 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Active Learning via Natural Feature Progressive Framework
Oct 06, 2025


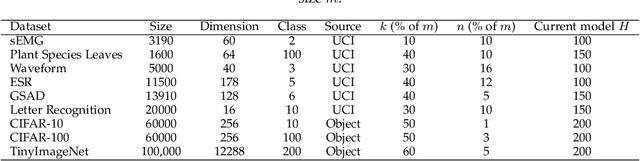
The effectiveness of modern deep learning models is predicated on the availability of large-scale, human-annotated datasets, a process that is notoriously expensive and time-consuming. While Active Learning (AL) offers a strategic solution by labeling only the most informative and representative data, its iterative nature still necessitates significant human involvement. Unsupervised Active Learning (UAL) presents an alternative by shifting the annotation burden to a single, post-selection step. Unfortunately, prevailing UAL methods struggle to achieve state-of-the-art performance. These approaches typically rely on local, gradient-based scoring for sample importance estimation, which not only makes them vulnerable to ambiguous and noisy data but also hinders their capacity to select samples that adequately represent the full data distribution. Moreover, their use of shallow, one-shot linear selection falls short of a true UAL paradigm. In this paper, we propose the Natural Feature Progressive Framework (NFPF), a UAL method that revolutionizes how sample importance is measured. At its core, NFPF employs a Specific Feature Learning Machine (SFLM) to effectively quantify each sample's contribution to model performance. We further utilize the SFLM to define a powerful Reconstruction Difference metric for initial sample selection. Our comprehensive experiments show that NFPF significantly outperforms all established UAL methods and achieves performance on par with supervised AL methods on vision datasets. Detailed ablation studies and qualitative visualizations provide compelling evidence for NFPF's superior performance, enhanced robustness, and improved data distribution coverage.
Real-World Image Super Resolution via Unsupervised Bi-directional Cycle Domain Transfer Learning based Generative Adversarial Network
Nov 19, 2022



Deep Convolutional Neural Networks (DCNNs) have exhibited impressive performance on image super-resolution tasks. However, these deep learning-based super-resolution methods perform poorly in real-world super-resolution tasks, where the paired high-resolution and low-resolution images are unavailable and the low-resolution images are degraded by complicated and unknown kernels. To break these limitations, we propose the Unsupervised Bi-directional Cycle Domain Transfer Learning-based Generative Adversarial Network (UBCDTL-GAN), which consists of an Unsupervised Bi-directional Cycle Domain Transfer Network (UBCDTN) and the Semantic Encoder guided Super Resolution Network (SESRN). First, the UBCDTN is able to produce an approximated real-like LR image through transferring the LR image from an artificially degraded domain to the real-world LR image domain. Second, the SESRN has the ability to super-resolve the approximated real-like LR image to a photo-realistic HR image. Extensive experiments on unpaired real-world image benchmark datasets demonstrate that the proposed method achieves superior performance compared to state-of-the-art methods.
Semantic Encoder Guided Generative Adversarial Face Ultra-Resolution Network
Nov 18, 2022



Face super-resolution is a domain-specific image super-resolution, which aims to generate High-Resolution (HR) face images from their Low-Resolution (LR) counterparts. In this paper, we propose a novel face super-resolution method, namely Semantic Encoder guided Generative Adversarial Face Ultra-Resolution Network (SEGA-FURN) to ultra-resolve an unaligned tiny LR face image to its HR counterpart with multiple ultra-upscaling factors (e.g., 4x and 8x). The proposed network is composed of a novel semantic encoder that has the ability to capture the embedded semantics to guide adversarial learning and a novel generator that uses a hierarchical architecture named Residual in Internal Dense Block (RIDB). Moreover, we propose a joint discriminator which discriminates both image data and embedded semantics. The joint discriminator learns the joint probability distribution of the image space and latent space. We also use a Relativistic average Least Squares loss (RaLS) as the adversarial loss to alleviate the gradient vanishing problem and enhance the stability of the training procedure. Extensive experiments on large face datasets have proved that the proposed method can achieve superior super-resolution results and significantly outperform other state-of-the-art methods in both qualitative and quantitative comparisons.
