 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lesion-aware Edge-based Graph Neural Network for Predicting Language Ability in Patients with Post-stroke Aphasia
Sep 03, 2024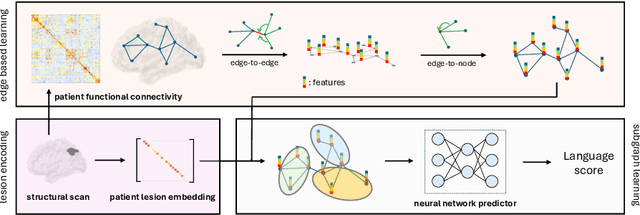



We propose a lesion-aware graph neural network (LEGNet) to predict language ability from resting-state fMRI (rs-fMRI) connectivity in patients with post-stroke aphasia. Our model integrates three components: an edge-based learning module that encodes functional connectivity between brain regions, a lesion encoding module, and a subgraph learning module that leverages functional similarities for prediction. We use synthetic data derived from the Human Connectome Project (HCP) for hyperparameter tuning and model pretraining. We then evaluate the performance using repeated 10-fold cross-validation on an in-house neuroimaging dataset of post-stroke aphasia. Our results demonstrate that LEGNet outperforms baseline deep learning methods in predicting language ability. LEGNet also exhibits superior generalization ability when tested on a second in-house dataset that was acquired under a slightly different neuroimaging protocol. Taken together, the results of this study highlight the potential of LEGNet in effectively learning the relationships between rs-fMRI connectivity and language ability in a patient cohort with brain lesions for improved post-stroke aphasia evaluation.
FBINeRF: Feature-Based Integrated Recurrent Network for Pinhole and Fisheye Neural Radiance Fields
Aug 03, 2024Previous studies aiming to optimize and bundle-adjust camera poses using Neural Radiance Fields (NeRFs), such as BARF and DBARF, have demonstrated impressive capabilities in 3D scene reconstruction. However, these approaches have been designed for pinhole-camera pose optimization and do not perform well under radial image distortions such as those in fisheye cameras. Furthermore, inaccurate depth initialization in DBARF results in erroneous geometric information affecting the overall convergence and quality of results. In this paper, we propose adaptive GRUs with a flexible bundle-adjustment method adapted to radial distortions and incorporate feature-based recurrent neural networks to generate continuous novel views from fisheye datasets. Other NeRF methods for fisheye images, such as SCNeRF and OMNI-NeRF, use projected ray distance loss for distorted pose refinement, causing severe artifacts, long rendering time, and are difficult to use in downstream tasks, where the dense voxel representation generated by a NeRF method needs to be converted into a mesh representation. We also address depth initialization issues by adding MiDaS-based depth priors for pinhole images. Through extensive experiments, we demonstrate the generalization capacity of FBINeRF and show high-fidelity results for both pinhole-camera and fisheye-camera NeRFs.
