 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Analysis of End-to-End LEO Satellite-Aided Shore-to-Ship Communications: A Stochastic Geometry Approach
Oct 23, 2025Low Earth orbit (LEO) satellite networks have shown strategic superiority in maritime communications, assisting in establishing signal transmissions from shore to ship through space-based links. Traditional performance modeling based on multiple circular orbits is challenging to characterize large-scale LEO satellite constellations, thus requiring a tractable approach to accurately evaluate the network performance. In this paper, we propose a theoretical framework for an LEO satellite-aided shore-to-ship communication network (LEO-SSCN), where LEO satellites are distributed as a binomial point process (BPP) on a specific spherical surface. The framework aims to obtain the end-to-end transmission performance by considering signal transmissions through either a marine link or a space link subject to Rician or Shadowed Rician fading, respectively. Due to the indeterminate position of the serving satellite, accurately modeling the distance from the serving satellite to the destination ship becomes intractable. To address this issue, we propose a distance approximation approach. Then, by approximation and incorporating a threshold-based communication scheme, we leverage stochastic geometry to derive analytical expressions of end-to-end transmission success probability and average transmission rate capacity. Extensive numerical results verify the accuracy of the analysis and demonstrate the effect of key parameters on the performance of LEO-SSCN.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025



We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Language-Driven Dual Style Mixing for Single-Domain Generalized Object Detection
May 12, 2025Generalizing an object detector trained on a single domain to multiple unseen domains is a challenging task. Existing methods typically introduce image or feature augmentation to diversify the source domain to raise the robustness of the detector. Vision-Language Model (VLM)-based augmentation techniques have been proven to be effective, but they require that the detector's backbone has the same structure as the image encoder of VLM, limiting the detector framework selection. To address this problem, we propose Language-Driven Dual Style Mixing (LDDS) for single-domain generalization, which diversifies the source domain by fully utilizing the semantic information of the VLM. Specifically, we first construct prompts to transfer style semantics embedded in the VLM to an image translation network. This facilitates the generation of style diversified images with explicit semantic information. Then, we propose image-level style mixing between the diversified images and source domain images. This effectively mines the semantic information for image augmentation without relying on specific augmentation selections. Finally, we propose feature-level style mixing in a double-pipeline manner, allowing feature augmentation to be model-agnostic and can work seamlessly with the mainstream detector frameworks, including the one-stage, two-stage, and transformer-based detectors. Extensive experiments demonstrate the effectiveness of our approach across various benchmark datasets, including real to cartoon and normal to adverse weather tasks. The source code and pre-trained models will be publicly available at https://github.com/qinhongda8/LDDS.
Towards Source-free Domain Adaptive Semantic Segmentation via Importance-aware and Prototype-contrast Learning
Jun 02, 2023Domain adaptive semantic segmentation enables robust pixel-wise understanding in real-world driving scenes. Source-free domain adaptation, as a more practical technique, addresses the concerns of data privacy and storage limitations in typical unsupervised domain adaptation methods. It utilizes a well-trained source model and unlabeled target data to achieve adaptation in the target domain. However, in the absence of source data and target labels, current solutions cannot sufficiently reduce the impact of domain shift and fully leverage the information from the target data. In this paper, we propose an end-to-end source-free domain adaptation semantic segmentation method via Importance-Aware and Prototype-Contrast (IAPC) learning. The proposed IAPC framework effectively extracts domain-invariant knowledge from the well-trained source model and learns domain-specific knowledge from the unlabeled target domain. Specifically, considering the problem of domain shift in the prediction of the target domain by the source model, we put forward an importance-aware mechanism for the biased target prediction probability distribution to extract domain-invariant knowledge from the source model. We further introduce a prototype-contrast strategy, which includes a prototype-symmetric cross-entropy loss and a prototype-enhanced cross-entropy loss, to learn target intra-domain knowledge without relying on labels. A comprehensive variety of experiments on two domain adaptive semantic segmentation benchmarks demonstrates that the proposed end-to-end IAPC solution outperforms existing state-of-the-art methods. Code will be made publicly available at https://github.com/yihong-97/Source-free_IAPC.
