 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExoGS: A 4D Real-to-Sim-to-Real Framework for Scalable Manipulation Data Collection
Jan 26, 2026Real-to-Sim-to-Real technique is gaining increasing interest for robotic manipulation, as it can generate scalable data in simulation while having narrower sim-to-real gap. However, previous methods mainly focused on environment-level visual real-to-sim transfer, ignoring the transfer of interactions, which could be challenging and inefficient to obtain purely in simulation especially for contact-rich tasks. We propose ExoGS, a robot-free 4D Real-to-Sim-to-Real framework that captures both static environments and dynamic interactions in the real world and transfers them seamlessly to a simulated environment. It provides a new solution for scalable manipulation data collection and policy learning. ExoGS employs a self-designed robot-isomorphic passive exoskeleton AirExo-3 to capture kinematically consistent trajectories with millimeter-level accuracy and synchronized RGB observations during direct human demonstrations. The robot, objects, and environment are reconstructed as editable 3D Gaussian Splatting assets, enabling geometry-consistent replay and large-scale data augmentation. Additionally, a lightweight Mask Adapter injects instance-level semantics into the policy to enhance robustness under visual domain shifts. Real-world experiments demonstrate that ExoGS significantly improves data efficiency and policy generalization compared to teleoperation-based baselines. Code and hardware files have been released on https://github.com/zaixiabalala/ExoGS.
Forging Spatial Intelligence: A Roadmap of Multi-Modal Data Pre-Training for Autonomous Systems
Dec 30, 2025The rapid advancement of autonomous systems, including self-driving vehicles and drones, has intensified the need to forge true Spatial Intelligence from multi-modal onboard sensor data. While foundation models excel in single-modal contexts, integrating their capabilities across diverse sensors like cameras and LiDAR to create a unified understanding remains a formidable challenge. This paper presents a comprehensive framework for multi-modal pre-training, identifying the core set of techniques driving progress toward this goal. We dissect the interplay between foundational sensor characteristics and learning strategies, evaluating the role of platform-specific datasets in enabling these advancements. Our central contribution is the formulation of a unified taxonomy for pre-training paradigms: ranging from single-modality baselines to sophisticated unified frameworks that learn holistic representations for advanced tasks like 3D object detection and semantic occupancy prediction. Furthermore, we investigate the integration of textual inputs and occupancy representations to facilitate open-world perception and planning. Finally, we identify critical bottlenecks, such as computational efficiency and model scalability, and propose a roadmap toward general-purpose multi-modal foundation models capable of achieving robust Spatial Intelligence for real-world deployment.
SpatialActor: Exploring Disentangled Spatial Representations for Robust Robotic Manipulation
Nov 12, 2025Robotic manipulation requires precise spatial understanding to interact with objects in the real world. Point-based methods suffer from sparse sampling, leading to the loss of fine-grained semantics. Image-based methods typically feed RGB and depth into 2D backbones pre-trained on 3D auxiliary tasks, but their entangled semantics and geometry are sensitive to inherent depth noise in real-world that disrupts semantic understanding. Moreover, these methods focus on high-level geometry while overlooking low-level spatial cues essential for precise interaction. We propose SpatialActor, a