Spatio-Visual Fusion-Based Person Re-Identification for Overhead Fisheye Images
Dec 22, 2022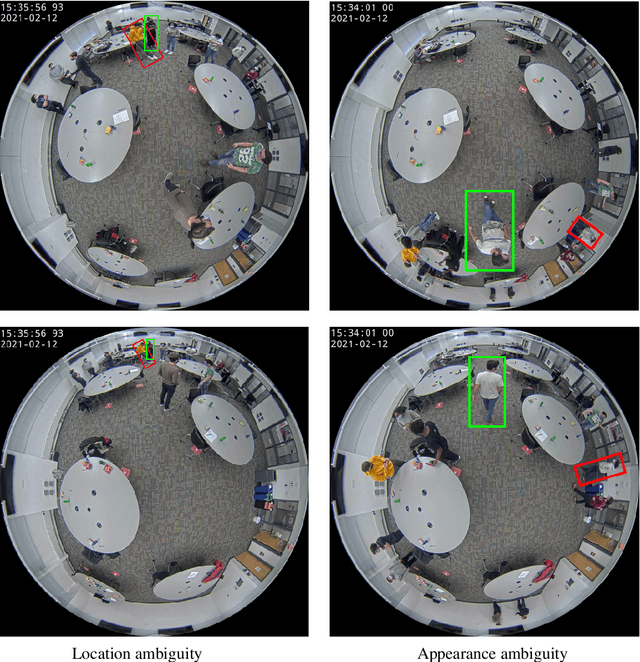

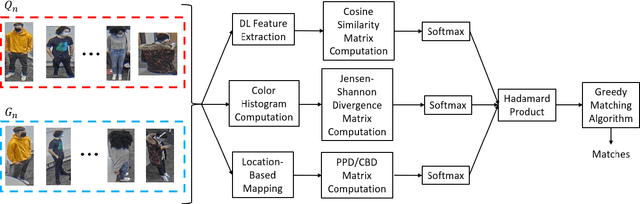
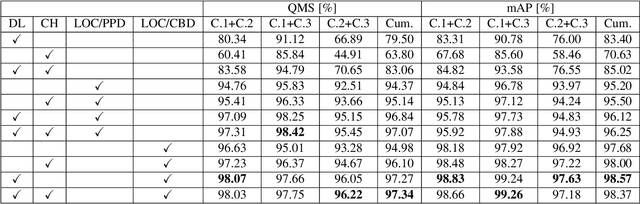
Reliable and cost-effective counting of people in large indoor spaces is a significant challenge with many applications. An emerging approach is to deploy multiple fisheye cameras mounted overhead to monitor the whole space. However, due to the overlapping fields of view, person re-identificaiton (PRID) is critical for the accuracy of counting. While PRID has been thoroughly researched for traditional rectilinear cameras, few methods have been proposed for fisheye cameras and their performance is comparatively lower. To close this performance gap, we propose a multi-feature framework for fisheye PRID where we combine deep-learning, color-based and location-based features by means of novel feature fusion. We evaluate the performance of our framework for various feature combinations on FRIDA, a public fisheye PRID dataset. The results demonstrate that our multi-feature approach outperforms recent appearance-based deep-learning methods by almost 18% points and location-based methods by almost 3% points in accuracy.
FRIDA: Fisheye Re-Identification Dataset with Annotations
Oct 04, 2022
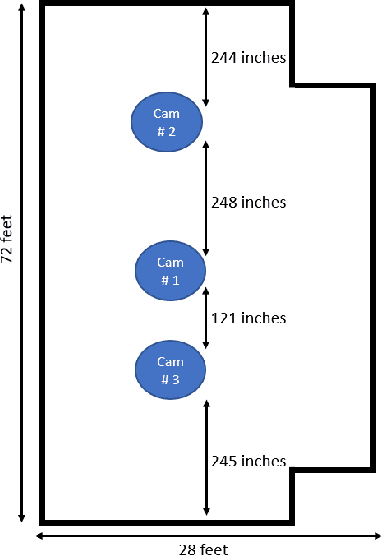


Person re-identification (PRID) from side-mounted rectilinear-lens cameras is a well-studied problem. On the other hand, PRID from overhead fisheye cameras is new and largely unstudied, primarily due to the lack of suitable image datasets. To fill this void, we introduce the "Fisheye Re-IDentification Dataset with Annotations" (FRIDA), with 240k+ bounding-box annotations of people, captured by 3 time-synchronized, ceiling-mounted fisheye cameras in a large indoor space. Due to a field-of-view overlap, PRID in this case differs from a typical PRID problem, which we discuss in depth. We also evaluate the performance of 10 state-of-the-art PRID algorithms on FRIDA. We show that for 6 CNN-based algorithms, training on FRIDA boosts the performance by up to 11.64% points in mAP compared to training on a common rectilinear-camera PRID dataset.
