 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning for Image Segmentation: A Comprehensive Survey
May 19, 2025Supervised learning demands large amounts of precisely annotated data to achieve promising results. Such data curation is labor-intensive and imposes significant overhead regarding time and costs. Self-supervised learning (SSL) partially overcomes these limitations by exploiting vast amounts of unlabeled data and creating surrogate (pretext or proxy) tasks to learn useful representations without manual labeling. As a result, SSL has become a powerful machine learning (ML) paradigm for solving several practical downstream computer vision problems, such as classification, detection, and segmentation. Image segmentation is the cornerstone of many high-level visual perception applications, including medical imaging, intelligent transportation, agriculture, and surveillance. Although there is substantial research potential for developing advanced algorithms for SSL-based semantic segmentation, a comprehensive study of existing methodologies is essential to trace advances and guide emerging researchers. This survey thoroughly investigates over 150 recent image segmentation articles, particularly focusing on SSL. It provides a practical categorization of pretext tasks, downstream tasks, and commonly used benchmark datasets for image segmentation research. It concludes with key observations distilled from a large body of literature and offers future directions to make this research field more accessible and comprehensible for readers.
LBL: Logarithmic Barrier Loss Function for One-class Classification
Jul 20, 2023



One-class classification (OCC) aims to train a classifier only with the target class data and attracts great attention for its strong applicability in real-world application. Despite a lot of advances have been made in OCC, it still lacks the effective OCC loss functions for deep learning. In this paper, a novel logarithmic barrier function based OCC loss (LBL) that assigns large gradients to the margin samples and thus derives more compact hypersphere, is first proposed by approximating the OCC objective smoothly. But the optimization of LBL may be instability especially when samples lie on the boundary