 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Driven Dual Style Mixing for Single-Domain Generalized Object Detection
May 12, 2025Generalizing an object detector trained on a single domain to multiple unseen domains is a challenging task. Existing methods typically introduce image or feature augmentation to diversify the source domain to raise the robustness of the detector. Vision-Language Model (VLM)-based augmentation techniques have been proven to be effective, but they require that the detector's backbone has the same structure as the image encoder of VLM, limiting the detector framework selection. To address this problem, we propose Language-Driven Dual Style Mixing (LDDS) for single-domain generalization, which diversifies the source domain by fully utilizing the semantic information of the VLM. Specifically, we first construct prompts to transfer style semantics embedded in the VLM to an image translation network. This facilitates the generation of style diversified images with explicit semantic information. Then, we propose image-level style mixing between the diversified images and source domain images. This effectively mines the semantic information for image augmentation without relying on specific augmentation selections. Finally, we propose feature-level style mixing in a double-pipeline manner, allowing feature augmentation to be model-agnostic and can work seamlessly with the mainstream detector frameworks, including the one-stage, two-stage, and transformer-based detectors. Extensive experiments demonstrate the effectiveness of our approach across various benchmark datasets, including real to cartoon and normal to adverse weather tasks. The source code and pre-trained models will be publicly available at https://github.com/qinhongda8/LDDS.
Panoramic Out-of-Distribution Segmentation
May 06, 2025Panoramic imaging enables capturing 360{\deg} images with an ultra-wide Field-of-View (FoV) for dense omnidirectional perception. However, current panoramic semantic segmentation methods fail to identify outliers, and pinhole Out-of-distribution Segmentation (OoS) models perform unsatisfactorily in the panoramic domain due to background clutter and pixel distortions. To address these issues, we introduce a new task, Panoramic Out-of-distribution Segmentation (PanOoS), achieving OoS for panoramas. Furthermore, we propose the first solution, POS, which adapts to the characteristics of panoramic images through text-guided prompt distribution learning. Specifically, POS integrates a disentanglement strategy designed to materialize the cross-domain generalization capability of CLIP. The proposed Prompt-based Restoration Attention (PRA) optimizes semantic decoding by prompt guidance and self-adaptive correction, while Bilevel Prompt Distribution Learning (BPDL) refines the manifold of per-pixel mask embeddings via semantic prototype supervision. Besides, to compensate for the scarcity of PanOoS datasets, we establish two benchmarks: DenseOoS, which features diverse outliers in complex environments, and QuadOoS, captured by a quadruped robot with a panoramic annular lens system. Extensive experiments demonstrate superior performance of POS, with AuPRC improving by 34.25% and FPR95 decreasing by 21.42% on DenseOoS, outperforming state-of-the-art pinhole-OoS methods. Moreover, POS achieves leading closed-set segmentation capabilities. Code and datasets will be available at https://github.com/MengfeiD/PanOoS.
HierDAMap: Towards Universal Domain Adaptive BEV Mapping via Hierarchical Perspective Priors
Mar 10, 2025The exploration of Bird's-Eye View (BEV) mapping technology has driven significant innovation in visual perception technology for autonomous driving. BEV mapping models need to be applied to the unlabeled real world, making the study of unsupervised domain adaptation models an essential path. However, research on unsupervised domain adaptation for BEV mapping remains limited and cannot perfectly accommodate all BEV mapping tasks. To address this gap, this paper proposes HierDAMap, a universal and holistic BEV domain adaptation framework with hierarchical perspective priors. Unlike existing research that solely focuses on image-level learning using prior knowledge, this paper explores the guiding role of perspective prior knowledge across three distinct levels: global, sparse, and instance levels. With these priors, HierDA consists of three essential components, including Semantic-Guided Pseudo Supervision (SGPS), Dynamic-Aware Coherence Learning (DACL), and Cross-Domain Frustum Mixing (CDFM). SGPS constrains the cross-domain consistency of perspective feature distribution through pseudo labels generated by vision foundation models in 2D space. To mitigate feature distribution discrepancies caused by spatial variations, DACL employs uncertainty-aware predicted depth as an intermediary to derive dynamic BEV labels from perspective pseudo-labels, thereby constraining the coarse BEV features derived from corresponding perspective features. CDFM, on the other hand, leverages perspective masks of view frustum to mix multi-view perspective images from both domains, which guides cross-domain view transformation and encoding learning through mixed BEV labels. The proposed method is verified on multiple BEV mapping tasks, such as BEV semantic segmentation, high-definition semantic, and vectorized mapping. The source code will be made publicly available at https://github.com/lynn-yu/HierDAMap.
