 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn More with Less: Uncertainty Consistency Guided Query Selection for RLVR
Jan 30, 2026Large Language Models (LLMs) have recently improved mathematical reasoning through Reinforcement Learning with Verifiable Reward (RLVR). However, existing RLVR algorithms require large query budgets, making annotation costly. We investigate whether fewer but more informative queries can yield similar or superior performance, introducing active learning (AL) into RLVR. We identify that classic AL sampling strategies fail to outperform random selection in this setting, due to ignoring objective uncertainty when only selecting by subjective uncertainty. This work proposes an uncertainty consistency metric to evaluate how well subjective uncertainty aligns with objective uncertainty. In the offline setting, this alignment is measured using the Point-Biserial Correlation Coefficient (PBC). For online training, because of limited sampling and dynamically shifting output distributions, PBC estimation is difficult. Therefore, we introduce a new online variant, computed from normalized advantage and subjective uncertainty. Theoretically, we prove that the online variant is strictly negatively correlated with offline PBC and supports better sample selection. Experiments show our method consistently outperforms random and classic AL baselines, achieving full-dataset performance while training on only 30% of the data, effectively reducing the cost of RLVR for reasoning tasks.
AMAP Agentic Planning Technical Report
Dec 31, 2025We present STAgent, an agentic large language model tailored for spatio-temporal understanding, designed to solve complex tasks such as constrained point-of-interest discovery and itinerary planning. STAgent is a specialized model capable of interacting with ten distinct tools within spatio-temporal scenarios, enabling it to explore, verify, and refine intermediate steps during complex reasoning. Notably, STAgent effectively preserves its general capabilities. We empower STAgent with these capabilities through three key contributions: (1) a stable tool environment that supports over ten domain-specific tools, enabling asynchronous rollout and training; (2) a hierarchical data curation framework that identifies high-quality data like a needle in a haystack, curating high-quality queries with a filter ratio of 1:10,000, emphasizing both diversity and difficulty; and (3) a cascaded training recipe that starts with a seed SFT stage acting as a guardian to measure query difficulty, followed by a second SFT stage fine-tuned on queries with high certainty, and an ultimate RL stage that leverages data of low certainty. Initialized with Qwen3-30B-A3B to establish a strong SFT foundation and leverage insights into sample difficulty, STAgent yields promising performance on TravelBench while maintaining its general capabilities across a wide range of general benchmarks, thereby demonstrating the effectiveness of our proposed agentic model.
Towards Reward Fairness in RLHF: From a Resource Allocation Perspective
May 29, 2025Rewards serve as proxies for human preferences and play a crucial role in Reinforcement Learning from Human Feedback (RLHF). However, if these rewards are inherently imperfect, exhibiting various biases, they can adversely affect the alignment of large language models (LLMs). In this paper, we collectively define the various biases present in rewards as the problem of reward unfairness. We propose a bias-agnostic method to address the issue of reward fairness from a resource allocation perspective, without specifically designing for each type of bias, yet effectively mitigating them. Specifically, we model preference learning as a resource allocation problem, treating rewards as resources to be allocated while considering the trade-off between utility and fairness in their distribution. We propose two methods, Fairness Regularization and Fairness Coefficient, to achieve fairness in rewards. We apply our methods in both verification and reinforcement learning scenarios to obtain a fairness reward model and a policy model, respectively. Experiments conducted in these scenarios demonstrate that our approach aligns LLMs with human preferences in a more fair manner.
Coarse-to-Fine Process Reward Modeling for Enhanced Mathematical Reasoning
Jan 23, 2025



Process reward model (PRM) is critical for mathematical reasoning tasks to assign rewards for each intermediate steps. The PRM requires constructing process-wise supervision data for training, which rely on chain-of-thought (CoT) or tree-based methods to construct the reasoning steps, however, the individual reasoning steps may be redundant or containing nuanced errors that difficult to detect. We attribute these to the issue of the overlook of granularity division during process data collection. In this paper, we propose a coarse-to-fine framework to tackle this issue. Specifically, while gathering the process supervision data, we collect the coarse reasoning steps by merging adjacent steps according to preset merging granularity, then we sequentially reduce the merging granularity to collect fine-grained reasoning steps. For each synthesized new step, we relabel according to the label of last step. During training, we also traverse the collected training corpus in a coarse-to-fine manner. We conduct extensive experiments on popular mathematical reasoning datasets across diverse loss criterions, the proposed framework can consistently boost the reasoning performance.
