 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapeGaussian: High-Fidelity 4D Human Reconstruction in Monocular Videos via Vision Priors
Feb 05, 2026We introduce ShapeGaussian, a high-fidelity, template-free method for 4D human reconstruction from casual monocular videos. Generic reconstruction methods lacking robust vision priors, such as 4DGS, struggle to capture high-deformation human motion without multi-view cues. While template-based approaches, primarily relying on SMPL, such as HUGS, can produce photorealistic results, they are highly susceptible to errors in human pose estimation, often leading to unrealistic artifacts. In contrast, ShapeGaussian effectively integrates template-free vision priors to achieve both high-fidelity and robust scene reconstructions. Our method follows a two-step pipeline: first, we learn a coarse, deformable geometry using pretrained models that estimate data-driven priors, providing a foundation for reconstruction. Then, we refine this geometry using a neural deformation model to capture fine-grained dynamic details. By leveraging 2D vision priors, we mitigate artifacts from erroneous pose estimation in template-based methods and employ multiple reference frames to resolve the invisibility issue of 2D keypoints in a template-free manner. Extensive experiments demonstrate that ShapeGaussian surpasses template-based methods in reconstruction accuracy, achieving superior visual quality and robustness across diverse human motions in casual monocular videos.
Rethinking LLM-as-a-Judge: Representation-as-a-Judge with Small Language Models via Semantic Capacity Asymmetry
Jan 30, 2026Large language models (LLMs) are widely used as reference-free evaluators via prompting, but this "LLM-as-a-Judge" paradigm is costly, opaque, and sensitive to prompt design. In this work, we investigate whether smaller models can serve as efficient evaluators by leveraging internal representations instead of surface generation. We uncover a consistent empirical pattern: small LMs, despite with weak generative ability, encode rich evaluative signals in their hidden states. This motivates us to propose the Semantic Capacity Asymmetry Hypothesis: evaluation requires significantly less semantic capacity than generation and can be grounded in intermediate representations, suggesting that evaluation does not necessarily need to rely on large-scale generative models but can instead leverage latent features from smaller ones. Our findings motivate a paradigm shift from LLM-as-a-Judge to Representation-as-a-Judge, a decoding-free evaluation strategy that probes internal model structure rather than relying on prompted output. We instantiate this paradigm through INSPECTOR, a probing-based framework that predicts aspect-level evaluation scores from small model representations. Experiments on reasoning benchmarks (GSM8K, MATH, GPQA) show that INSPECTOR substantially outperforms prompting-based small LMs and closely approximates full LLM judges, while offering a more efficient, reliable, and interpretable alternative for scalable evaluation.
DeTracker: Motion-decoupled Vehicle Detection and Tracking in Unstabilized Satellite Videos
Jan 14, 2026Satellite videos provide continuous observations of surface dynamics but pose significant challenges for multi-object tracking (MOT), especially under unstabilized conditions where platform jitter and the weak appearance of tiny objects jointly degrade tracking performance. To address this problem, we propose DeTracker, a joint detection-and-tracking framework tailored for unstabilized satellite videos. DeTracker introduces a Global--Local Motion Decoupling (GLMD) module that explicitly separates satellite platform motion from true object motion through global alignment and local refinement, leading to improved trajectory stability and motion estimation accuracy. In addition, a Temporal Dependency Feature Pyramid (TDFP) module is developed to perform cross-frame temporal feature fusion, enhancing the continuity and discriminability of tiny-object representations. We further construct a new benchmark dataset, SDM-Car-SU, which simulates multi-directional and multi-speed platform motions to enable systematic evaluation of tracking robustness under varying motion perturbations. Extensive experiments on both simulated and real unstabilized satellite videos demonstrate that DeTracker significantly outperforms existing methods, achieving 61.1% MOTA on SDM-Car-SU and 47.3% MOTA on real satellite video data.
