 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsity via Hyperpriors: A Theoretical and Algorithmic Study under Empirical Bayes Framework
Nov 09, 2025This paper presents a comprehensive analysis of hyperparameter estimation within the empirical Bayes framework (EBF) for sparse learning. By studying the influence of hyperpriors on the solution of EBF, we establish a theoretical connection between the choice of the hyperprior and the sparsity as well as the local optimality of the resulting solutions. We show that some strictly increasing hyperpriors, such as half-Laplace and half-generalized Gaussian with the power in $(0,1)$, effectively promote sparsity and improve solution stability with respect to measurement noise. Based on this analysis, we adopt a proximal alternating linearized minimization (PALM) algorithm with convergence guaranties for both convex and concave hyperpriors. Extensive numerical tests on two-dimensional image deblurring problems demonstrate that introducing appropriate hyperpriors significantly promotes the sparsity of the solution and enhances restoration accuracy. Furthermore, we illustrate the influence of the noise level and the ill-posedness of inverse problems to EBF solutions.
Self-Enhanced Reasoning Training: Activating Latent Reasoning in Small Models for Enhanced Reasoning Distillation
Feb 18, 2025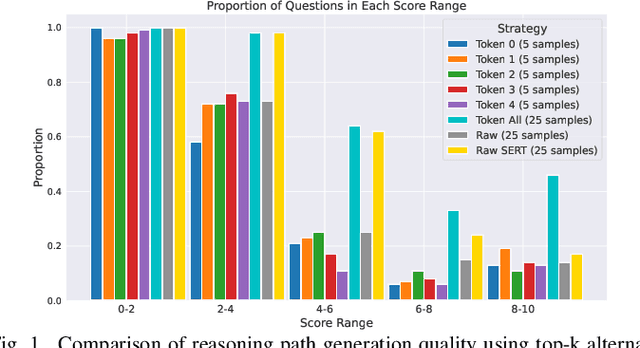

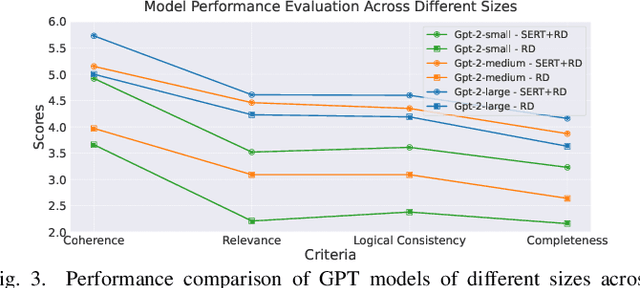
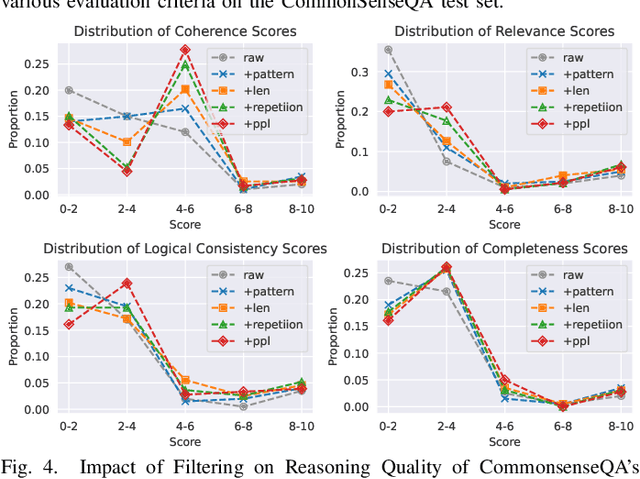
The rapid advancement of large language models (LLMs) has significantly enhanced their reasoning abilities, enabling increasingly complex tasks. However, these capabilities often diminish in smaller, more computationally efficient models like GPT-2. Recent research shows that reasoning distillation can help small models acquire reasoning capabilities, but most existing methods focus primarily on improving teacher-generated reasoning paths. Our observations reveal that small models can generate high-quality reasoning paths during sampling, even without chain-of-thought prompting, though these paths are often latent due to their low probability under standard decoding strategies. To address this, we propose Self-Enhanced Reasoning Training (SERT), which activates and leverages latent reasoning capabilities in small models through self-training on filtered, self-generated reasoning paths under zero-shot conditions. Experiments using OpenAI's GPT-3.5 as the teacher model and GPT-2 models as the student models demonstrate that SERT enhances the reasoning abilities of small models, improving their performance in reasoning distillation.