disentangled framework for robust robotic manipulation that explicitly decouples semantics and geometry. The Semantic-guided Geometric Module adaptively fuses two complementary geometry from noisy depth and semantic-guided expert priors. Also, a Spatial Transformer leverages low-level spatial cues for accurate 2D-3D mapping and enables interaction among spatial features. We evaluate SpatialActor on multiple simulation and real-world scenarios across 50+ tasks. It achieves state-of-the-art performance with 87.4% on RLBench and improves by 13.9% to 19.4% under varying noisy conditions, showing strong robustness. Moreover, it significantly enhances few-shot generalization to new tasks and maintains robustness under various spatial perturbations. Project Page: https://shihao1895.github.io/SpatialActor
OneOcc: Semantic Occupancy Prediction for Legged Robots with a Single Panoramic Camera
Nov 05, 2025Robust 3D semantic occupancy is crucial for legged/humanoid robots, yet most semantic scene completion (SSC) systems target wheeled platforms with forward-facing sensors. We present OneOcc, a vision-only panoramic SSC framework designed for gait-introduced body jitter and 360{\deg} continuity. OneOcc combines: (i) Dual-Projection fusion (DP-ER) to exploit the annular panorama and its equirectangular unfolding, preserving 360{\deg} continuity and grid alignment; (ii) Bi-Grid Voxelization (BGV) to reason in Cartesian and cylindrical-polar spaces, reducing discretization bias and sharpening free/occupied boundaries; (iii) a lightweight decoder with Hierarchical AMoE-3D for dynamic multi-scale fusion and better long-range/occlusion reasoning; and (iv) plug-and-play Gait Displacement Compensation (GDC) learning feature-level motion correction without extra sensors. We also release two panoramic occupancy benchmarks: QuadOcc (real quadruped, first-person 360{\deg}) and Human360Occ (H3O) (CARLA human-ego 360{\deg} with RGB, Depth, semantic occupancy; standardized within-/cross-city splits). OneOcc sets new state-of-the-art (SOTA): on QuadOcc it beats strong vision baselines and popular LiDAR ones; on H3O it gains +3.83 mIoU (within-city) and +8.08 (cross-city). Modules are lightweight, enabling deployable full-surround perception for legged/humanoid robots. Datasets and code will be publicly available at https://github.com/MasterHow/OneOcc.
Improving Monte Carlo Tree Search for Symbolic Regression
Sep 19, 2025Symbolic regression aims to discover concise, interpretable mathematical expressions that satisfy desired objectives, such as fitting data, posing a highly combinatorial optimization problem. While genetic programming has been the dominant approach, recent efforts have explored reinforcement learning methods for improving search efficiency. Monte Carlo Tree Search (MCTS), with its ability to balance exploration and exploitation through guided search, has emerged as a promising technique for symbolic expression discovery. However, its traditional bandit strategies and sequential symbol construction often limit performance. In this work, we propose an improved MCTS framework for symbolic regression that addresses these limitations through two key innovations: (1) an extreme bandit allocation strategy tailored for identifying globally optimal expressions, with finite-time performance guarantees under polynomial reward decay assumptions; and (2) evolution-inspired state-jumping actions such as mutation and crossover, which enable non-local transitions to promising regions of the search space. These state-jumping actions also reshape the reward landscape during the search process, improving both robustness and efficiency. We conduct a thorough numerical study to the impact of these improvements and benchmark our approach against existing symbolic regression methods on a variety of datasets, including both ground-truth and black-box datasets. Our approach achieves competitive performance with state-of-the-art libraries in terms of recovery rate, attains favorable positions on the Pareto frontier of accuracy versus model complexity. Code is available at https://github.com/PKU-CMEGroup/MCTS-4-SR.
MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation
Aug 26, 2025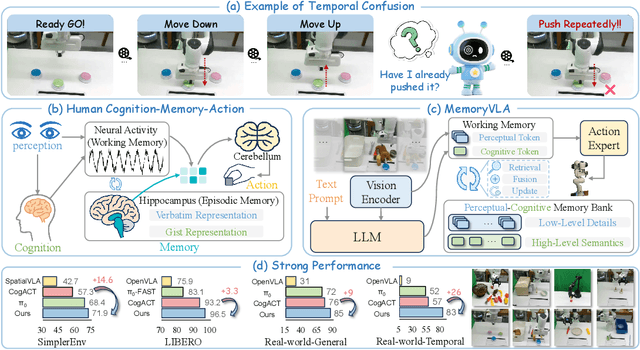
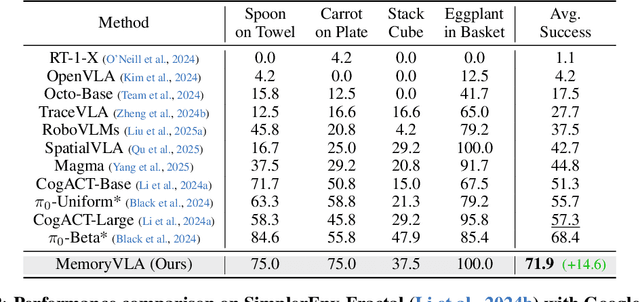
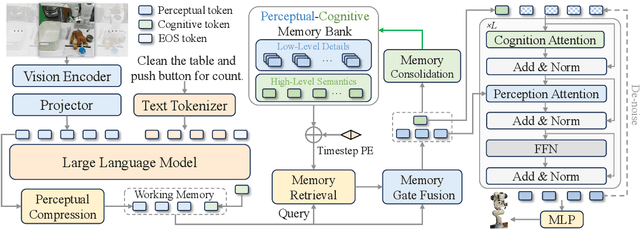
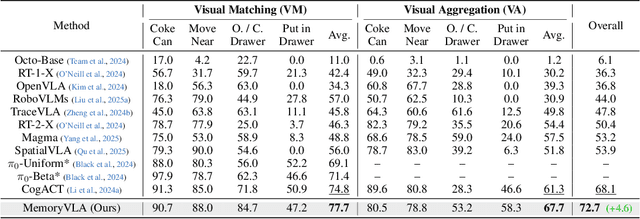
Temporal context is essential for robotic manipulation because such tasks are inherently non-Markovian, yet mainstream VLA models typically overlook it and struggle with long-horizon, temporally dependent tasks. Cognitive science suggests that humans rely on working memory to buffer short-lived representations for immediate control, while the hippocampal system preserves verbatim episodic details and semantic gist of past experience for long-term memory. Inspired by these mechanisms, we propose MemoryVLA, a Cognition-Memory-Action framework for long-horizon robotic manipulation. A pretrained VLM encodes the observation into perceptual and cognitive tokens that form working memory, while a Perceptual-Cognitive Memory Bank stores low-level details and high-level semantics consolidated from it. Working memory retrieves decision-relevant entries from the bank, adaptively fuses them with current tokens, and updates the bank by merging redundancies. Using these tokens, a memory-conditioned diffusion action expert yields temporally aware action sequences. We evaluate MemoryVLA on 150+ simulation and real-world tasks across three robots. On SimplerEnv-Bridge, Fractal, and LIBERO-5 suites, it achieves 71.9%, 72.7%, and 96.5% success rates, respectively, all outperforming state-of-the-art baselines CogACT and pi-0, with a notable +14.6 gain on Bridge. On 12 real-world tasks spanning general skills and long-horizon temporal dependencies, MemoryVLA achieves 84.0% success rate, with long-horizon tasks showing a +26 improvement over state-of-the-art baseline. Project Page: https://shihao1895.github.io/MemoryVLA
GeoVLA: Empowering 3D Representations in Vision-Language-Action Models
Aug 12, 2025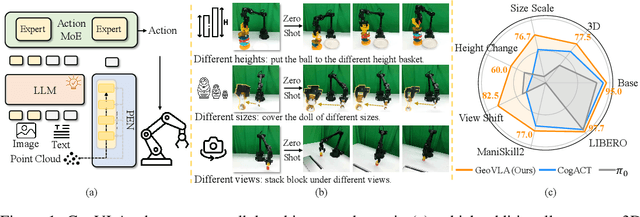
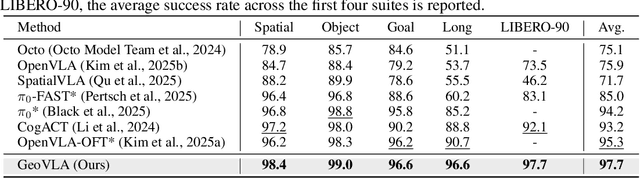
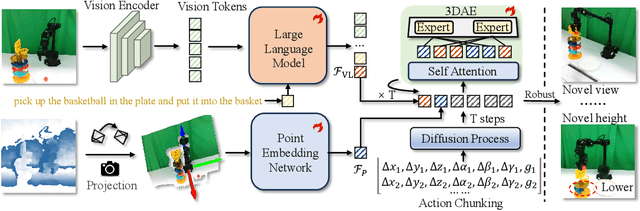
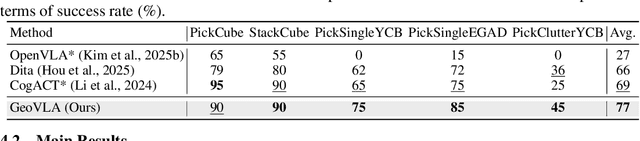
Vision-Language-Action (VLA) models have emerged as a promising approach for enabling robots to follow language instructions and predict corresponding actions.However, current VLA models mainly rely on 2D visual inputs, neglecting the rich geometric information in the 3D physical world, which limits their spatial awareness and adaptability. In this paper, we present GeoVLA, a novel VLA framework that effectively integrates 3D information to advance robotic manipulation. It uses a vision-language model (VLM) to process images and language instructions,extracting fused vision-language embeddings. In parallel, it converts depth maps into point clouds and employs a customized point encoder, called Point Embedding Network, to generate 3D geometric embeddings independently. These produced embeddings are then concatenated and processed by our proposed spatial-aware action expert, called 3D-enhanced Action Expert, which combines information from different sensor modalities to produce precise action sequences. Through extensive experiments in both simulation and real-world environments, GeoVLA demonstrates superior performance and robustness. It achieves state-of-the-art results in the LIBERO and ManiSkill2 simulation benchmarks and shows remarkable robustness in real-world tasks requiring height adaptability, scale awareness and viewpoint invariance.