Video Shadow Detection via Spatio-Temporal Interpolation Consistency Training
Jun 17, 2022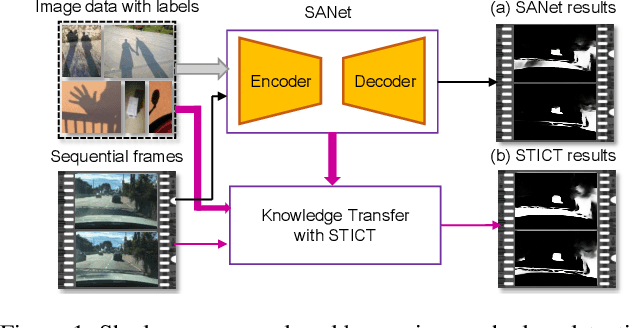

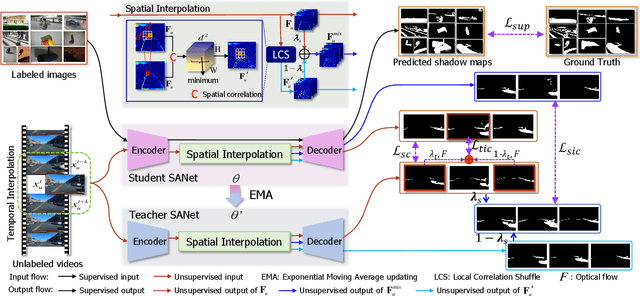
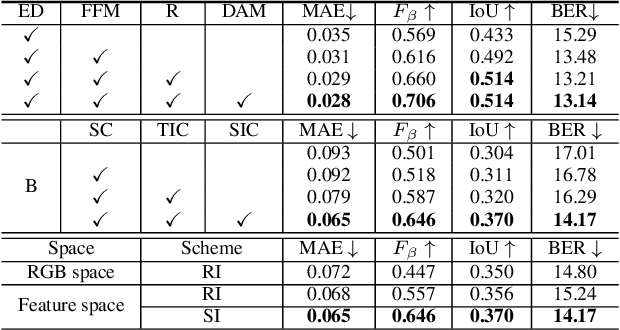
It is challenging to annotate large-scale datasets for supervised video shadow detection methods. Using a model trained on labeled images to the video frames directly may lead to high generalization error and temporal inconsistent results. In this paper, we address these challenges by proposing a Spatio-Temporal Interpolation Consistency Training (STICT) framework to rationally feed the unlabeled video frames together with the labeled images into an image shadow detection network training. Specifically, we propose the Spatial and Temporal ICT, in which we define two new interpolation schemes, \textit{i.e.}, the spatial interpolation and the temporal interpolation. We then derive the spatial and temporal interpolation consistency constraints accordingly for enhancing generalization in the pixel-wise classification task and for encouraging temporal consistent predictions, respectively. In addition, we design a Scale-Aware Network for multi-scale shadow knowledge learning in images, and propose a scale-consistency constraint to minimize the discrepancy among the predictions at different scales. Our proposed approach is extensively validated on the ViSha dataset and a self-annotated dataset. Experimental results show that, even without video labels, our approach is better than most state of the art supervised, semi-supervised or unsupervised image/video shadow detection methods and other methods in related tasks. Code and dataset are available at \url{https://github.com/yihong-97/STICT}.