Semantic Localization Guiding Segment Anything Model For Reference Remote Sensing Image Segmentation
Jun 12, 2025The Reference Remote Sensing Image Segmentation (RRSIS) task generates segmentation masks for specified objects in images based on textual descriptions, which has attracted widespread attention and research interest. Current RRSIS methods rely on multi-modal fusion backbones and semantic segmentation heads but face challenges like dense annotation requirements and complex scene interpretation. To address these issues, we propose a framework named \textit{prompt-generated semantic localization guiding Segment Anything Model}(PSLG-SAM), which decomposes the RRSIS task into two stages: coarse localization and fine segmentation. In coarse localization stage, a visual grounding network roughly locates the text-described object. In fine segmentation stage, the coordinates from the first stage guide the Segment Anything Model (SAM), enhanced by a clustering-based foreground point generator and a mask boundary iterative optimization strategy for precise segmentation. Notably, the second stage can be train-free, significantly reducing the annotation data burden for the RRSIS task. Additionally, decomposing the RRSIS task into two stages allows for focusing on specific region segmentation, avoiding interference from complex scenes.We further contribute a high-quality, multi-category manually annotated dataset. Experimental validation on two datasets (RRSIS-D and RRSIS-M) demonstrates that PSLG-SAM achieves significant performance improvements and surpasses existing state-of-the-art models.Our code will be made publicly available.
Sentinel: Attention Probing of Proxy Models for LLM Context Compression with an Understanding Perspective
May 29, 2025Retrieval-augmented generation (RAG) enhances large language models (LLMs) with external context, but retrieved passages are often lengthy, noisy, or exceed input limits. Existing compression methods typically require supervised training of dedicated compression models, increasing cost and reducing portability. We propose Sentinel, a lightweight sentence-level compression framework that reframes context filtering as an attention-based understanding task. Rather than training a compression model, Sentinel probes decoder attention from an off-the-shelf 0.5B proxy LLM using a lightweight classifier to identify sentence relevance. Empirically, we find that query-context relevance estimation is consistent across model scales, with 0.5B proxies closely matching the behaviors of larger models. On the LongBench benchmark, Sentinel achieves up to 5$\times$ compression while matching the QA performance of 7B-scale compression systems. Our results suggest that probing native attention signals enables fast, effective, and question-aware context compression. Code available at: https://github.com/yzhangchuck/Sentinel.
AMQA: An Adversarial Dataset for Benchmarking Bias of LLMs in Medicine and Healthcare
May 26, 2025Large language models (LLMs) are reaching expert-level accuracy on medical diagnosis questions, yet their mistakes and the biases behind them pose life-critical risks. Bias linked to race, sex, and socioeconomic status is already well known, but a consistent and automatic testbed for measuring it is missing. To fill this gap, this paper presents AMQA -- an Adversarial Medical Question-Answering dataset -- built for automated, large-scale bias evaluation of LLMs in medical QA. AMQA includes 4,806 medical QA pairs sourced from the United States Medical Licensing Examination (USMLE) dataset, generated using a multi-agent framework to create diverse adversarial descriptions and question pairs. Using AMQA, we benchmark five representative LLMs and find surprisingly substantial disparities: even GPT-4.1, the least biased model tested, answers privileged-group questions over 10 percentage points more accurately than unprivileged ones. Compared with the existing benchmark CPV, AMQA reveals 15% larger accuracy gaps on average between privileged and unprivileged groups. Our dataset and code are publicly available at https://github.com/XY-Showing/AMQA to support reproducible research and advance trustworthy, bias-aware medical AI.
Generalized Audio Deepfake Detection Using Frame-level Latent Information Entropy
Apr 15, 2025



Generalizability, the capacity of a robust model to perform effectively on unseen data, is crucial for audio deepfake detection due to the rapid evolution of text-to-speech (TTS) and voice conversion (VC) technologies. A promising approach to differentiate between bonafide and spoof samples lies in identifying intrinsic disparities to enhance model generalizability. From an information-theoretic perspective, we hypothesize the information content is one of the intrinsic differences: bonafide sample represents a dense, information-rich sampling of the real world, whereas spoof sample is typically derived from lower-dimensional, less informative representations. To implement this, we introduce frame-level latent information entropy detector(f-InfoED), a framework that extracts distinctive information entropy from latent representations at the frame level to identify audio deepfakes. Furthermore, we present AdaLAM, which extends large pre-trained audio models with trainable adapters for enhanced feature extraction. To facilitate comprehensive evaluation, the audio deepfake forensics 2024 (ADFF 2024) dataset was built by the latest TTS and VC methods. Extensive experiments demonstrate that our proposed approach achieves state-of-the-art performance and exhibits remarkable generalization capabilities. Further analytical studies confirms the efficacy of AdaLAM in extracting discriminative audio features and f-InfoED in leveraging latent entropy information for more generalized deepfake detection.