Achieving Covert Communication in Large-Scale SWIPT-Enabled D2D Networks
Feb 16, 2023We aim to secure a large-scale device-to-device (D2D) network against adversaries. The D2D network underlays a downlink cellular network to reuse the cellular spectrum and is enabled for simultaneous wireless information and power transfer (SWIPT). In the D2D network, the transmitters communicate with the receivers, and the receivers extract information and energy from their received radio-frequency (RF) signals. In the meantime, the adversaries aim to detect the D2D transmission. The D2D network applies power control and leverages the cellular signal to achieve covert communication (i.e., hide the presence of transmissions) so as to defend against the adversaries. We model the interaction between the D2D network and adversaries by using a two-stage Stackelberg game. Therein, the adversaries are the followers minimizing their detection errors at the lower stage and the D2D network is the leader maximizing its network utility constrained by the communication covertness and power outage at the upper stage. Both power splitting (PS)-based and time switch (TS)-based SWIPT schemes are explored. We characterize the spatial configuration of the large-scale D2D network, adversaries, and cellular network by stochastic geometry. We analyze the adversary's detection error minimization problem and adopt the Rosenbrock method to solve it, where the obtained solution is the best response from the lower stage. Taking into account the best response from the lower stage, we develop a bi-level algorithm to solve the D2D network's constrained network utility maximization problem and obtain the Stackelberg equilibrium. We present numerical results to reveal interesting insights.
Semantic Encoder Guided Generative Adversarial Face Ultra-Resolution Network
Nov 18, 2022



Face super-resolution is a domain-specific image super-resolution, which aims to generate High-Resolution (HR) face images from their Low-Resolution (LR) counterparts. In this paper, we propose a novel face super-resolution method, namely Semantic Encoder guided Generative Adversarial Face Ultra-Resolution Network (SEGA-FURN) to ultra-resolve an unaligned tiny LR face image to its HR counterpart with multiple ultra-upscaling factors (e.g., 4x and 8x). The proposed network is composed of a novel