BSUV-Net 2.0: Spatio-Temporal Data Augmentations for Video-Agnostic Supervised Background Subtraction
Feb 24, 2021
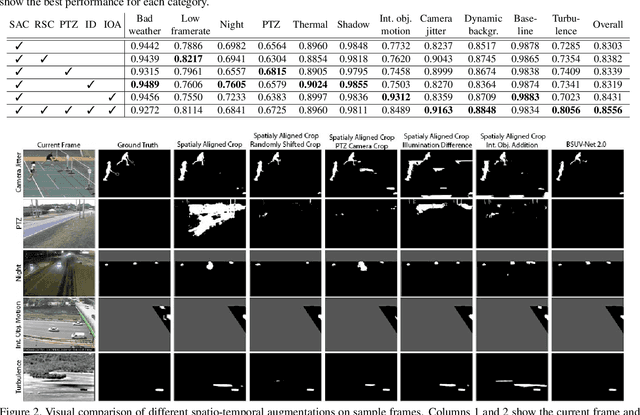
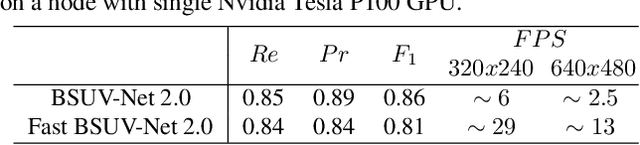
Background subtraction (BGS) is a fundamental video processing task which is a key component of many applications. Deep learning-based supervised algorithms achieve very good perforamnce in BGS, however, most of these algorithms are optimized for either a specific video or a group of videos, and their performance decreases dramatically when applied to unseen videos. Recently, several papers addressed this problem and proposed video-agnostic supervised BGS algorithms. However, nearly all of the data augmentations used in these algorithms are limited to the spatial domain and do not account for temporal variations that naturally occur in video data. In this work, we introduce spatio-temporal data augmentations and apply them to one of the leading video-agnostic BGS algorithms, BSUV-Net. We also introduce a new cross-validation training and evaluation strategy for the CDNet-2014 dataset that makes it possible to fairly and easily compare the performance of various video-agnostic supervised BGS algorithms. Our new model trained using the proposed data augmentations, named BSUV-Net 2.0, significantly outperforms state-of-the-art algorithms evaluated on unseen videos of CDNet-2014. We also evaluate the cross-dataset generalization capacity of BSUV-Net 2.0 by training it solely on CDNet-2014 videos and evaluating its performance on LASIESTA dataset. Overall, BSUV-Net 2.0 provides a ~5% improvement in the F-score over state-of-the-art methods on unseen videos of CDNet-2014 and LASIESTA datasets. Furthermore, we develop a real-time variant of our model, that we call Fast BSUV-Net 2.0, whose performance is close to the state of the art.
RAPiD: Rotation-Aware People Detection in Overhead Fisheye Images
May 23, 2020

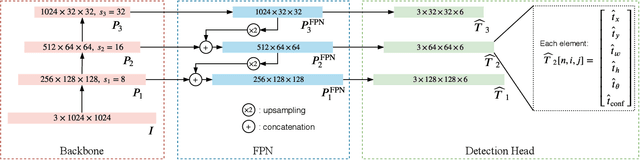
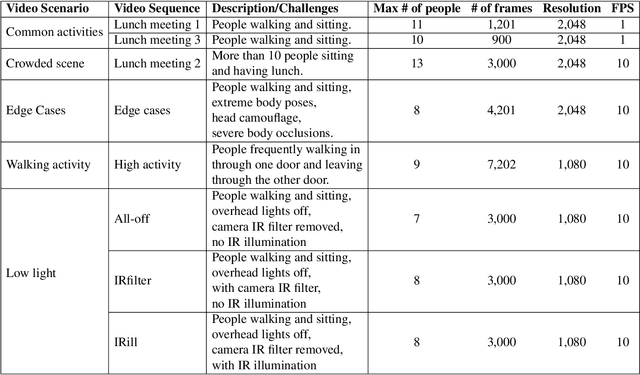
Recent methods for people detection in overhead, fisheye images either use radially-aligned bounding boxes to represent people, assuming people always appear along image radius or require significant pre-/post-processing which radically increases computational complexity. In this work, we develop an end-to-end rotation-aware people detection method, named RAPiD, that detects people using arbitrarily-oriented bounding boxes. Our fully-convolutional neural network directly regresses the angle of each bounding box using a periodic loss function, which accounts for angle periodicities. We have also created a new dataset with spatio-temporal annotations of rotated bounding boxes, for people detection as well as other vision tasks in overhead fisheye videos. We show that our simple, yet effective method outperforms state-of-the-art results on three fisheye-image datasets. Code and dataset are available at http://vip.bu.edu/rapid .