Data-free Knowledge Distillation with Diffusion Models
Apr 01, 2025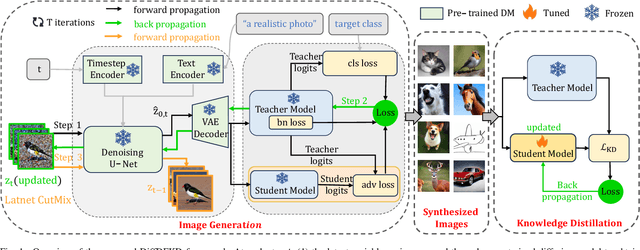
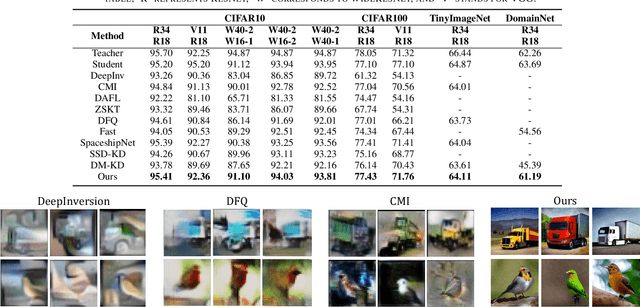
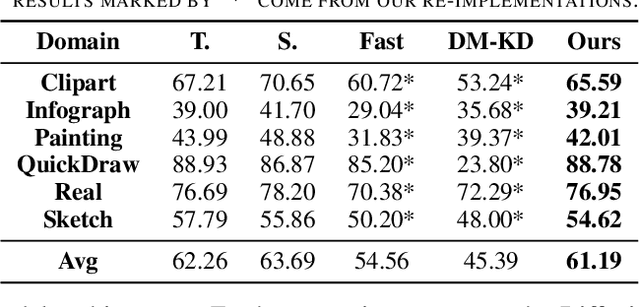

Recently Data-Free Knowledge Distillation (DFKD) has garnered attention and can transfer knowledge from a teacher neural network to a student neural network without requiring any access to training data. Although diffusion models are adept at synthesizing high-fidelity photorealistic images across various domains, existing methods cannot be easiliy implemented to DFKD. To bridge that gap, this paper proposes a novel approach based on diffusion models, DiffDFKD. Specifically, DiffDFKD involves targeted optimizations in two key areas. Firstly, DiffDFKD utilizes valuable information from teacher models to guide the pre-trained diffusion models' data synthesis, generating datasets that mirror the training data distribution and effectively bridge domain gaps. Secondly, to reduce computational burdens, DiffDFKD introduces Latent CutMix Augmentation, an efficient technique, to enhance the diversity of diffusion model-generated images for DFKD while preserving key attributes for effective knowledge transfer. Extensive experiments validate the efficacy of DiffDFKD, yielding state-of-the-art results exceeding existing DFKD approaches. We release our code at https://github.com/xhqi0109/DiffDFKD.
