of CoT reasoning. Our method introduces an auxiliary CoT model that learns to generate and compress the full thought process into a compact special token representation semantically aligned with the original CoT output. This compressed representation is then integrated into the input of the Hidden Chain-of-Thought (HCoT) model. The training process follows a two-stage procedure: First, the CoT model is optimized to generate the compressed token representations aligned with the ground-truth CoT outputs using a contrastive loss. Subsequently, with the CoT model parameters frozen, the HCoT model is fine-tuned to generate accurate subsequent predictions conditioned on the prefix instruction and the compressed CoT representations from the CoT model. Extensive experiments across three challenging domains - mathematical reasoning, agent invocation, and question answering - demonstrate that our semantic compression approach achieves competitive or improved performance compared to the full CoT baseline, while providing significant speedups of at least 1.5x in decoding time. Moreover, incorporating contrastive learning objectives further enhances the quality of the compressed representations, leading to better CoT prompting and improved task accuracy. Our work paves the way for more efficient exploitation of multi-step reasoning capabilities in LLMs across a wide range of applications.