Dynamic Attention-Guided Context Decoding for Mitigating Context Faithfulness Hallucinations in Large Language Models
Jan 02, 2025



Large language models (LLMs) often suffer from context faithfulness hallucinations, where outputs deviate from retrieved information due to insufficient context utilization and high output uncertainty. Our uncertainty evaluation experiments reveal a strong correlation between high uncertainty and hallucinations. We hypothesize that attention mechanisms encode signals indicative of contextual utilization, validated through probing analysis. Based on these insights, we propose Dynamic Attention-Guided Context Decoding (DAGCD), a lightweight framework that integrates attention distributions and uncertainty signals in a single-pass decoding process. Experiments across QA datasets demonstrate DAGCD's effectiveness, achieving significant improvements in faithfulness and robustness while maintaining computational efficiency.
Rethinking Layer Removal: Preserving Critical Components with Task-Aware Singular Value Decomposition
Dec 31, 2024


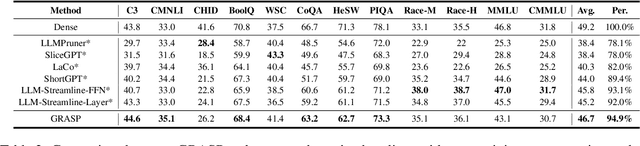
Layer removal has emerged as a promising approach for compressing large language models (LLMs) by leveraging redundancy within layers to reduce model size and accelerate inference. However, this technique often compromises internal consistency, leading to performance degradation and instability, with varying impacts across different model architectures. In this work, we propose Taco-SVD, a task-aware framework that retains task-critical singular value directions, preserving internal consistency while enabling efficient compression. Unlike direct layer removal, Taco-SVD preserves task-critical transformations to mitigate performance degradation. By leveraging gradient-based attribution methods, Taco-SVD aligns singular values with downstream task objectives. Extensive evaluations demonstrate that Taco-SVD outperforms existing methods in perplexity and task performance across different architectures while ensuring minimal computational overhead.
PFID: Privacy First Inference Delegation Framework for LLMs
Jun 18, 2024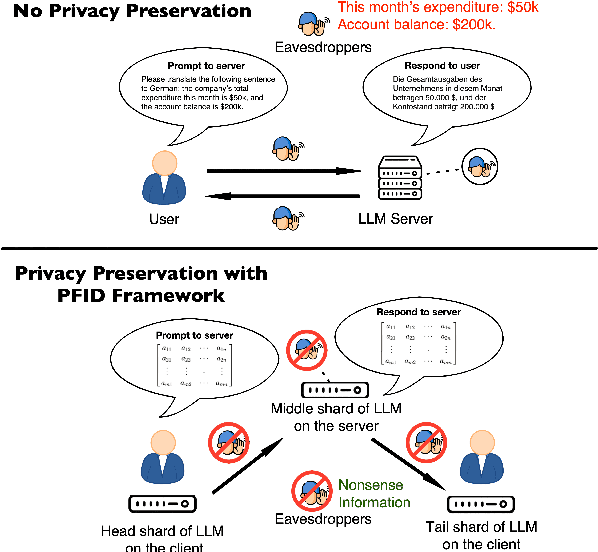

This paper introduces a novel privacy-preservation framework named PFID for LLMs that addresses critical privacy concerns by localizing user data through model sharding and singular value decomposition. When users are interacting with LLM systems, their prompts could be subject to being exposed to eavesdroppers within or outside LLM system providers who are interested in collecting users' input. In this work, we proposed a framework to camouflage user input, so as to alleviate privacy issues. Our framework proposes to place model shards on the client and the public server, we sent compressed hidden states instead of prompts to and from servers. Clients have held back information that can re-privatized the hidden states so that overall system performance is comparable to traditional LLMs services. Our framework was designed to be communication efficient, computation can be delegated to the local client so that the server's computation burden can be lightened. We conduct extensive experiments on machine translation tasks to verify our framework's performance.
