 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Noise and Stochasticity in Fraud Detection for Service Networks
May 02, 2025Fraud detection is crucial in social service networks to maintain user trust and improve service network security. Existing spectral graph-based methods address this challenge by leveraging different graph filters to capture signals with different frequencies in service networks. However, most graph filter-based methods struggle with deriving clean and discriminative graph signals. On the one hand, they overlook the noise in the information propagation process, resulting in degradation of filtering ability. On the other hand, they fail to discriminate the frequency-specific characteristics of graph signals, leading to distortion of signals fusion. To address these issues, we develop a novel spectral graph network based on information bottleneck theory (SGNN-IB) for fraud detection in service networks. SGNN-IB splits the original graph into homophilic and heterophilic subgraphs to better capture the signals at different frequencies. For the first limitation, SGNN-IB applies information bottleneck theory to extract key characteristics of encoded representations. For the second limitation, SGNN-IB introduces prototype learning to implement signal fusion, preserving the frequency-specific characteristics of signals. Extensive experiments on three real-world datasets demonstrate that SGNN-IB outperforms state-of-the-art fraud detection methods.
FreCT: Frequency-augmented Convolutional Transformer for Robust Time Series Anomaly Detection
May 02, 2025Time series anomaly detection is critical for system monitoring and risk identification, across various domains, such as finance and healthcare. However, for most reconstruction-based approaches, detecting anomalies remains a challenge due to the complexity of sequential patterns in time series data. On the one hand, reconstruction-based techniques are susceptible to computational deviation stemming from anomalies, which can lead to impure representations of normal sequence patterns. On the other hand, they often focus on the time-domain dependencies of time series, while ignoring the alignment of frequency information beyond the time domain. To address these challenges, we propose a novel Frequency-augmented Convolutional Transformer (FreCT). FreCT utilizes patch operations to generate contrastive views and employs an improved Transformer architecture integrated with a convolution module to capture long-term dependencies while preserving local topology information. The introduced frequency analysis based on Fourier transformation could enhance the model's ability to capture crucial characteristics beyond the time domain. To protect the training quality from anomalies and improve the robustness, FreCT deploys stop-gradient Kullback-Leibler (KL) divergence and absolute error to optimize consistency information in both time and frequency domains. Extensive experiments on four public datasets demonstrate that FreCT outperforms existing methods in identifying anomalies.
Dual-channel Heterophilic Message Passing for Graph Fraud Detection
Apr 19, 2025Fraudulent activities have significantly increased across various domains, such as e-commerce, online review platforms, and social networks, making fraud detection a critical task. Spatial Graph Neural Networks (GNNs) have been successfully applied to fraud detection tasks due to their strong inductive learning capabilities. However, existing spatial GNN-based methods often enhance the graph structure by excluding heterophilic neighbors during message passing to align with the homophilic bias of GNNs. Unfortunately, this approach can disrupt the original graph topology and increase uncertainty in predictions. To address these limitations, this paper proposes a novel framework, Dual-channel Heterophilic Message Passing (DHMP), for fraud detection. DHMP leverages a heterophily separation module to divide the graph into homophilic and heterophilic subgraphs, mitigating the low-pass inductive bias of traditional GNNs. It then applies shared weights to capture signals at different frequencies independently and incorporates a customized sampling strategy for training. This allows nodes to adaptively balance the contributions of various signals based on their labels. Extensive experiments on three real-world datasets demonstrate that DHMP outperforms existing methods, highlighting the importance of separating signals with different frequencies for improved fraud detection. The code is available at https://github.com/shaieesss/DHMP.
DConAD: A Differencing-based Contrastive Representation Learning Framework for Time Series Anomaly Detection
Apr 19, 2025Time series anomaly detection holds notable importance for risk identification and fault detection across diverse application domains. Unsupervised learning methods have become popular because they have no requirement for labels. However, due to the challenges posed by the multiplicity of abnormal patterns, the sparsity of anomalies, and the growth of data scale and complexity, these methods often fail to capture robust and representative dependencies within the time series for identifying anomalies. To enhance the ability of models to capture normal patterns of time series and avoid the retrogression of modeling ability triggered by the dependencies on high-quality prior knowledge, we propose a differencing-based contrastive representation learning framework for time series anomaly detection (DConAD). Specifically, DConAD generates differential data to provide additional information about time series and utilizes transformer-based architecture to capture spatiotemporal dependencies, which enhances the robustness of unbiased representation learning ability. Furthermore, DConAD implements a novel KL divergence-based contrastive learning paradigm that only uses positive samples to avoid deviation from reconstruction and deploys the stop-gradient strategy to compel convergence. Extensive experiments on five public datasets show the superiority and effectiveness of DConAD compared with nine baselines. The code is available at https://github.com/shaieesss/DConAD.