AA-TransUNet: Attention Augmented TransUNet For Nowcasting Tasks
Feb 15, 2022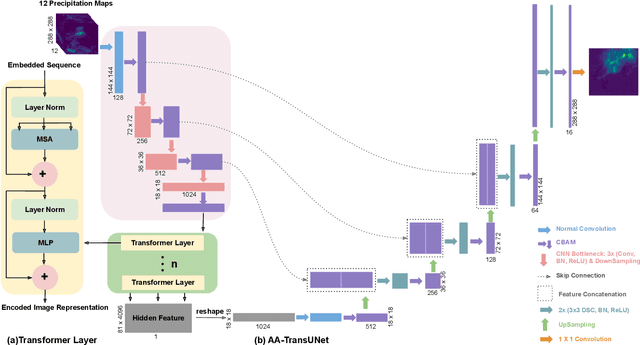
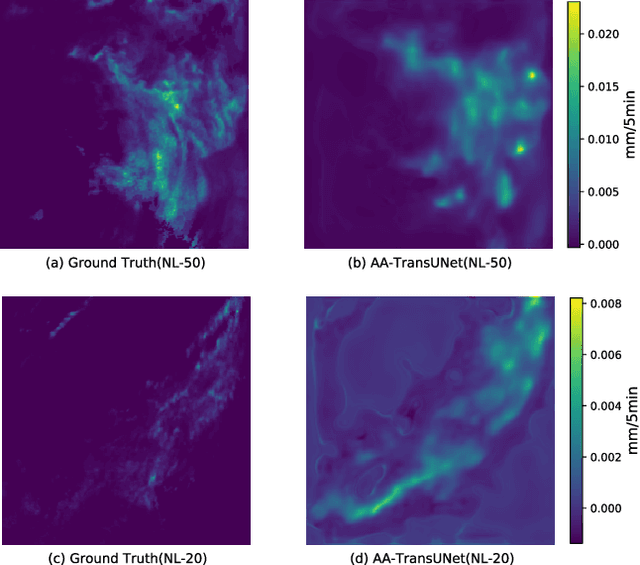
Data driven modeling based approaches have recently gained a lot of attention in many challenging meteorological applications including weather element forecasting. This paper introduces a novel data-driven predictive model based on TransUNet for precipitation nowcasting task. The TransUNet model which combines the Transformer and U-Net models has been previously successfully applied in medical segmentation tasks. Here, TransUNet is used as a core model and is further equipped with Convolutional Block Attention Modules (CBAM) and Depthwise-separable Convolution (DSC). The proposed Attention Augmented TransUNet (AA-TransUNet) model is evaluated on two distinct datasets: the Dutch precipitation map dataset and the French cloud cover dataset. The obtained results show that the proposed model outperforms other examined models on both tested datasets. Furthermore, the uncertainty analysis of the proposed AA-TransUNet is provided to give additional insights on its predictions.
Analytic Learning of Convolutional Neural Network For Pattern Recognition
Feb 14, 2022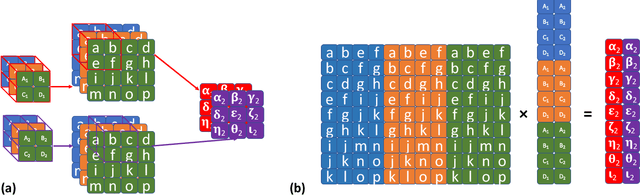



Training convolutional neural networks (CNNs) with back-propagation (BP) is time-consuming and resource-intensive particularly in view of the need to visit the dataset multiple times. In contrast, analytic learning attempts to obtain the weights in one epoch. However, existing attempts to analytic learning considered only the multilayer perceptron (MLP). In this article, we propose an analytic convolutional neural network learning (ACnnL). Theoretically we show that ACnnL builds a closed-form solution similar to its MLP counterpart, but differs in their regularization constraints. Consequently, we are able to answer to a certain extent why CNNs usually generalize better than MLPs from the implicit regularization point of view. The ACnnL is validated by conducting classification tasks on several benchmark datasets. It is encouraging that the ACnnL trains CNNs in a significantly fast manner with reasonably close prediction accuracies to those using BP. Moreover, our experiments disclose a unique advantage of ACnnL under the small-sample scenario when training data are scarce or expensive.
