 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Vision and Language: Codebook Anchored Visual Adaptation
Feb 23, 2026Large Vision-Language Models (LVLMs) use their vision encoders to translate images into representations for downstream reasoning, but the encoders often underperform in domain-specific visual tasks such as medical image diagnosis or fine-grained classification, where representation errors can cascade through the language model, leading to incorrect responses. Existing adaptation methods modify the continuous feature interface between encoder and language model through projector tuning or other parameter-efficient updates, which still couples the two components and requires re-alignment whenever the encoder changes. We introduce CRAFT (Codebook RegulAted Fine-Tuning), a lightweight method that fine-tunes the encoder using a discrete codebook that anchors visual representations to a stable token space, achieving domain adaptation without modifying other parts of the model. This decoupled design allows the adapted encoder to seamlessly boost the performance of LVLMs with different language architectures, as long as they share the same codebook. Empirically, CRAFT achieves an average gain of 13.51% across 10 domain-specific benchmarks such as VQARAD and PlantVillage, while preserving the LLM's linguistic capabilities and outperforming peer methods that operate on continuous tokens.
A Review of End-to-End Precipitation Prediction Using Remote Sensing Data: from Divination to Machine Learning
Oct 26, 2025Precipitation prediction has undergone a profound transformation -- from early symbolic and empirical methods rooted in divination and observation, to modern technologies based on atmospheric physics and artificial intelligence. This review traces the historical and technological evolution of precipitation forecasting, presenting a survey about end-to-end precipitation prediction technologies that spans ancient practices, the foundations of meteorological science, the rise of numerical weather prediction (NWP), and the emergence of machine learning (ML) and deep learning (DL) models. We first explore traditional and indigenous forecasting methods, then describe the development of physical modeling and statistical frameworks that underpin contemporary