Low-Resolution Overhead Thermal Tripwire for Occupancy Estimation
May 05, 2020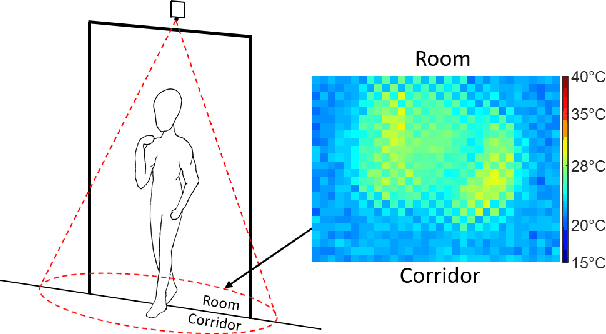
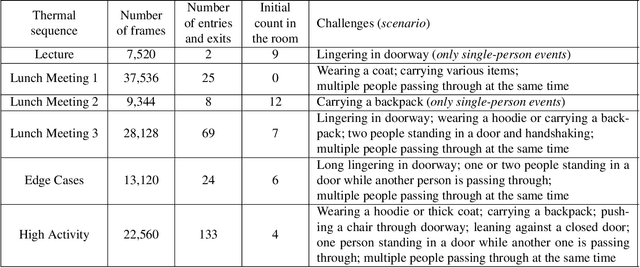
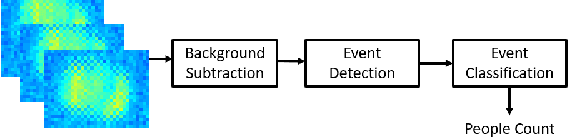
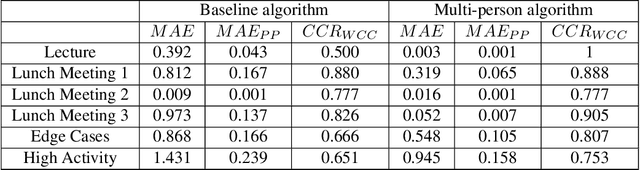
Smart buildings use occupancy sensing for various tasks ranging from energy-efficient HVAC and lighting to space-utilization analysis and emergency response. We propose a people counting system which uses a low-resolution thermal sensor. Unlike previous people-counting systems based on thermal sensors, we use an overhead tripwire configuration at entryways to detect and track transient entries or exits. We develop two distinct people counting algorithms for this configuration. To evaluate our algorithms, we have collected and labeled a low-resolution thermal video dataset using the proposed system. The dataset, the first of its kind, is public and available for download. We also propose new evaluation metrics that are more suitable for systems that are subject to drift and jitter.
VAE/WGAN-Based Image Representation Learning For Pose-Preserving Seamless Identity Replacement In Facial Images
Mar 02, 2020We present a novel variational generative adversarial network (VGAN) based on Wasserstein loss to learn a latent representation from a face image that is invariant to identity but preserves head-pose information. This facilitates synthesis of a realistic face image with the same head pose as a given input image, but with a different identity. One application of this network is in privacy-sensitive scenarios; after identity replacement in an image, utility, such as head pose, can still be recovered. Extensive experimental validation on synthetic and real human-face image datasets performed under 3 threat scenarios confirms the ability of the proposed network to preserve head pose of the input image, mask the input identity, and synthesize a good-quality realistic face image of a desired identity. We also show that our network can be used to perform pose-preserving identity morphing and identity-preserving pose morphing. The proposed method improves over a recent state-of-the-art method in terms of quantitative metrics as well as synthesized image quality.