Projected Sliced Wasserstein Autoencoder-based Hyperspectral Images Anomaly Detection
Dec 22, 2021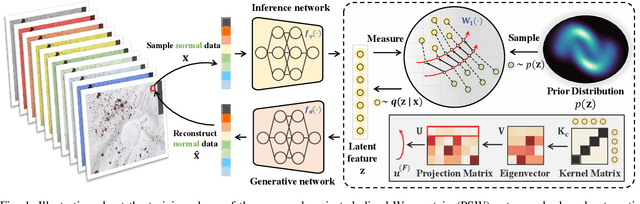

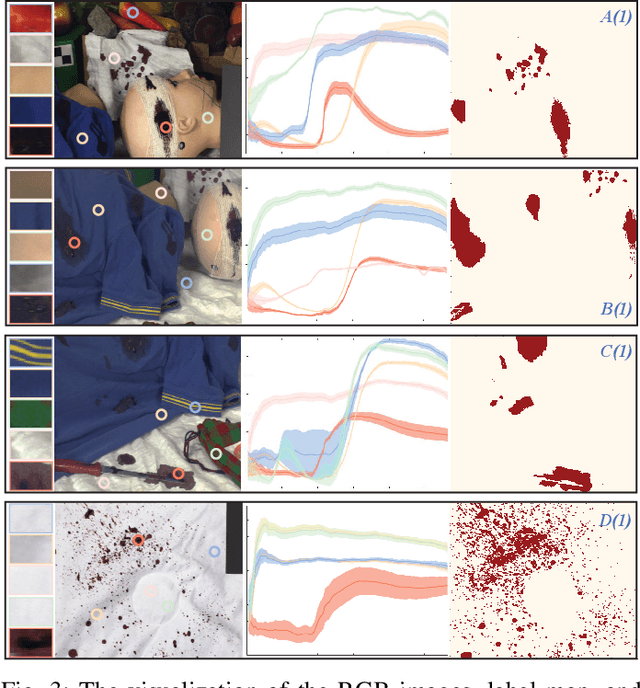
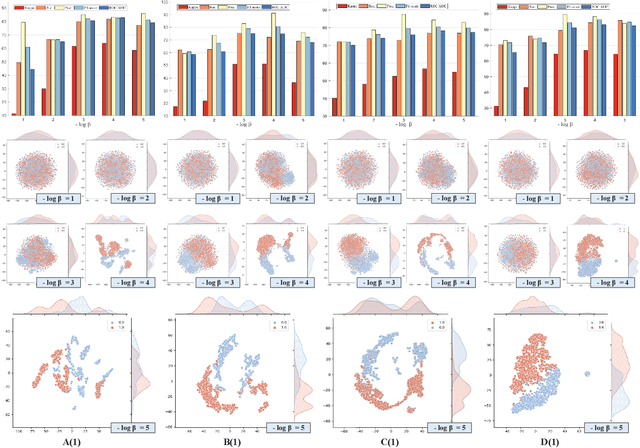
Anomaly detection (AD) has been an active research area in various domains. Yet, the increasing data scale, complexity, and dimension turn the traditional methods into challenging. Recently, the deep generative model, such as the variational autoencoder (VAE), has sparked a renewed interest in the AD problem. However, the probability distribution divergence used as the regularization is too strong, which causes the model cannot capture the manifold of the true data. In this paper, we propose the Projected Sliced Wasserstein (PSW) autoencoder-based anomaly detection method. Rooted in the optimal transportation, the PSW distance is a weaker distribution measure compared with $f$-divergence. In particular, the computation-friendly eigen-decomposition method is leveraged to find the principal component for slicing the high-dimensional data. In this case, the Wasserstein distance can be calculated with the closed-form, even the prior distribution is not Gaussian. Comprehensive experiments conducted on various real-world hyperspectral anomaly detection benchmarks demonstrate the superior performance of the proposed method.