leading to the infinity loss. To address this issue, then, a unilateral relaxation Sigmoid function is introduced into LBL and a novel OCC loss named LBLSig is proposed. The LBLSig can be seen as the fusion of the mean square error (MSE) and the cross entropy (CE) and the optimization of LBLSig is smoother owing to the unilateral relaxation Sigmoid function. The effectiveness of the proposed LBL and LBLSig is experimentally demonstrated in comparisons with several state-of-the-art OCC algorithms on different network structures. The source code can be found at https://github.com/ML-HDU/LBL_LBLSig.
ANOVA-based Automatic Attribute Selection and a Predictive Model for Heart Disease Prognosis
Jul 30, 2022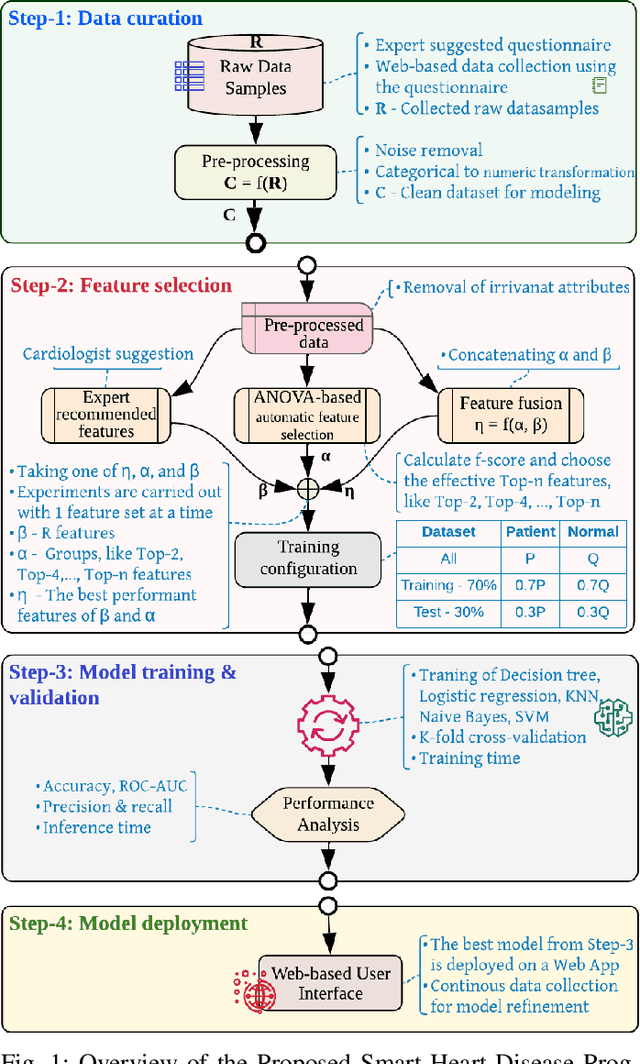

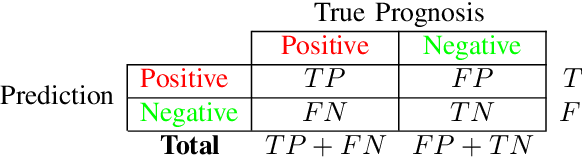
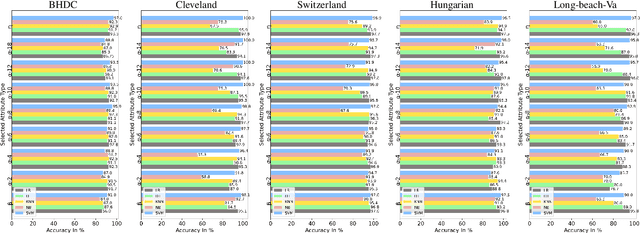
Studies show that Studies that cardiovascular diseases (CVDs) are malignant for human health. Thus, it is important to have an efficient way of CVD prognosis. In response to this, the healthcare industry has adopted machine learning-based smart solutions to alleviate the manual process of CVD prognosis. Thus, this work proposes an information fusion technique that combines key attributes of a person through analysis of variance (ANOVA) and domain experts' knowledge. It also introduces a new collection of CVD data samples for emerging research. There are thirty-eight experiments conducted exhaustively to verify the performance of the proposed framework on four publicly available benchmark datasets and the newly created dataset in this work. The ablation study shows that the proposed approach can achieve a competitive mean average accuracy (mAA) of 99.2% and a mean average AUC of 97.9%.
Deconvolution-and-convolution Networks
Mar 22, 2021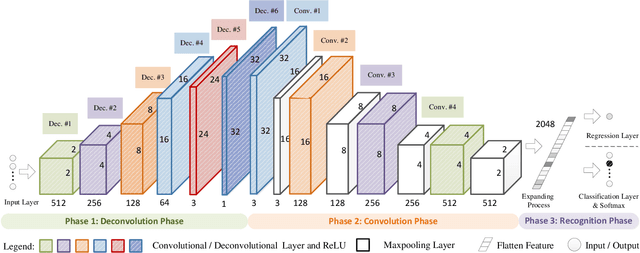
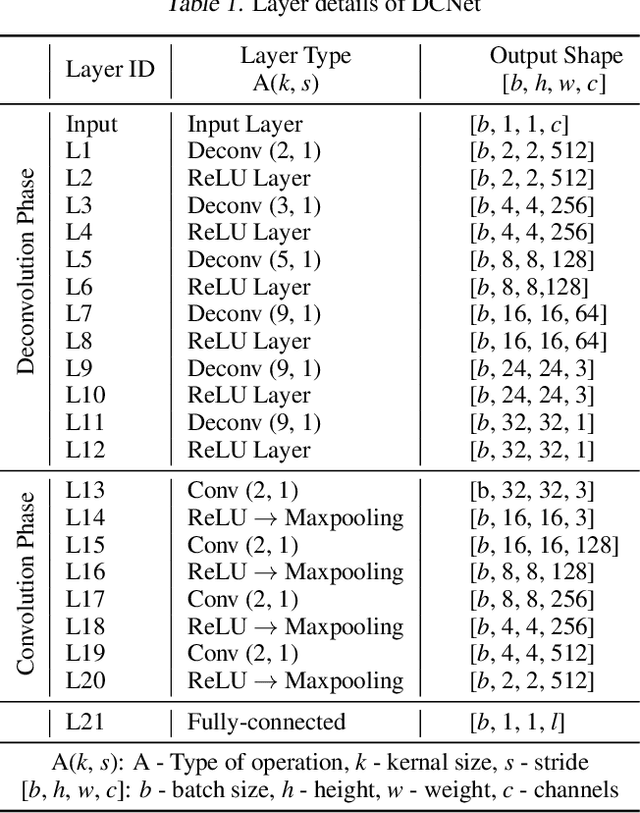
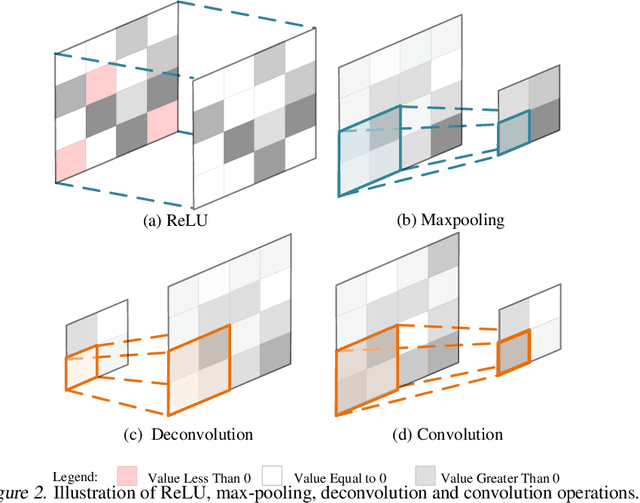
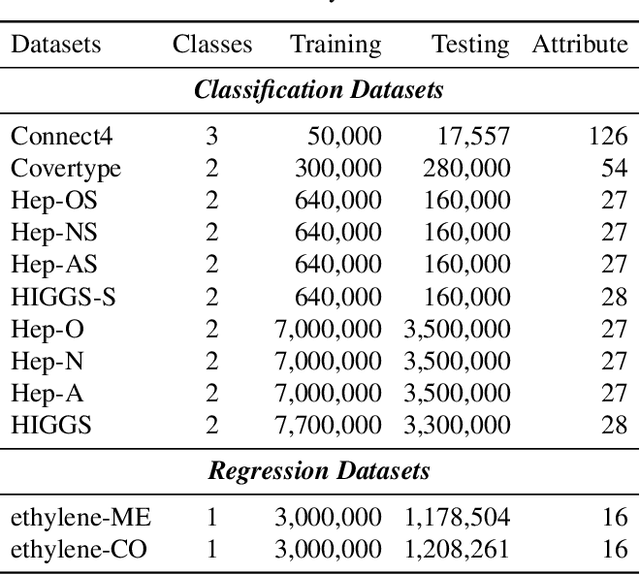