Decomposition-based multi-scale transformer framework for time series anomaly detection
Apr 19, 2025Time series anomaly detection is crucial for maintaining stable systems. Existing methods face two main challenges. First, it is difficult to directly model the dependencies of diverse and complex patterns within the sequences. Second, many methods that optimize parameters using mean squared error struggle with noise in the time series, leading to performance deterioration. To address these challenges, we propose a transformer-based framework built on decomposition (TransDe) for multivariate time series anomaly detection. The key idea is to combine the strengths of time series decomposition and transformers to effectively learn the complex patterns in normal time series data. A multi-scale patch-based transformer architecture is proposed to exploit the representative dependencies of each decomposed component of the time series. Furthermore, a contrastive learn paradigm based on patch operation is proposed, which leverages KL divergence to align the positive pairs, namely the pure representations of normal patterns between different patch-level views. A novel asynchronous loss function with a stop-gradient strategy is further introduced to enhance the performance of TransDe effectively. It can avoid time-consuming and labor-intensive computation costs in the optimization process. Extensive experiments on five public datasets are conducted and TransDe shows superiority compared with twelve baselines in terms of F1 score. Our code is available at https://github.com/shaieesss/TransDe.
AlphaForge: A Framework to Mine and Dynamically Combine Formulaic Alpha Factors
Jun 26, 2024



The variability and low signal-to-noise ratio in financial data, combined with the necessity for interpretability, make the alpha factor mining workflow a crucial component of quantitative investment. Transitioning from early manual extraction to genetic programming, the most advanced approach in this domain currently employs reinforcement learning to mine a set of combination factors with fixed weights. However, the performance of resultant alpha factors exhibits inconsistency, and the inflexibility of fixed factor weights proves insufficient in adapting to the dynamic nature of financial markets. To address this issue, this paper proposes a two-stage formulaic alpha generating framework AlphaForge, for alpha factor mining and factor combination. This framework employs a generative-predictive neural network to generate factors, leveraging the robust spatial exploration capabilities inherent in deep learning while concurrently preserving diversity. The combination model within the framework incorporates the temporal performance of factors for selection and dynamically adjusts the weights assigned to each component alpha factor. Experiments conducted on real-world datasets demonstrate that our proposed model outperforms contemporary benchmarks in formulaic alpha factor mining. Furthermore, our model exhibits a notable enhancement in portfolio returns within the realm of quantitative investment.
Preserving Node Distinctness in Graph Autoencoders via Similarity Distillation
Jun 25, 2024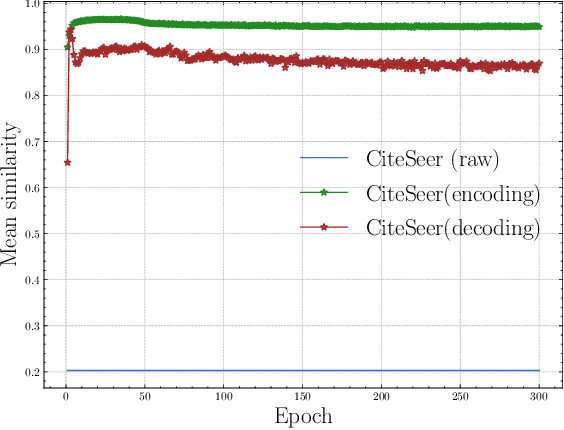
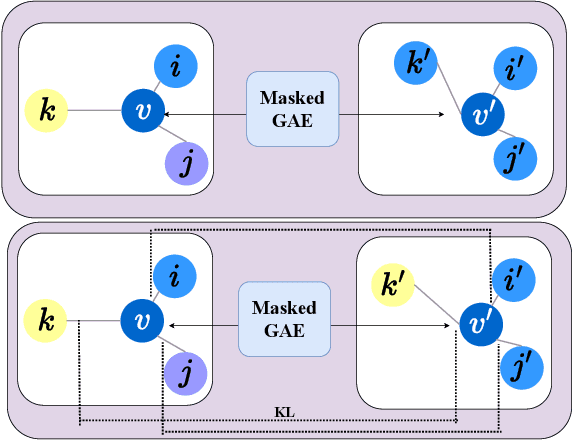

Graph autoencoders (GAEs), as a kind of generative self-supervised learning approach, have shown great potential in recent years. GAEs typically rely on distance-based criteria, such as mean-square-error (MSE), to reconstruct the input graph. However, relying solely on a single reconstruction criterion may lead to a loss of distinctiveness in the reconstructed graph, causing nodes to collapse into similar representations and resulting in sub-optimal performance. To address this issue, we have developed a simple yet effective strategy to preserve the necessary distinctness in the reconstructed graph. Inspired by the knowledge distillation technique, we found that the dual encoder-decoder architecture of GAEs can be viewed as a teacher-student relationship. Therefore, we propose transferring the knowledge of distinctness from the raw graph to the reconstructed graph, achieved through a simple KL constraint. Specifically, we compute pairwise node similarity scores in the raw graph and reconstructed graph. During the training process, the KL constraint is optimized alongside the reconstruction criterion. We conducted extensive experiments across three types of graph tasks, demonstrating the effectiveness and generality of our strategy. This indicates that the proposed approach can be employed as a plug-and-play method to avoid vague reconstructions and enhance overall performance.