Deconvolution-and-convolution Networks
Mar 22, 2021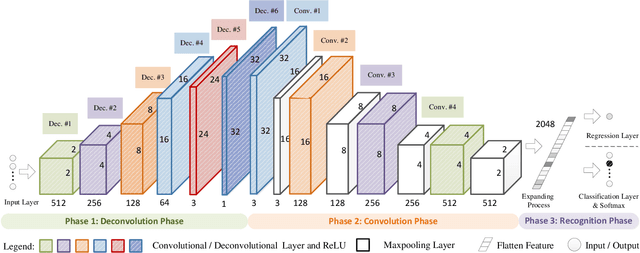
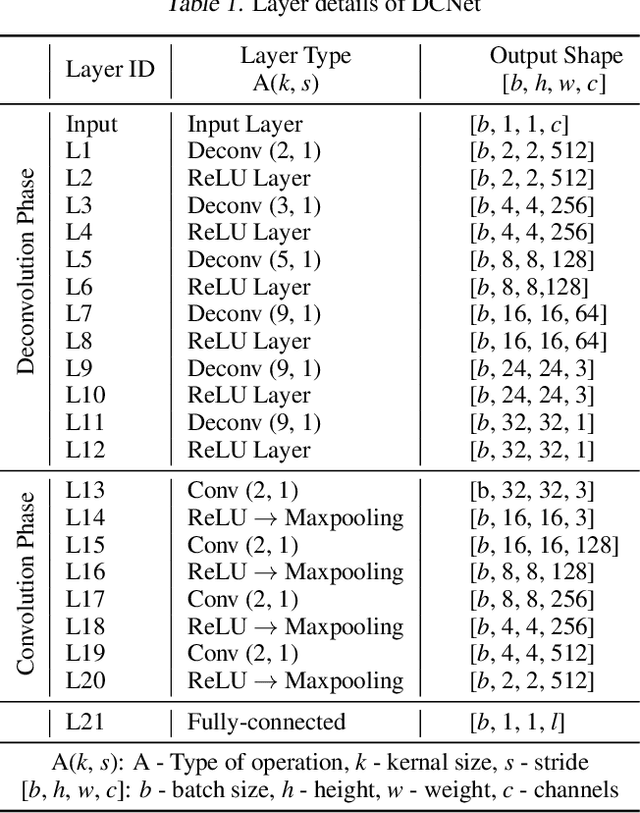
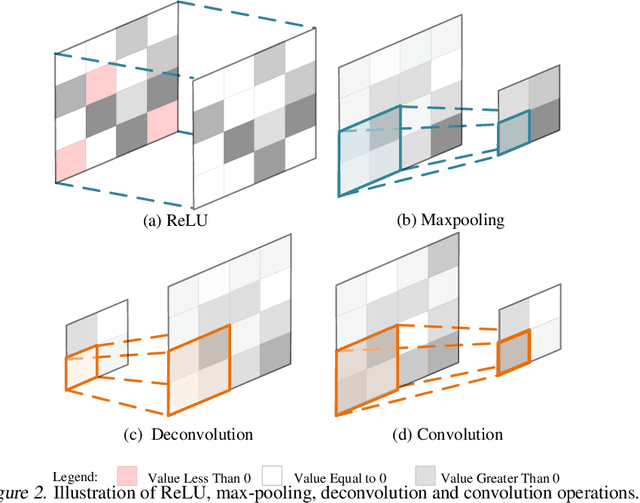
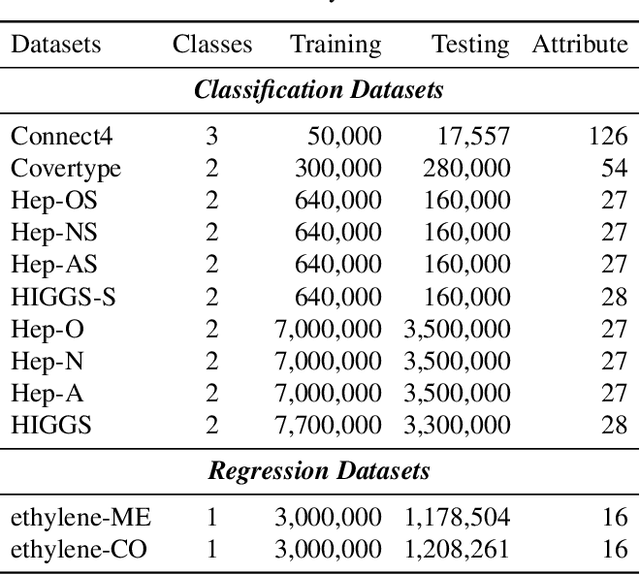
2D Convolutional neural network (CNN) has arguably become the de facto standard for computer vision tasks. Recent findings, however, suggest that CNN may not be the best option for 1D pattern recognition, especially for datasets with over 1 M training samples, e.g., existing CNN-based methods for 1D signals are highly reliant on human pre-processing. Common practices include utilizing discrete Fourier transform (DFT) to reconstruct 1D signal into 2D array. To add to extant knowledge, in this paper, a novel 1D data processing algorithm is proposed for 1D big data analysis through learning a deep deconvolutional-convolutional network. Rather than resorting to human-based techniques, we employed deconvolution layers to convert 1 D signals into 2D data. On top of the deconvolution model, the data was identified by a 2D CNN. Compared with the existing 1D signal processing algorithms, DCNet boasts the advantages of less human-made inference and higher generalization performance. Our experimental results from a varying number of training patterns (50 K to 11 M) from classification and regression demonstrate the desirability of our new approach.