MemorySAM: Memorize Modalities and Semantics with Segment Anything Model 2 for Multi-modal Semantic Segmentation
Mar 09, 2025Research has focused on Multi-Modal Semantic Segmentation (MMSS), where pixel-wise predictions are derived from multiple visual modalities captured by diverse sensors. Recently, the large vision model, Segment Anything Model 2 (SAM2), has shown strong zero-shot segmentation performance on both images and videos. When extending SAM2 to MMSS, two issues arise: 1. How can SAM2 be adapted to multi-modal data? 2. How can SAM2 better understand semantics? Inspired by cross-frame correlation in videos, we propose to treat multi-modal data as a sequence of frames representing the same scene. Our key idea is to ''memorize'' the modality-agnostic information and 'memorize' the semantics related to the targeted scene. To achieve this, we apply SAM2's memory mechanisms across multi-modal data to capture modality-agnostic features. Meanwhile, to memorize the semantic knowledge, we propose a training-only Semantic Prototype Memory Module (SPMM) to store category-level prototypes across training for facilitating SAM2's transition from instance to semantic segmentation. A prototypical adaptation loss is imposed between global and local prototypes iteratively to align and refine SAM2's semantic understanding. Extensive experimental results demonstrate that our proposed MemorySAM outperforms SoTA methods by large margins on both synthetic and real-world benchmarks (65.38% on DELIVER, 52.88% on MCubeS). Source code will be made publicly available.
Occlusion-Aware Seamless Segmentation
Jul 02, 2024Panoramic images can broaden the Field of View (FoV), occlusion-aware prediction can deepen the understanding of the scene, and domain adaptation can transfer across viewing domains. In this work, we introduce a novel task, Occlusion-Aware Seamless Segmentation (OASS), which simultaneously tackles all these three challenges. For benchmarking OASS, we establish a new human-annotated dataset for Blending Panoramic Amodal Seamless Segmentation, i.e., BlendPASS. Besides, we propose the first solution UnmaskFormer, aiming at unmasking the narrow FoV, occlusions, and domain gaps all at once. Specifically, UnmaskFormer includes the crucial designs of Unmasking Attention (UA) and Amodal-oriented Mix (AoMix). Our method achieves state-of-the-art performance on the BlendPASS dataset, reaching a remarkable mAPQ of 26.58% and mIoU of 43.66%. On public panoramic semantic segmentation datasets, i.e., SynPASS and DensePASS, our method outperforms previous methods and obtains 45.34% and 48.08% in mIoU, respectively. The fresh BlendPASS dataset and our source code will be made publicly available at https://github.com/yihong-97/OASS.
Towards Source-free Domain Adaptive Semantic Segmentation via Importance-aware and Prototype-contrast Learning
Jun 02, 2023Domain adaptive semantic segmentation enables robust pixel-wise understanding in real-world driving scenes. Source-free domain adaptation, as a more practical technique, addresses the concerns of data privacy and storage limitations in typical unsupervised domain adaptation methods. It utilizes a well-trained source model and unlabeled target data to achieve adaptation in the target domain. However, in the absence of source data and target labels, current solutions cannot sufficiently reduce the impact of domain shift and fully leverage the information from the target data. In this paper, we propose an end-to-end source-free domain adaptation semantic segmentation method via Importance-Aware and Prototype-Contrast (IAPC) learning. The proposed IAPC framework effectively extracts domain-invariant knowledge from the well-trained source model and learns domain-specific knowledge from the unlabeled target domain. Specifically, considering the problem of domain shift in the prediction of the target domain by the source model, we put forward an importance-aware mechanism for the biased target prediction probability distribution to extract domain-invariant knowledge from the source model. We further introduce a prototype-contrast strategy, which includes a prototype-symmetric cross-entropy loss and a prototype-enhanced cross-entropy loss, to learn target intra-domain knowledge without relying on labels. A comprehensive variety of experiments on two domain adaptive semantic segmentation benchmarks demonstrates that the proposed end-to-end IAPC solution outperforms existing state-of-the-art methods. Code will be made publicly available at https://github.com/yihong-97/Source-free_IAPC.