GUNDAM: Aligning Large Language Models with Graph Understanding
Sep 30, 2024



Large Language Models (LLMs) have achieved impressive results in processing text data, which has sparked interest in applying these models beyond textual data, such as graphs. In the field of graph learning, there is a growing interest in harnessing LLMs to comprehend and manipulate graph-structured data. Existing research predominantly focuses on graphs with rich textual features, such as knowledge graphs or text attribute graphs, leveraging LLMs' ability to process text but inadequately addressing graph structure. This work specifically aims to assess and enhance LLMs' abilities to comprehend and utilize the structural knowledge inherent in graph data itself, rather than focusing solely on graphs rich in textual content. To achieve this, we introduce the \textbf{G}raph \textbf{U}nderstanding for \textbf{N}atural Language \textbf{D}riven \textbf{A}nalytical \textbf{M}odel (\model). This model adapts LLMs to better understand and engage with the structure of graph data, enabling them to perform complex reasoning tasks by leveraging the graph's structure itself. Our experimental evaluations on graph reasoning benchmarks not only substantiate that \model~ outperforms the SOTA baselines for comparisons. But also reveals key factors affecting the graph reasoning capabilities of LLMs. Moreover, we provide a theoretical analysis illustrating how reasoning paths can enhance LLMs' reasoning capabilities.
Preserving Node Distinctness in Graph Autoencoders via Similarity Distillation
Jun 25, 2024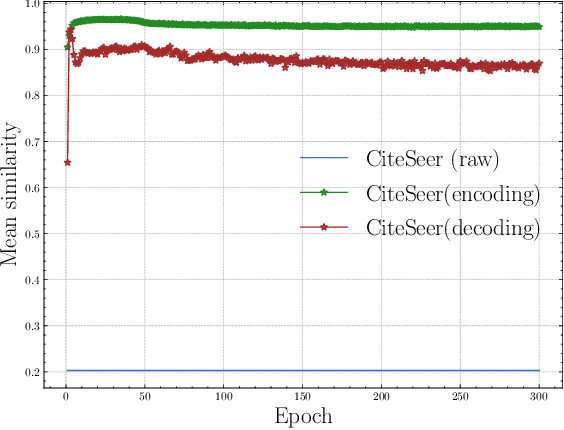
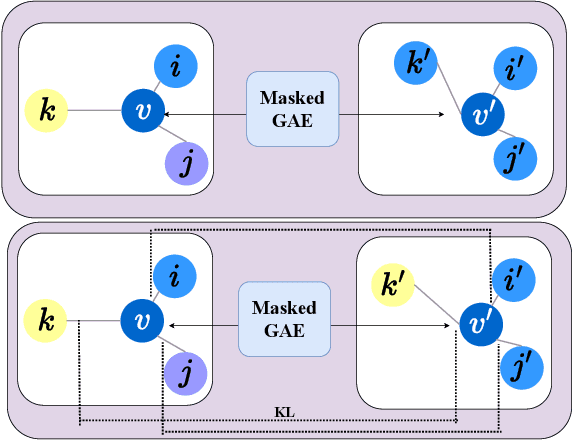

Graph autoencoders (GAEs), as a kind of generative self-supervised learning approach, have shown great potential in recent years. GAEs typically rely on distance-based criteria, such as mean-square-error (MSE), to reconstruct the input graph. However, relying solely on a single reconstruction criterion may lead to a loss of distinctiveness in the reconstructed graph, causing nodes to collapse into similar representations and resulting in sub-optimal performance. To address this issue, we have developed a simple yet effective strategy to preserve the necessary distinctness in the reconstructed graph. Inspired by the knowledge distillation technique, we found that the dual encoder-decoder architecture of GAEs can be viewed as a teacher-student relationship. Therefore, we propose transferring the knowledge of distinctness from the raw graph to the reconstructed graph, achieved through a simple KL constraint. Specifically, we compute pairwise node similarity scores in the raw graph and reconstructed graph. During the training process, the KL constraint is optimized alongside the reconstruction criterion. We conducted extensive experiments across three types of graph tasks, demonstrating the effectiveness and generality of our strategy. This indicates that the proposed approach can be employed as a plug-and-play method to avoid vague reconstructions and enhance overall performance.