semantic encoder that has the ability to capture the embedded semantics to guide adversarial learning and a novel generator that uses a hierarchical architecture named Residual in Internal Dense Block (RIDB). Moreover, we propose a joint discriminator which discriminates both image data and embedded semantics. The joint discriminator learns the joint probability distribution of the image space and latent space. We also use a Relativistic average Least Squares loss (RaLS) as the adversarial loss to alleviate the gradient vanishing problem and enhance the stability of the training procedure. Extensive experiments on large face datasets have proved that the proposed method can achieve superior super-resolution results and significantly outperform other state-of-the-art methods in both qualitative and quantitative comparisons.
Securing Large-Scale D2D Networks Using Covert Communication and Friendly Jamming
Sep 30, 2022

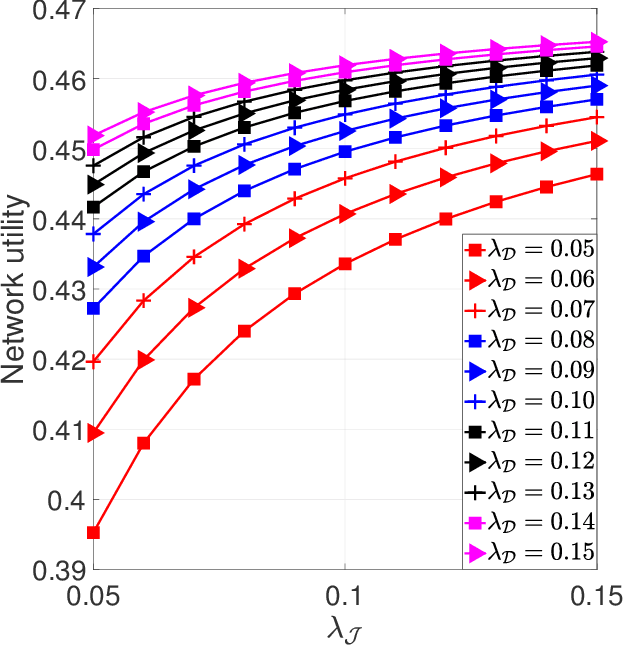
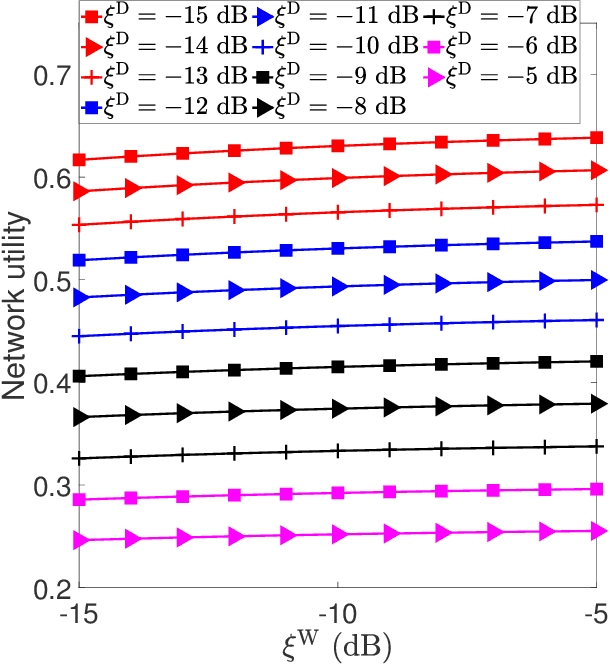
We exploit both covert communication and friendly jamming to propose a friendly jamming-assisted covert communication and use it to doubly secure a large-scale device-to-device (D2D) network against eavesdroppers (i.e., wardens). The D2D transmitters defend against the wardens by: 1) hiding their transmissions with enhanced covert communication, and 2) leveraging friendly jamming to ensure information secrecy even if the D2D transmissions are detected. We model the combat between the wardens and the D2D network (the transmitters and the friendly jammers) as a two-stage Stackelberg game. Therein, the wardens are the followers at the lower stage aiming to minimize their detection errors, and the D2D network is the leader at the upper stage aiming to maximize its utility (in terms of link reliability and communication security) subject to the constraint on communication covertness. We apply stochastic geometry to model the network spatial configuration so as to conduct a system-level study. We develop a bi-level optimization algorithm to search for the equilibrium of the proposed Stackelberg game based on the successive convex approximation (SCA) method and Rosenbrock method. Numerical results reveal interesting insights. We observe that without the assistance from the jammers, it is difficult to achieve covert communication on D2D transmission. Moreover, we illustrate the advantages of the proposed friendly jamming-assisted covert communication by comparing it with the information-theoretical secrecy approach in terms of the secure communication probability and network utility.