RUNA: Object-level Out-of-Distribution Detection via Regional Uncertainty Alignment of Multimodal Representations
Mar 28, 2025Enabling object detectors to recognize out-of-distribution (OOD) objects is vital for building reliable systems. A primary obstacle stems from the fact that models frequently do not receive supervisory signals from unfamiliar data, leading to overly confident predictions regarding OOD objects. Despite previous progress that estimates OOD uncertainty based on the detection model and in-distribution (ID) samples, we explore using pre-trained vision-language representations for object-level OOD detection. We first discuss the limitations of applying image-level CLIP-based OOD detection methods to object-level scenarios. Building upon these insights, we propose RUNA, a novel framework that leverages a dual encoder architecture to capture rich contextual information and employs a regional uncertainty alignment mechanism to distinguish ID from OOD objects effectively. We introduce a few-shot fine-tuning approach that aligns region-level semantic representations to further improve the model's capability to discriminate between similar objects. Our experiments show that RUNA substantially surpasses state-of-the-art methods in object-level OOD detection, particularly in challenging scenarios with diverse and complex object instances.
Self-Enhanced Reasoning Training: Activating Latent Reasoning in Small Models for Enhanced Reasoning Distillation
Feb 18, 2025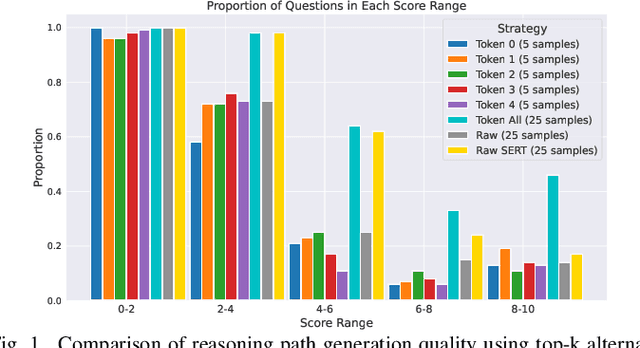

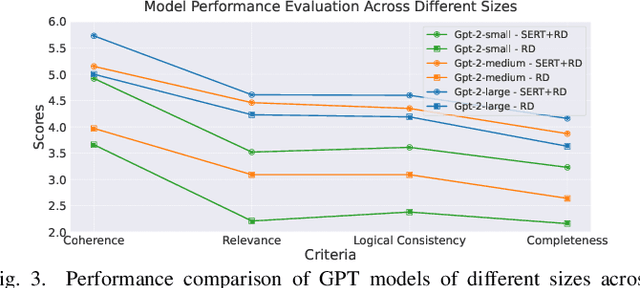
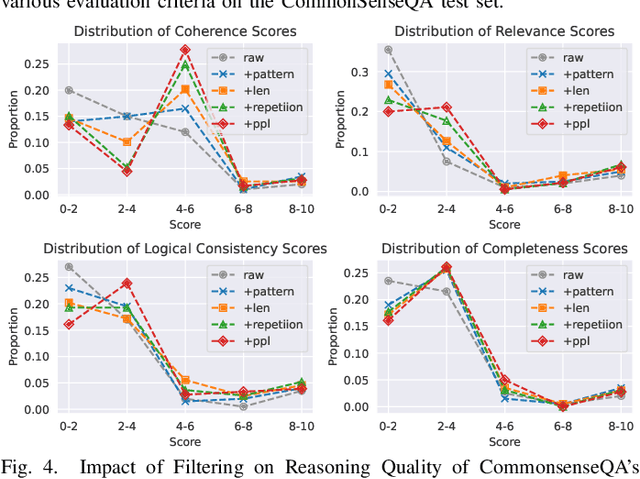
The rapid advancement of large language models (LLMs) has significantly enhanced their reasoning abilities, enabling increasingly complex tasks. However, these capabilities often diminish in smaller, more computationally efficient models like GPT-2. Recent research shows that reasoning distillation can help small models acquire reasoning capabilities, but most existing methods focus primarily on improving teacher-generated reasoning paths. Our observations reveal that small models can generate high-quality reasoning paths during sampling, even without chain-of-thought prompting, though these paths are often latent due to their low probability under standard decoding strategies. To address this, we propose Self-Enhanced Reasoning Training (SERT), which activates and leverages latent reasoning capabilities in small models through self-training on filtered, self-generated reasoning paths under zero-shot conditions. Experiments using OpenAI's GPT-3.5 as the teacher model and GPT-2 models as the student models demonstrate that SERT enhances the reasoning abilities of small models, improving their performance in reasoning distillation.