 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Knowledge Tracing Models via k-Sparse Attention
Paper and Code
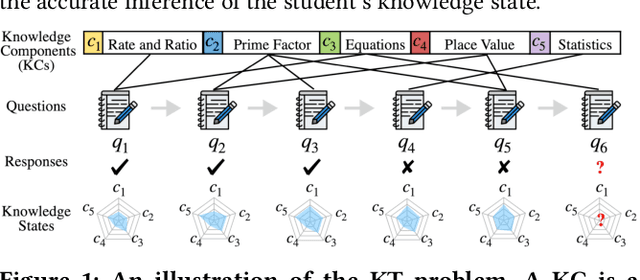
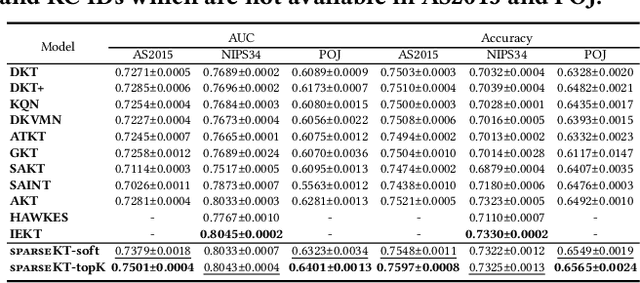
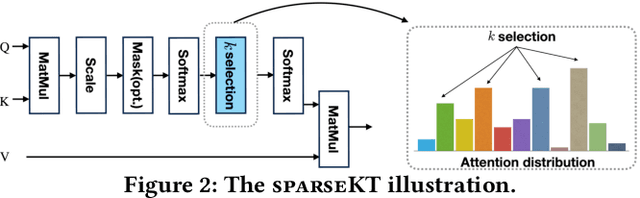
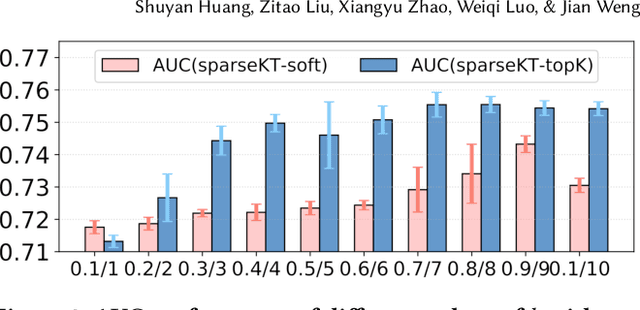
Knowledge tracing (KT) is the problem of predicting students' future performance based on their historical interaction sequences. With the advanced capability of capturing contextual long-term dependency, attention mechanism becomes one of the essential components in many deep learning based KT (DLKT) models. In spite of the impressive performance achieved by these attentional DLKT models, many of them are often vulnerable to run the risk of overfitting, especially on small-scale educational datasets. Therefore, in this paper, we propose \textsc{sparseKT}, a simple yet effective framework to improve the robustness and generalization of the attention based DLKT approaches. Specifically, we incorporate a k-selection module to only pick items with the highest attention scores. We propose two sparsification heuristics : (1) soft-thresholding sparse attention and (2) top-$K$ sparse attention. We show that our \textsc{sparseKT} is able to help attentional KT models get rid of irrelevant student interactions and have comparable predictive performance when compared to 11 state-of-the-art KT models on three publicly available real-world educational datasets. To encourage reproducible research, we make our data and code publicly available at \url{https://github.com/pykt-team/pykt-toolkit}\footnote{We merged our model to the \textsc{pyKT} benchmark at \url{https://pykt.org/}.}.