Video Shadow Detection via Spatio-Temporal Interpolation Consistency Training
Jun 17, 2022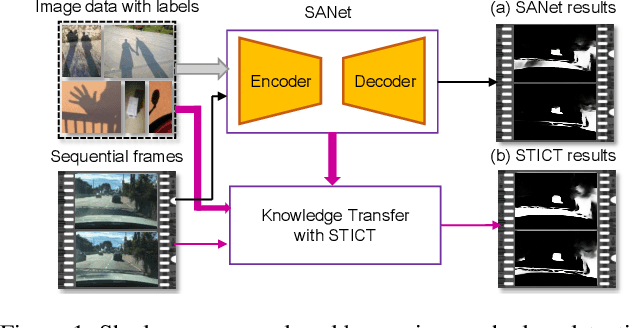

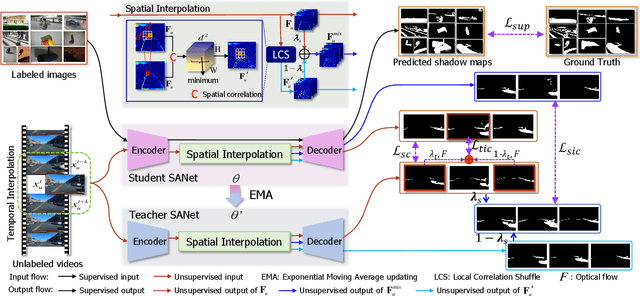
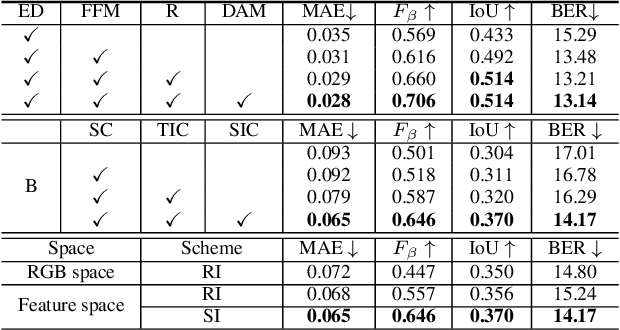
It is challenging to annotate large-scale datasets for supervised video shadow detection methods. Using a model trained on labeled images to the video frames directly may lead to high generalization error and temporal inconsistent results. In this paper, we address these challenges by proposing a Spatio-Temporal Interpolation Consistency Training (STICT) framework to rationally feed the unlabeled video frames together with the labeled images into an image shadow detection network training. Specifically, we propose the Spatial and Temporal ICT, in which we define two new interpolation schemes, \textit{i.e.}, the spatial interpolation and the temporal interpolation. We then derive the spatial and temporal interpolation consistency constraints accordingly for enhancing generalization in the pixel-wise classification task and for encouraging temporal consistent predictions, respectively. In addition, we design a Scale-Aware Network for multi-scale shadow knowledge learning in images, and propose a scale-consistency constraint to minimize the discrepancy among the predictions at different scales. Our proposed approach is extensively validated on the ViSha dataset and a self-annotated dataset. Experimental results show that, even without video labels, our approach is better than most state of the art supervised, semi-supervised or unsupervised image/video shadow detection methods and other methods in related tasks. Code and dataset are available at \url{https://github.com/yihong-97/STICT}.
Pseudo-supervised Deep Subspace Clustering
Apr 08, 2021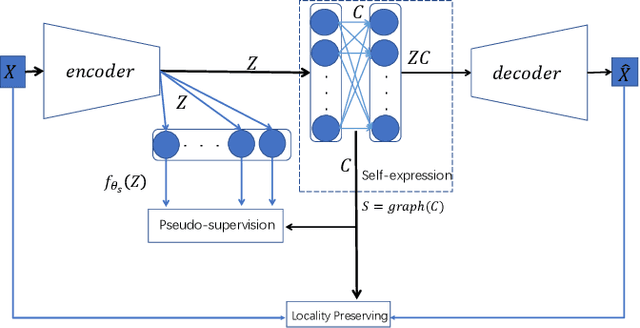
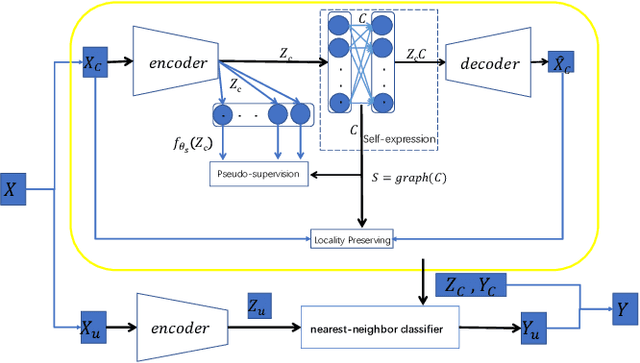
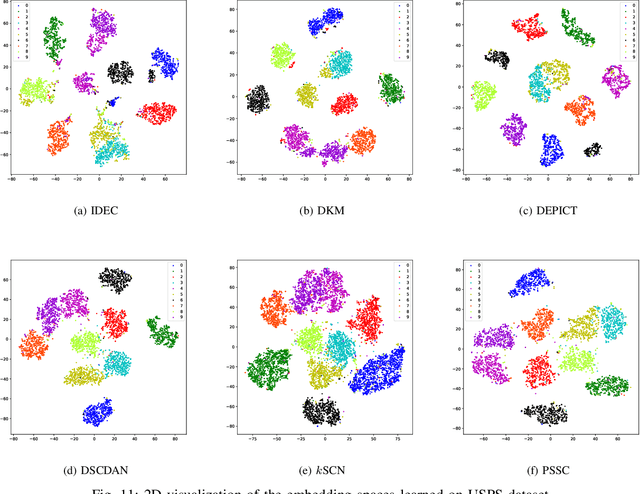
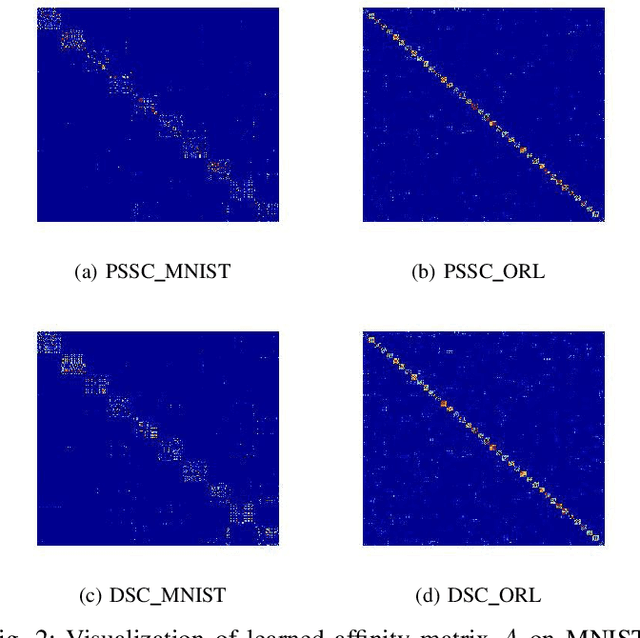