QLSC: A Query Latent Semantic Calibrator for Robust Extractive Question Answering
Apr 30, 2024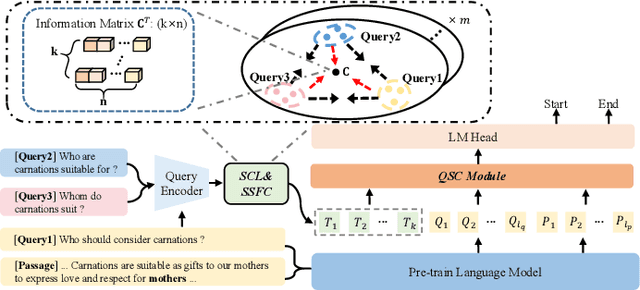
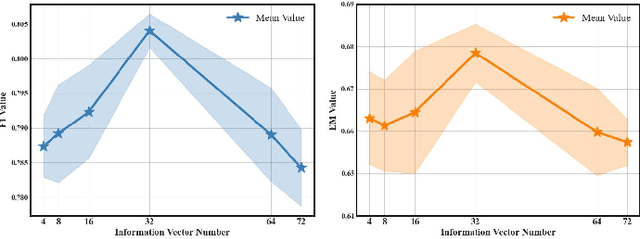
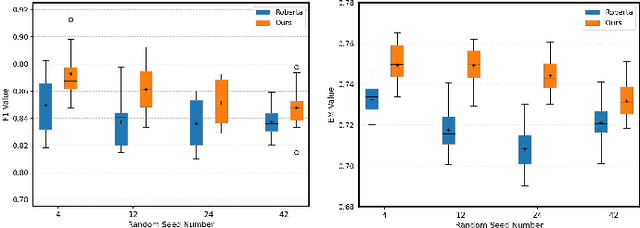
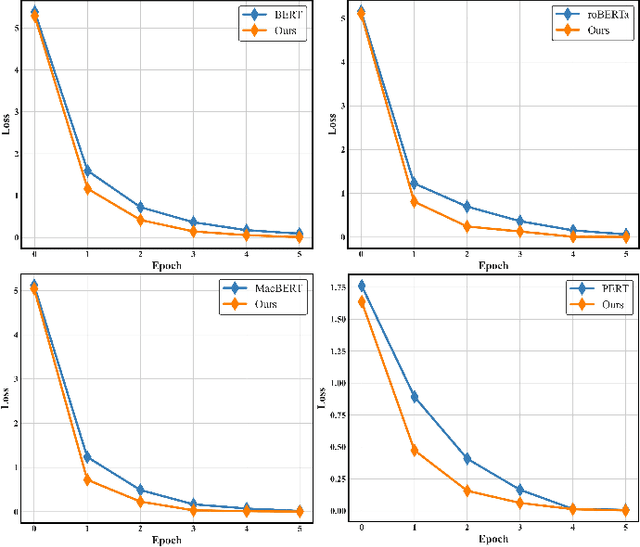
Extractive Question Answering (EQA) in Machine Reading Comprehension (MRC) often faces the challenge of dealing with semantically identical but format-variant inputs. Our work introduces a novel approach, called the ``Query Latent Semantic Calibrator (QLSC)'', designed as an auxiliary module for existing MRC models. We propose a unique scaling strategy to capture latent semantic center features of queries. These features are then seamlessly integrated into traditional query and passage embeddings using an attention mechanism. By deepening the comprehension of the semantic queries-passage relationship, our approach diminishes sensitivity to variations in text format and boosts the model's capability in pinpointing accurate answers. Experimental results on robust Question-Answer datasets confirm that our approach effectively handles format-variant but semantically identical queries, highlighting the effectiveness and adaptability of our proposed method.
Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning
Feb 01, 2024



Instruction tuning is critical to improve LLMs but usually suffers from low-quality and redundant data. Data filtering for instruction tuning has proved important in improving both the efficiency and performance of the tuning process. But it also leads to extra cost and computation due to the involvement of LLMs in this process. To reduce the filtering cost, we study Superfiltering: Can we use a smaller and weaker model to select data for finetuning a larger and stronger model? Despite the performance gap between weak and strong language models, we find their highly consistent capability to perceive instruction difficulty and data selection results. This enables us to use a much smaller and more efficient model to filter the instruction data used to train a larger language model. Not only does it largely speed up the data filtering, but the filtered-data-finetuned LLM achieves even better performance on standard benchmarks. Extensive experiments validate the efficacy and efficiency of our approach.
Leveraging Biases in Large Language Models: "bias-kNN'' for Effective Few-Shot Learning
Jan 18, 2024Large Language Models (LLMs) have shown significant promise in various applications, including zero-shot and few-shot learning. However, their performance can be hampered by inherent biases. Instead of traditionally sought methods that aim to minimize or correct these biases, this study introduces a novel methodology named ``bias-kNN''. This approach capitalizes on the biased outputs, harnessing them as primary features for kNN and supplementing with gold labels. Our comprehensive evaluations, spanning diverse domain text classification datasets and different GPT-2 model sizes, indicate the adaptability and efficacy of the ``bias-kNN'' method. Remarkably, this approach not only outperforms conventional in-context learning in few-shot scenarios but also demonstrates robustness across a spectrum of samples, templates and verbalizers. This study, therefore, presents a unique perspective on harnessing biases, transforming them into assets for enhanced model performance.