Multi-Model Least Squares-Based Recomputation Framework for Large Data Analysis
Jan 10, 2021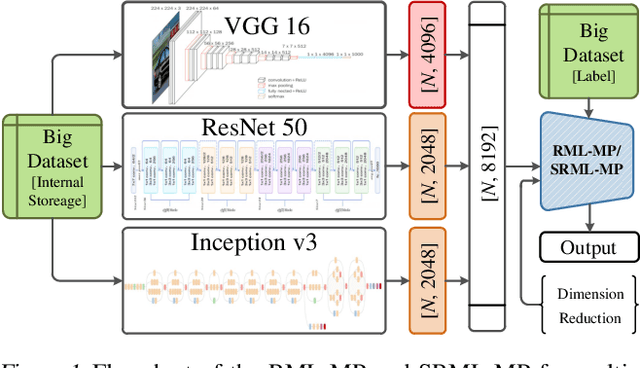

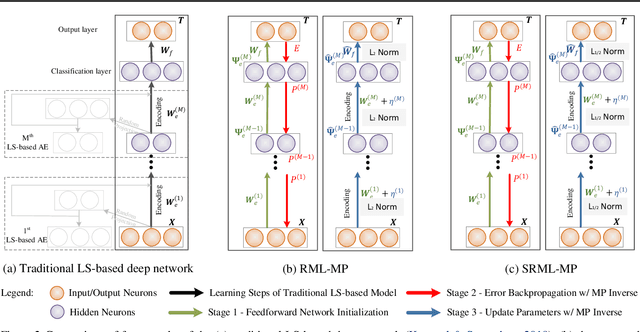
Most multilayer least squares (LS)-based neural networks are structured with two separate stages: unsupervised feature encoding and supervised pattern classification. Once the unsupervised learning is finished, the latent encoding would be fixed without supervised fine-tuning. However, in complex tasks such as handling the ImageNet dataset, there are often many more clues that can be directly encoded, while the unsupervised learning, by definition cannot know exactly what is useful for a certain task. This serves as the motivation to retrain the latent space representations to learn some clues that unsupervised learning has not yet learned. In particular, the error matrix from the output layer is pulled back to each hidden layer, and the parameters of the hidden layer are recalculated with Moore-Penrose (MP) inverse for more generalized representations. In this paper, a recomputation-based multilayer network using MP inverse (RML-MP) is developed. A sparse RML-MP (SRML-MP) model to boost the performance of RML-MP is then proposed. The experimental results with varying training samples (from 3 K to 1.8 M) show that the proposed models provide better generalization performance than most representation learning algorithms.