Video Shadow Detection via Spatio-Temporal Interpolation Consistency Training
Jun 17, 2022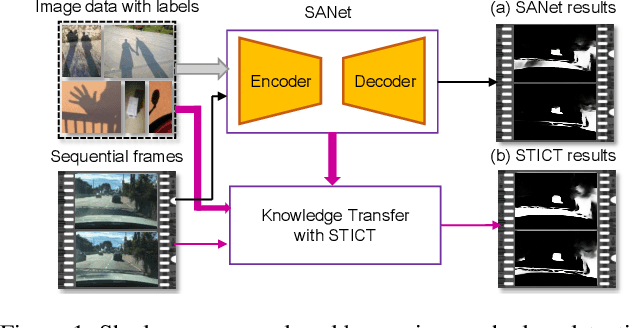

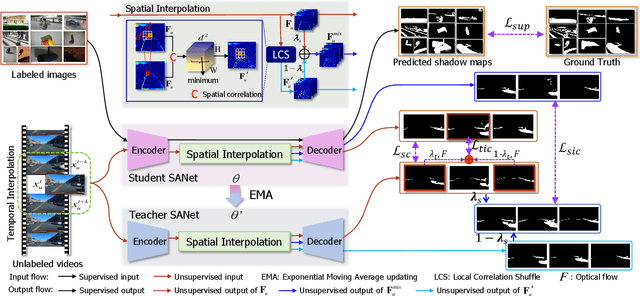
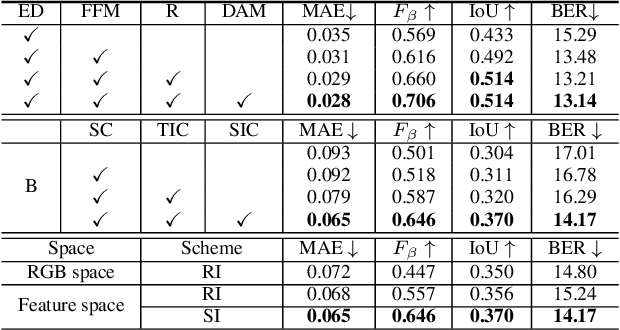
It is challenging to annotate large-scale datasets for supervised video shadow detection methods. Using a model trained on labeled images to the video frames directly may lead to high generalization error and temporal inconsistent results. In this paper, we address these challenges by proposing a Spatio-Temporal Interpolation Consistency Training (STICT) framework to rationally feed the unlabeled video frames together with the labeled images into an image shadow detection network training. Specifically, we propose the Spatial and Temporal ICT, in which we define two new interpolation schemes, \textit{i.e.}, the spatial interpolation and the temporal interpolation. We then derive the spatial and temporal interpolation consistency constraints accordingly for enhancing generalization in the pixel-wise classification task and for encouraging temporal consistent predictions, respectively. In addition, we design a Scale-Aware Network for multi-scale shadow knowledge learning in images, and propose a scale-consistency constraint to minimize the discrepancy among the predictions at different scales. Our proposed approach is extensively validated on the ViSha dataset and a self-annotated dataset. Experimental results show that, even without video labels, our approach is better than most state of the art supervised, semi-supervised or unsupervised image/video shadow detection methods and other methods in related tasks. Code and dataset are available at \url{https://github.com/yihong-97/STICT}.