Towards Comprehensive Preference Data Collection for Reward Modeling
Jun 24, 2024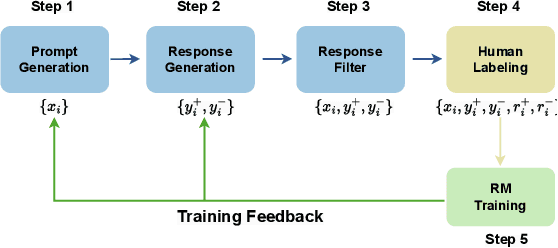

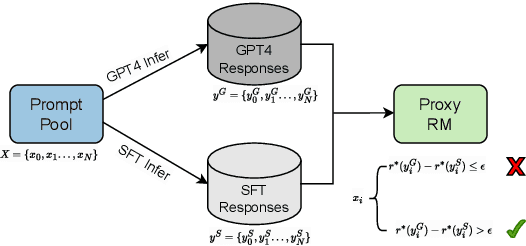
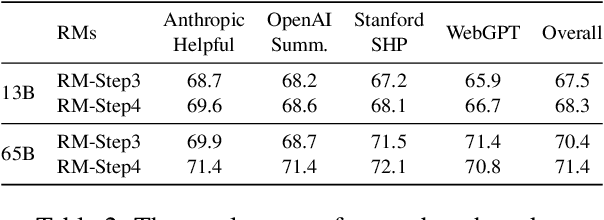
Reinforcement Learning from Human Feedback (RLHF) facilitates the alignment of large language models (LLMs) with human preferences, thereby enhancing the quality of responses generated. A critical component of RLHF is the reward model, which is trained on preference data and outputs a scalar reward during the inference stage. However, the collection of preference data still lacks thorough investigation. Recent studies indicate that preference data is collected either by AI or humans, where chosen and rejected instances are identified among pairwise responses. We question whether this process effectively filters out noise and ensures sufficient diversity in collected data. To address these concerns, for the first time, we propose a comprehensive framework for preference data collection, decomposing the process into four incremental steps: Prompt Generation, Response Generation, Response Filtering, and Human Labeling. This structured approach ensures the collection of high-quality preferences while reducing reliance on human labor. We conducted comprehensive experiments based on the data collected at different stages, demonstrating the effectiveness of the proposed data collection method.
QLSC: A Query Latent Semantic Calibrator for Robust Extractive Question Answering
Apr 30, 2024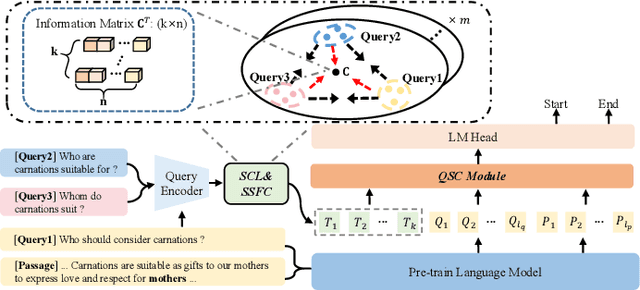
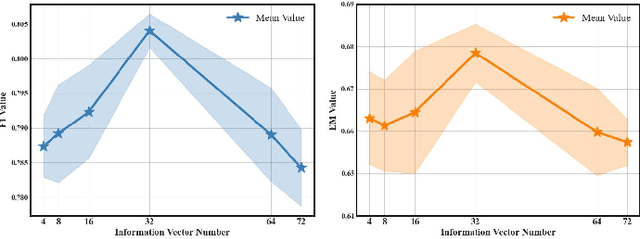
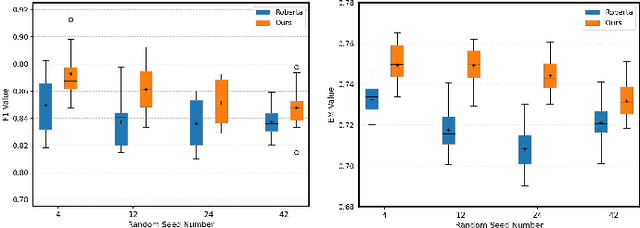
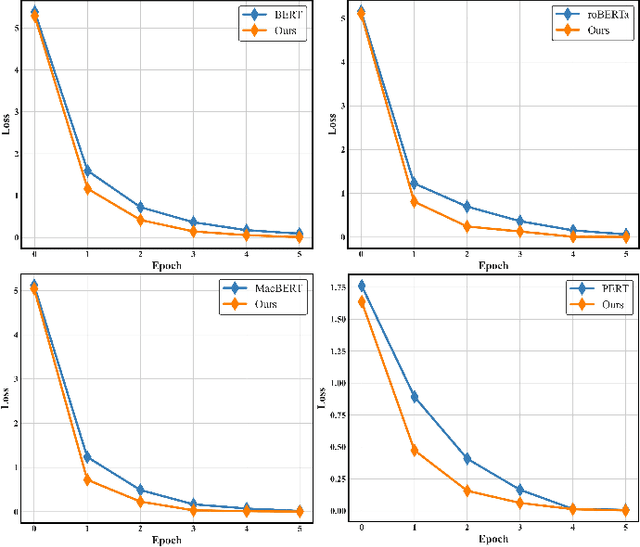
Extractive Question Answering (EQA) in Machine Reading Comprehension (MRC) often faces the challenge of dealing with semantically identical but format-variant inputs. Our work introduces a novel approach, called the ``Query Latent Semantic Calibrator (QLSC)'', designed as an auxiliary module for existing MRC models. We propose a unique scaling strategy to capture latent semantic center features of queries. These features are then seamlessly integrated into traditional query and passage embeddings using an attention mechanism. By deepening the comprehension of the semantic queries-passage relationship, our approach diminishes sensitivity to variations in text format and boosts the model's capability in pinpointing accurate answers. Experimental results on robust Question-Answer datasets confirm that our approach effectively handles format-variant but semantically identical queries, highlighting the effectiveness and adaptability of our proposed method.
Exploring Task Unification in Graph Representation Learning via Generative Approach
Mar 21, 2024