Deep Networks with Fast Retraining
Aug 13, 2020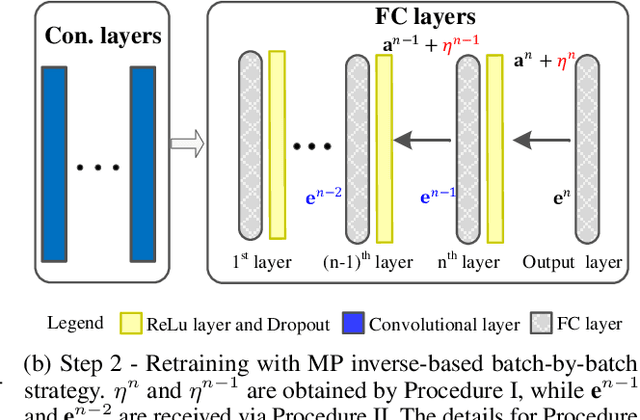
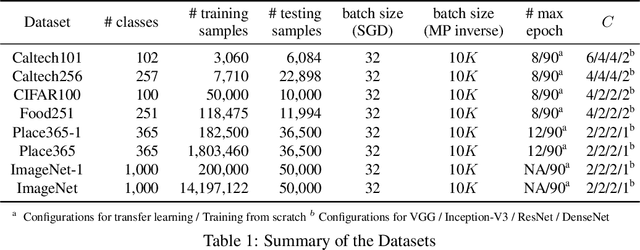
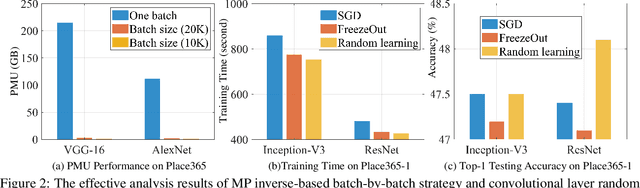
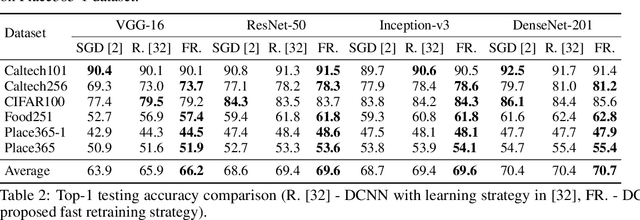
Recent wor [1] has utilized Moore-Penrose (MP) inverse in deep convolutional neural network (DCNN) training, which achieves better generalization performance over the DCNN with a stochastic gradient descent (SGD) pipeline. However, the MP technique cannot be processed in the GPU environment due to its high demands of computational resources. This paper proposes a fast DCNN learning strategy with MP inverse to achieve better testing performance without introducing a large calculation burden. We achieve this goal through an SGD and MP inverse-based two-stage training procedure. In each training epoch, a random learning strategy that controls the number of convolutional layers trained in backward pass is utilized, and an MP inverse-based batch-by-batch learning strategy is developed that enables the network to be implemented with GPU acceleration and to refine the parameters in dense layer. Through experiments on image classification datasets with various training images ranging in amount from 3,060 (Caltech101) to 1,803,460 (Place365), we empirically demonstrate that the fast retraining is a unified strategy that can be utilized in all DCNNs. Our method obtains up to 1% Top-1 testing accuracy boosts over the state-of-the-art DCNN learning pipeline, yielding a savings in training time of 15% to 25% over the work in [1]. [1] Y. Yang, J. Wu, X. Feng, and A. Thangarajah, "Recomputation of dense layers for the perfor-238mance improvement of dcnn," IEEE Trans. Pattern Anal. Mach. Intell., 2019.