NeuralDB: Scaling Knowledge Editing in LLMs to 100,000 Facts with Neural KV Database
Jul 24, 2025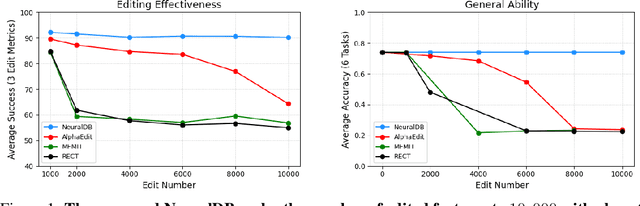
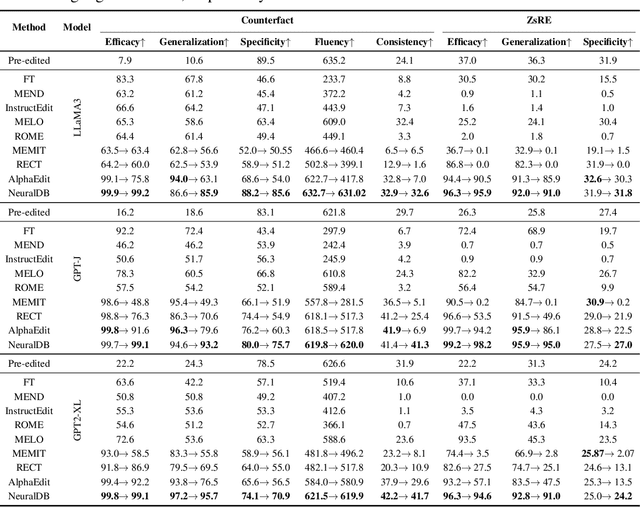
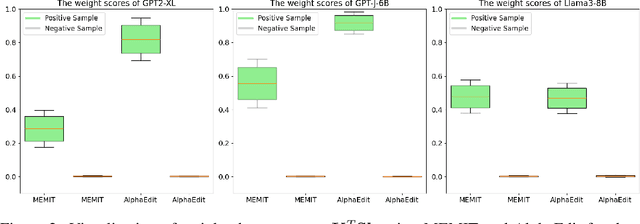

Efficiently editing knowledge stored in large language models (LLMs) enables model updates without large-scale training. One possible solution is Locate-and-Edit (L\&E), allowing simultaneous modifications of a massive number of facts. However, such editing may compromise the general abilities of LLMs and even result in forgetting edited facts when scaling up to thousands of edits. In this paper, we model existing linear L\&E methods as querying a Key-Value (KV) database. From this perspective, we then propose NeuralDB, an editing framework that explicitly represents the edited facts as a neural KV database equipped with a non-linear gated retrieval module, % In particular, our gated module only operates when inference involves the edited facts, effectively preserving the general abilities of LLMs. Comprehensive experiments involving the editing of 10,000 facts were conducted on the ZsRE and CounterFacts datasets, using GPT2-XL, GPT-J (6B) and Llama-3 (8B). The results demonstrate that NeuralDB not only excels in editing efficacy, generalization, specificity, fluency, and consistency, but also preserves overall performance across six representative text understanding and generation tasks. Further experiments indicate that NeuralDB maintains its effectiveness even when scaled to 100,000 facts (\textbf{50x} more than in prior work).