Graphs are ubiquitous in real-world scenarios and encompass a diverse range of tasks, from node-, edge-, and graph-level tasks to transfer learning. However, designing specific tasks for each type of graph data is often costly and lacks generalizability. Recent endeavors under the "Pre-training + Fine-tuning" or "Pre-training + Prompt" paradigms aim to design a unified framework capable of generalizing across multiple graph tasks. Among these, graph autoencoders (GAEs), generative self-supervised models, have demonstrated their potential in effectively addressing various graph tasks. Nevertheless, these methods typically employ multi-stage training and require adaptive designs, which on one hand make it difficult to be seamlessly applied to diverse graph tasks and on the other hand overlook the negative impact caused by discrepancies in task objectives between the different stages. To address these challenges, we propose GA^2E, a unified adversarially masked autoencoder capable of addressing the above challenges seamlessly. Specifically, GA^2E proposes to use the subgraph as the meta-structure, which remains consistent across all graph tasks (ranging from node-, edge-, and graph-level to transfer learning) and all stages (both during training and inference). Further, GA^2E operates in a \textbf{"Generate then Discriminate"} manner. It leverages the masked GAE to reconstruct the input subgraph whilst treating it as a generator to compel the reconstructed graphs resemble the input subgraph. Furthermore, GA^2E introduces an auxiliary discriminator to discern the authenticity between the reconstructed (generated) subgraph and the input subgraph, thus ensuring the robustness of the graph representation through adversarial training mechanisms. We validate GA^2E's capabilities through extensive experiments on 21 datasets across four types of graph tasks.
VIGraph: Self-supervised Learning for Class-Imbalanced Node Classification
Nov 02, 2023



Class imbalance in graph data poses significant challenges for node classification. Existing methods, represented by SMOTE-based approaches, partially alleviate this issue but still exhibit limitations during imbalanced scenario construction. Self-supervised learning (SSL) offers a promising solution by synthesizing minority nodes from the data itself, yet its potential remains unexplored. In this paper, we analyze the limitations of SMOTE-based approaches and introduce VIGraph, a novel SSL model based on the self-supervised Variational Graph Auto-Encoder (VGAE) that leverages Variational Inference (VI) to generate minority nodes. Specifically, VIGraph strictly adheres to the concept of imbalance when constructing imbalanced graphs and utilizes the generative VGAE to generate minority nodes. Moreover, VIGraph introduces a novel Siamese contrastive strategy at the decoding phase to improve the overall quality of generated nodes. VIGraph can generate high-quality nodes without reintegrating them into the original graph, eliminating the "Generating, Reintegrating, and Retraining" process found in SMOTE-based methods. Experiments on multiple real-world datasets demonstrate that VIGraph achieves promising results for class-imbalanced node classification tasks.