High-resolution myelin-water fraction and quantitative relaxation mapping using 3D ViSTa-MR fingerprinting
Dec 21, 2023Purpose: This study aims to develop a high-resolution whole-brain multi-parametric quantitative MRI approach for simultaneous mapping of myelin-water fraction (MWF), T1, T2, and proton-density (PD), all within a clinically feasible scan time. Methods: We developed 3D ViSTa-MRF, which combined Visualization of Short Transverse relaxation time component (ViSTa) technique with MR Fingerprinting (MRF), to achieve high-fidelity whole-brain MWF and T1/T2/PD mapping on a clinical 3T scanner. To achieve fast acquisition and memory-efficient reconstruction, the ViSTa-MRF sequence leverages an optimized 3D tiny-golden-angle-shuffling spiral-projection acquisition and joint spatial-temporal subspace reconstruction with optimized preconditioning algorithm. With the proposed ViSTa-MRF approach, high-fidelity direct MWF mapping was achieved without a need for multi-compartment fitting that could introduce bias and/or noise from additional assumptions or priors. Results: The in-vivo results demonstrate the effectiveness of the proposed acquisition and reconstruction framework to provide fast multi-parametric mapping with high SNR and good quality. The in-vivo results of 1mm- and 0.66mm-iso datasets indicate that the MWF values measured by the proposed method are consistent with standard ViSTa results that are 30x slower with lower SNR. Furthermore, we applied the proposed method to enable 5-minute whole-brain 1mm-iso assessment of MWF and T1/T2/PD mappings for infant brain development and for post-mortem brain samples. Conclusions: In this work, we have developed a 3D ViSTa-MRF technique that enables the acquisition of whole-brain MWF, quantitative T1, T2, and PD maps at 1mm and 0.66mm isotropic resolution in 5 and 15 minutes, respectively. This advancement allows for quantitative investigations of myelination changes in the brain.
PRCA: Fitting Black-Box Large Language Models for Retrieval Question Answering via Pluggable Reward-Driven Contextual Adapter
Oct 23, 2023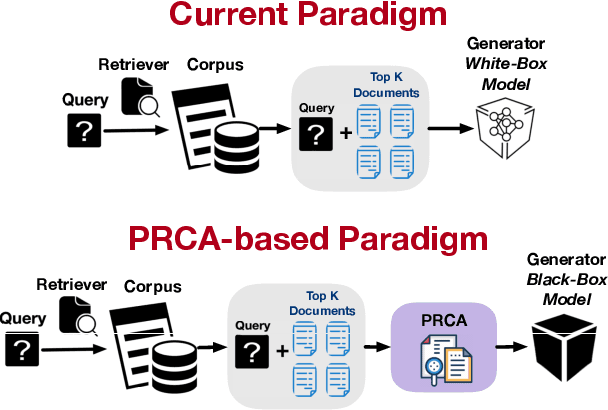
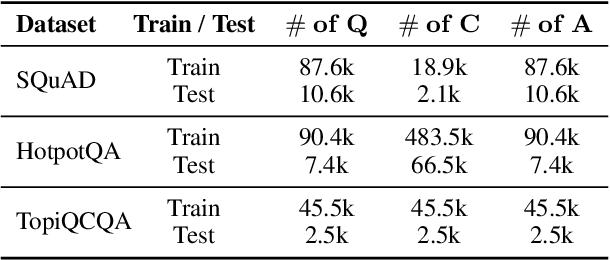
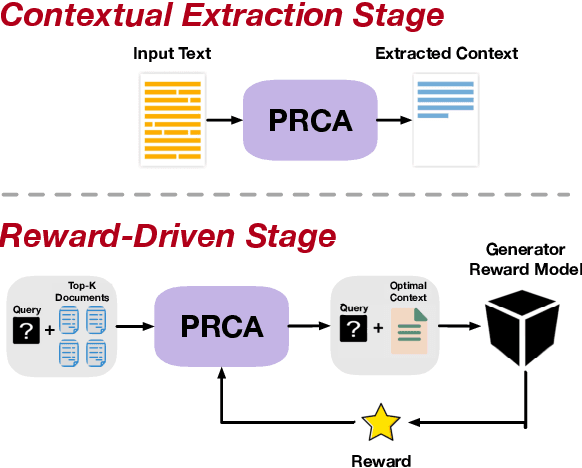

The Retrieval Question Answering (ReQA) task employs the retrieval-augmented framework, composed of a retriever and generator. The generator formulates the answer based on the documents retrieved by the retriever. Incorporating Large Language Models (LLMs) as generators is beneficial due to their advanced QA capabilities, but they are typically too large to be fine-tuned with budget constraints while some of them are only accessible via APIs. To tackle this issue and further improve ReQA performance, we propose a trainable Pluggable Reward-Driven Contextual Adapter (PRCA), keeping the generator as a black box. Positioned between the retriever and generator in a Pluggable manner, PRCA refines the retrieved information by operating in a token-autoregressive strategy via maximizing rewards of the reinforcement learning phase. Our experiments validate PRCA's effectiveness in enhancing ReQA performance on three datasets by up to 20% improvement to fit black-box LLMs into existing frameworks, demonstrating its considerable potential in the LLMs era.