Grounding Beyond Detection: Enhancing Contextual Understanding in Embodied 3D Grounding
Jun 05, 2025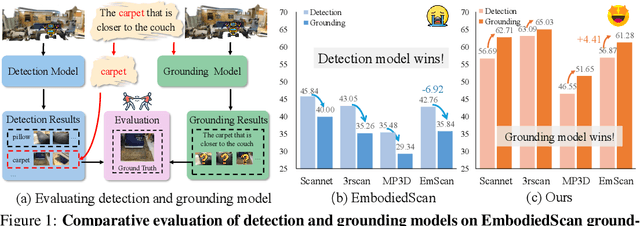
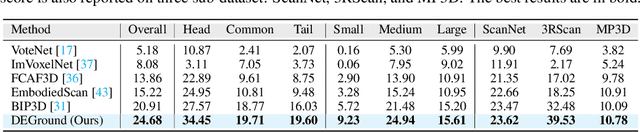
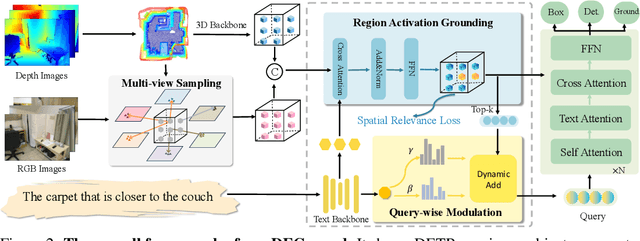
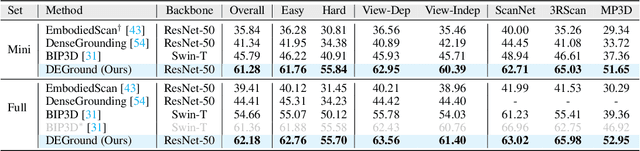
Embodied 3D grounding aims to localize target objects described in human instructions from ego-centric viewpoint. Most methods typically follow a two-stage paradigm where a trained 3D detector's optimized backbone parameters are used to initialize a grounding model. In this study, we explore a fundamental question: Does embodied 3D grounding benefit enough from detection? To answer this question, we assess the grounding performance of detection models using predicted boxes filtered by the target category. Surprisingly, these detection models without any instruction-specific training outperform the grounding models explicitly trained with language instructions. This indicates that even category-level embodied 3D grounding may not be well resolved, let alone more fine-grained context-aware grounding. Motivated by this finding, we propose DEGround, which shares DETR queries as object representation for both DEtection and Grounding and enables the grounding to benefit from basic category classification and box detection. Based on this framework, we further introduce a regional activation grounding module that highlights instruction-related regions and a query-wise modulation module that incorporates sentence-level semantic into the query representation, strengthening the context-aware understanding of language instructions. Remarkably, DEGround outperforms state-of-the-art model BIP3D by 7.52\% at overall accuracy on the EmbodiedScan validation set. The source code will be publicly available at https://github.com/zyn213/DEGround.
Hadaptive-Net: Efficient Vision Models via Adaptive Cross-Hadamard Synergy
May 28, 2025Recent studies have revealed the immense potential of Hadamard product in enhancing network representational capacity and dimensional compression. However, despite its theoretical promise, this technique has not been systematically explored or effectively applied in practice, leaving its full capabilities underdeveloped. In this work, we first analyze and identify the advantages of Hadamard product over standard convolutional operations in cross-channel interaction and channel expansion. Building upon these insights, we propose a computationally efficient module: Adaptive Cross-Hadamard (ACH), which leverages adaptive cross-channel Hadamard products for high-dimensional channel expansion. Furthermore, we introduce Hadaptive-Net (Hadamard Adaptive Network), a lightweight network backbone for visual tasks, which is demonstrated through experiments that it achieves an unprecedented balance between inference speed and accuracy through our proposed module.