operational forecasting. Particular emphasis is placed on recent advances in neural network-based approaches, including automated deep learning, interpretability-driven design, and hybrid physical-data models. By compositing research across multiple eras and paradigms, this review not only depicts the history of end-to-end precipitation prediction but also outlines future directions in next generation forecasting systems.
Deconvolution-and-convolution Networks
Mar 22, 2021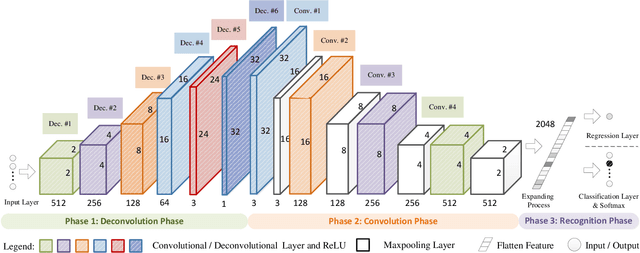
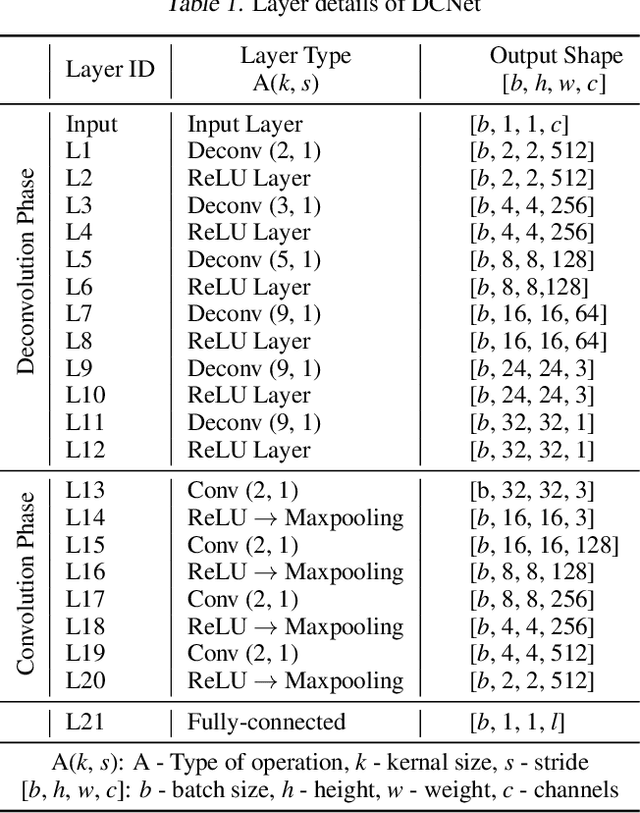
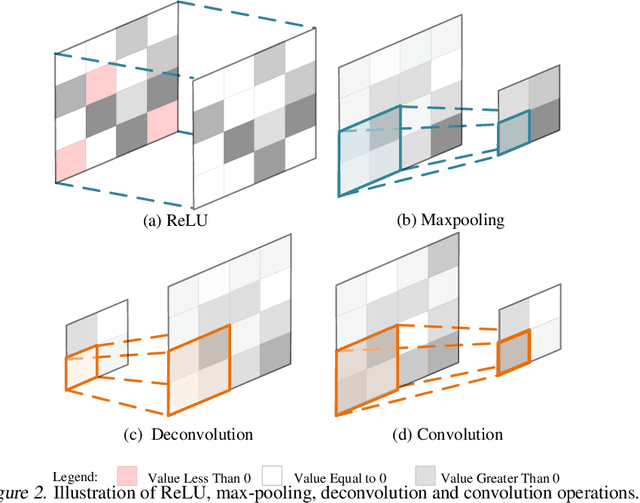
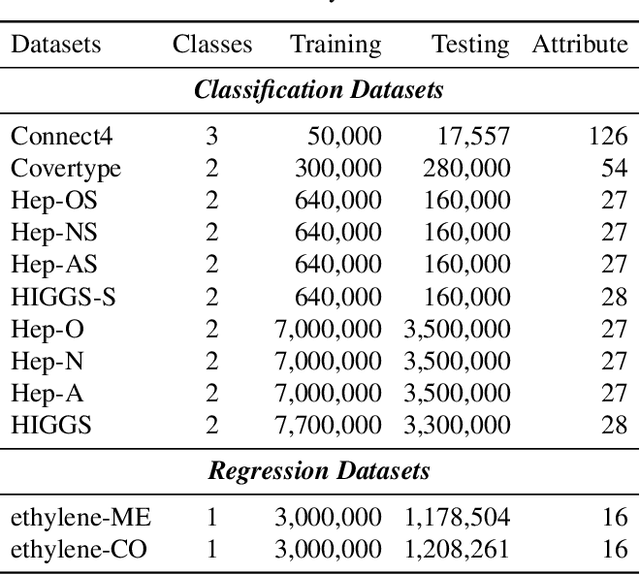
2D Convolutional neural network (CNN) has arguably become the de facto standard for computer vision tasks. Recent findings, however, suggest that CNN may not be the best option for 1D pattern recognition, especially for datasets with over 1 M training samples, e.g., existing CNN-based methods for 1D signals are highly reliant on human pre-processing. Common practices include utilizing discrete Fourier transform (DFT) to reconstruct 1D signal into 2D array. To add to extant knowledge, in this paper, a novel 1D data processing algorithm is proposed for 1D big data analysis through learning a deep deconvolutional-convolutional network. Rather than resorting to human-based techniques, we employed deconvolution layers to convert 1 D signals into 2D data. On top of the deconvolution model, the data was identified by a 2D CNN. Compared with the existing 1D signal processing algorithms, DCNet boasts the advantages of less human-made inference and higher generalization performance. Our experimental results from a varying number of training patterns (50 K to 11 M) from classification and regression demonstrate the desirability of our new approach.
Deep Networks with Fast Retraining
Aug 13, 2020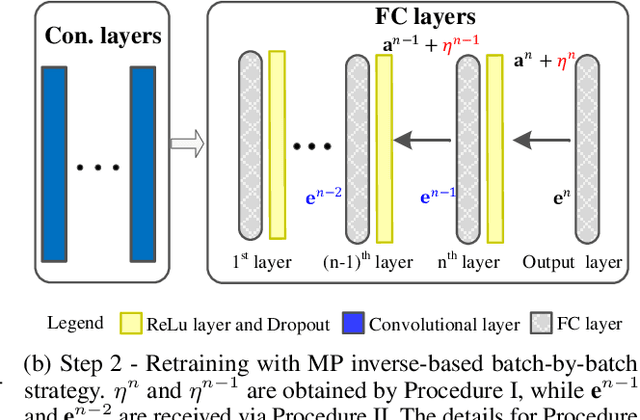
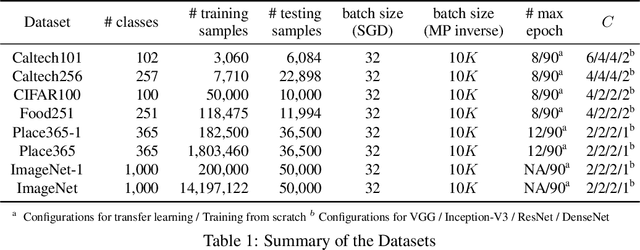
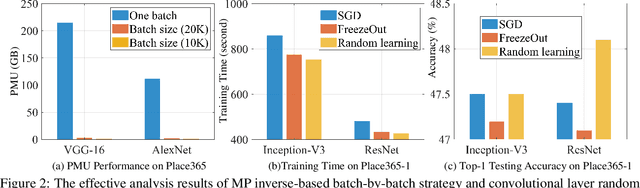
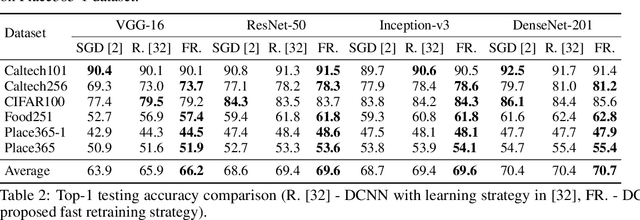