2D Convolutional neural network (CNN) has arguably become the de facto standard for computer vision tasks. Recent findings, however, suggest that CNN may not be the best option for 1D pattern recognition, especially for datasets with over 1 M training samples, e.g., existing CNN-based methods for 1D signals are highly reliant on human pre-processing. Common practices include utilizing discrete Fourier transform (DFT) to reconstruct 1D signal into 2D array. To add to extant knowledge, in this paper, a novel 1D data processing algorithm is proposed for 1D big data analysis through learning a deep deconvolutional-convolutional network. Rather than resorting to human-based techniques, we employed deconvolution layers to convert 1 D signals into 2D data. On top of the deconvolution model, the data was identified by a 2D CNN. Compared with the existing 1D signal processing algorithms, DCNet boasts the advantages of less human-made inference and higher generalization performance. Our experimental results from a varying number of training patterns (50 K to 11 M) from classification and regression demonstrate the desirability of our new approach.
Multi-Model Least Squares-Based Recomputation Framework for Large Data Analysis
Jan 10, 2021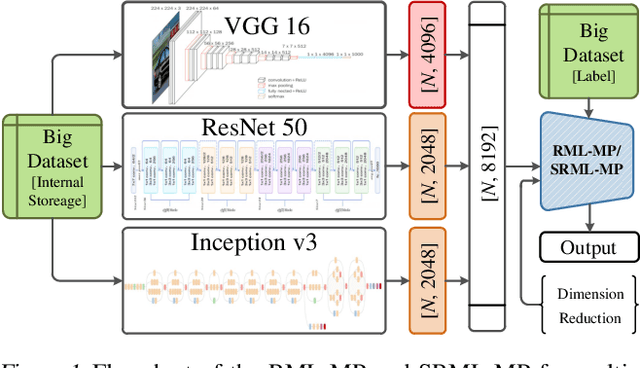

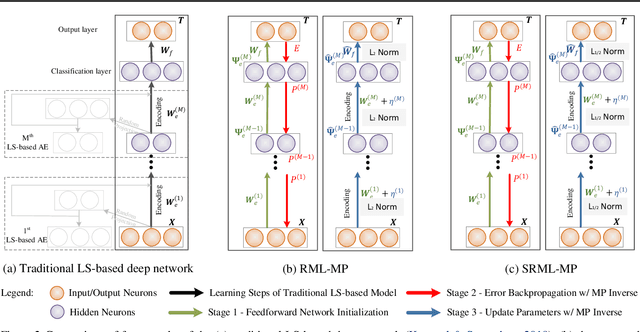
Most multilayer least squares (LS)-based neural networks are structured with two separate stages: unsupervised feature encoding and supervised pattern classification. Once the unsupervised learning is finished, the latent encoding would be fixed without supervised fine-tuning. However, in complex tasks such as handling the ImageNet dataset, there are often many more clues that can be directly encoded, while the unsupervised learning, by definition cannot know exactly what is useful for a certain task. This serves as the motivation to retrain the latent space representations to learn some clues that unsupervised learning has not yet learned. In particular, the error matrix from the output layer is pulled back to each hidden layer, and the parameters of the hidden layer are recalculated with Moore-Penrose (MP) inverse for more generalized representations. In this paper, a recomputation-based multilayer network using MP inverse (RML-MP) is developed. A sparse RML-MP (SRML-MP) model to boost the performance of RML-MP is then proposed. The experimental results with varying training samples (from 3 K to 1.8 M) show that the proposed models provide better generalization performance than most representation learning algorithms.