Auto-Encoder (AE)-based deep subspace clustering (DSC) methods have achieved impressive performance due to the powerful representation extracted using deep neural networks while prioritizing categorical separability. However, self-reconstruction loss of an AE ignores rich useful relation information and might lead to indiscriminative representation, which inevitably degrades the clustering performance. It is also challenging to learn high-level similarity without feeding semantic labels. Another unsolved problem facing DSC is the huge memory cost due to $n\times n$ similarity matrix, which is incurred by the self-expression layer between an encoder and decoder. To tackle these problems, we use pairwise similarity to weigh the reconstruction loss to capture local structure information, while a similarity is learned by the self-expression layer. Pseudo-graphs and pseudo-labels, which allow benefiting from uncertain knowledge acquired during network training, are further employed to supervise similarity learning. Joint learning and iterative training facilitate to obtain an overall optimal solution. Extensive experiments on benchmark datasets demonstrate the superiority of our approach. By combining with the $k$-nearest neighbors algorithm, we further show that our method can address the large-scale and out-of-sample problems.
Relation-Guided Representation Learning
Jul 11, 2020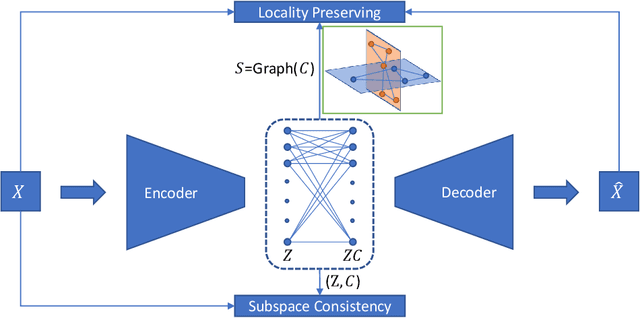



Deep auto-encoders (DAEs) have achieved great success in learning data representations via the powerful representability of neural networks. But most DAEs only focus on the most dominant structures which are able to reconstruct the data from a latent space and neglect rich latent structural information. In this work, we propose a new representation learning method that explicitly models and leverages sample relations, which in turn is used as supervision to guide the representation learning. Different from previous work, our framework well preserves the relations between samples. Since the prediction of pairwise relations themselves is a fundamental problem, our model adaptively learns them from data. This provides much flexibility to encode real data manifold. The important role of relation and representation learning is evaluated on the clustering task. Extensive experiments on benchmark data sets demonstrate the superiority of our approach. By seeking to embed samples into subspace, we further show that our method can address the large-scale and out-of-sample problem.