Recent wor [1] has utilized Moore-Penrose (MP) inverse in deep convolutional neural network (DCNN) training, which achieves better generalization performance over the DCNN with a stochastic gradient descent (SGD) pipeline. However, the MP technique cannot be processed in the GPU environment due to its high demands of computational resources. This paper proposes a fast DCNN learning strategy with MP inverse to achieve better testing performance without introducing a large calculation burden. We achieve this goal through an SGD and MP inverse-based two-stage training procedure. In each training epoch, a random learning strategy that controls the number of convolutional layers trained in backward pass is utilized, and an MP inverse-based batch-by-batch learning strategy is developed that enables the network to be implemented with GPU acceleration and to refine the parameters in dense layer. Through experiments on image classification datasets with various training images ranging in amount from 3,060 (Caltech101) to 1,803,460 (Place365), we empirically demonstrate that the fast retraining is a unified strategy that can be utilized in all DCNNs. Our method obtains up to 1% Top-1 testing accuracy boosts over the state-of-the-art DCNN learning pipeline, yielding a savings in training time of 15% to 25% over the work in [1]. [1] Y. Yang, J. Wu, X. Feng, and A. Thangarajah, "Recomputation of dense layers for the perfor-238mance improvement of dcnn," IEEE Trans. Pattern Anal. Mach. Intell., 2019.
Semi-Coupled Two-Stream Fusion ConvNets for Action Recognition at Extremely Low Resolutions
Oct 05, 2018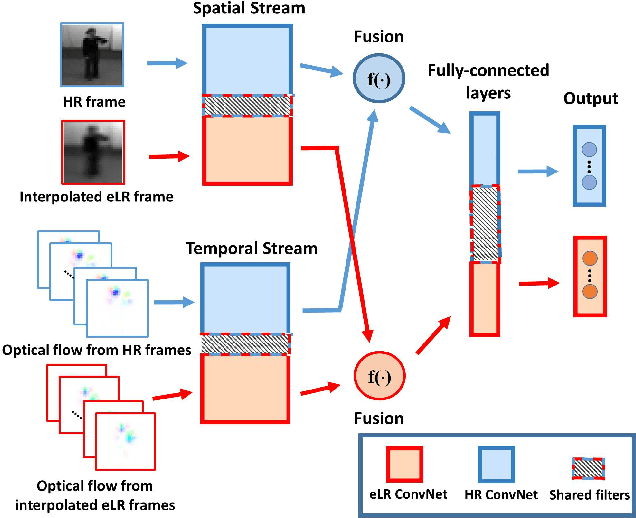

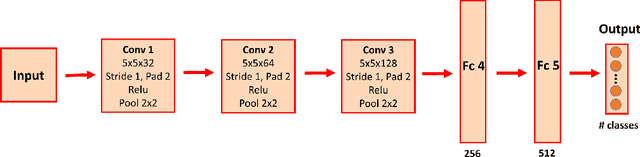
Deep convolutional neural networks (ConvNets) have been recently shown to attain state-of-the-art performance for action recognition on standard-resolution videos. However, less attention has been paid to recognition performance at extremely low resolutions (eLR) (e.g., 16 x 12 pixels). Reliable action recognition using eLR cameras would address privacy concerns in various application environments such as private homes, hospitals, nursing/rehabilitation facilities, etc. In this paper, we propose a semi-coupled filter-sharing network that leverages high resolution (HR) videos during training in order to assist an eLR ConvNet. We also study methods for fusing spatial and temporal ConvNets customized for eLR videos in order to take advantage of appearance and motion information. Our method outperforms state-of-the-art methods at extremely low resolutions on IXMAS (93.7%) and HMDB (29.2%) datasets.