Deep Networks with Fast Retraining
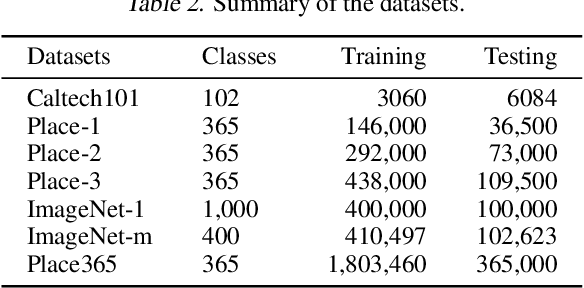
Aug 13, 2020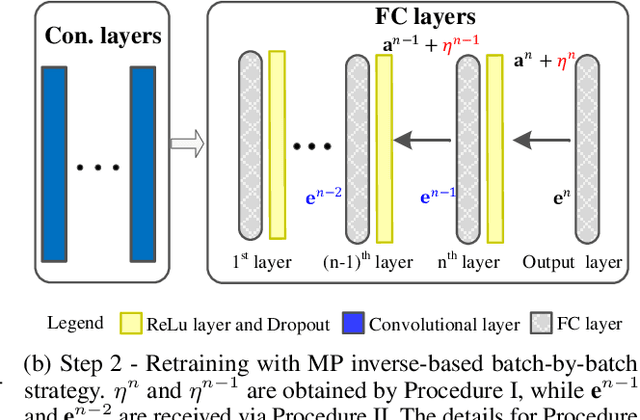
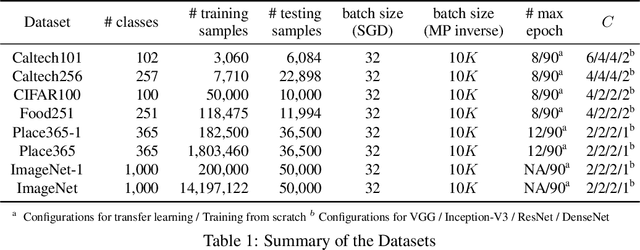
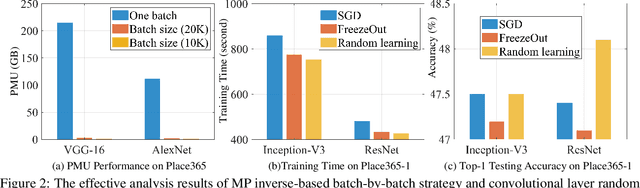
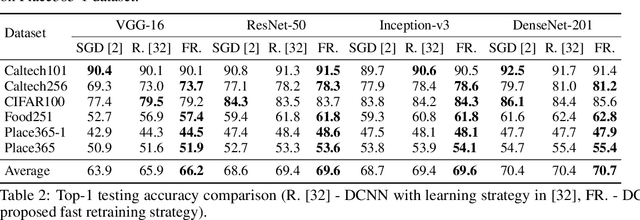
Recent wor [1] has utilized Moore-Penrose (MP) inverse in deep convolutional neural network (DCNN) training, which achieves better generalization performance over the DCNN with a stochastic gradient descent (SGD) pipeline. However, the MP technique cannot be processed in the GPU environment due to its high demands of computational resources. This paper proposes a fast DCNN learning strategy with MP inverse to achieve better testing performance without introducing a large calculation burden. We achieve this goal through an SGD and MP inverse-based two-stage training procedure. In each training epoch, a random learning strategy that controls the number of convolutional layers trained in backward pass is utilized, and an MP inverse-based batch-by-batch learning strategy is developed that enables the network to be implemented with GPU acceleration and to refine the parameters in dense layer. Through experiments on image classification datasets with various training images ranging in amount from 3,060 (Caltech101) to 1,803,460 (Place365), we empirically demonstrate that the fast retraining is a unified strategy that can be utilized in all DCNNs. Our method obtains up to 1% Top-1 testing accuracy boosts over the state-of-the-art DCNN learning pipeline, yielding a savings in training time of 15% to 25% over the work in [1]. [1] Y. Yang, J. Wu, X. Feng, and A. Thangarajah, "Recomputation of dense layers for the perfor-238mance improvement of dcnn," IEEE Trans. Pattern Anal. Mach. Intell., 2019.