* 6 pages, 5 figures, 2019 IEEE 29th International Workshop on Machine Learning for Signal Processing (MLSP)
A Fully-Convolutional Neural Network for Background Subtraction of Unseen Videos
Jul 26, 2019
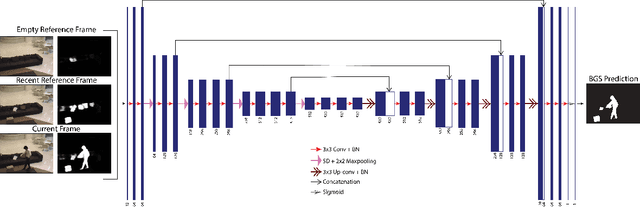
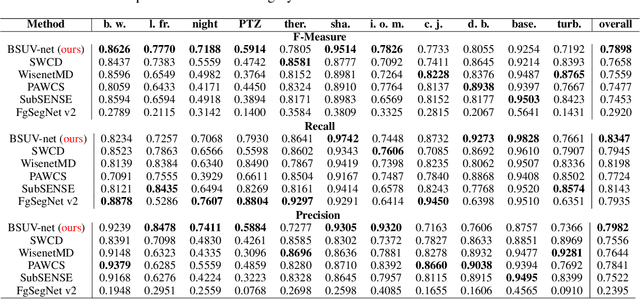

Background subtraction is a basic task in computer vision and video processing often applied as a pre-processing step for object tracking, people recognition, etc. Recently, a number of successful background subtraction algorithms have been proposed, however nearly all of the top-performing ones are supervised. Crucially, their success relies upon the availability of some annotated frames of the test video during training. Consequently, their performance on completely unseen videos is undocumented in the literature. In this work, we propose a new, supervised, background-subtraction algorithm for unseen videos (BSUV-Net) based on a fully-convolutional neural network. The input to our network consists of the current frame and two background frames captured at different time scales along with their semantic segmentation maps. In order to reduce the chance of overfitting, we also introduce a new data-augmentation technique which mitigates the impact of illumination difference between the background frames and the current frame. On the CDNet-2014 dataset, BSUV-Net outperforms state-of-the-art algorithms evaluated on unseen videos in terms of F-measure, recall and precision metrics.
A Cyclically-Trained Adversarial Network for Invariant Representation Learning
Jun 21, 2019
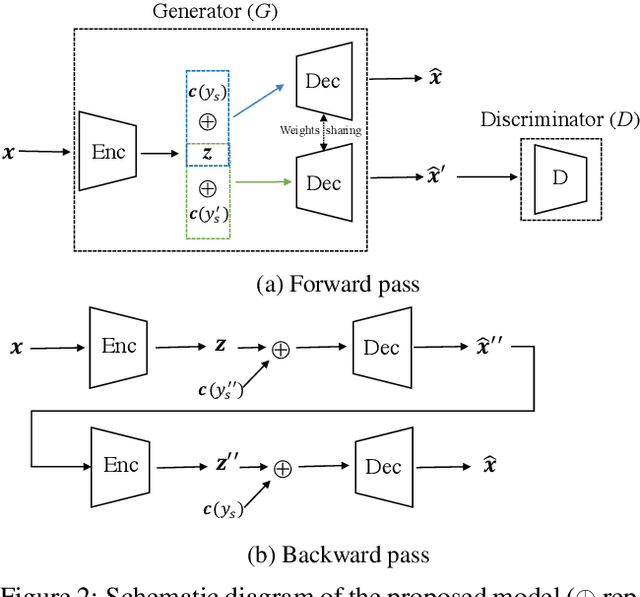
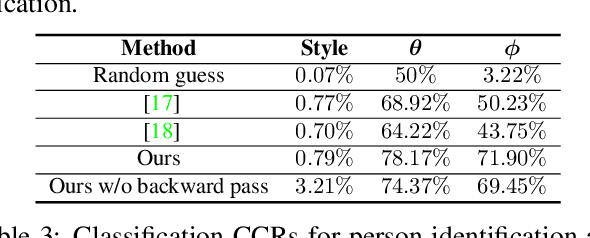
We propose a cyclically-trained adversarial network to learn mappings from image space to a latent representation space and back such that the latent representation is invariant to a specified factor of variation (e.g., identity). The learned mappings also assure that the synthesized image is not only realistic, but has the same values for unspecified factors (e.g., pose and illumination) as the original image and a desired value of the specified factor. We encourage invariance to a specified factor, by applying adversarial training using a variational autoencoder in the image space as opposed to the latent space. We strengthen this invariance by introducing a cyclic training process (forward and backward pass). We also propose a new method to evaluate conditional generative networks. It compares how well different factors of variation can be predicted from the synthesized, as opposed to real, images. We demonstrate the effectiveness of our approach on factors such as identity, pose, illumination or style on three datasets and compare it with state-of-the-art methods. Our network produces good quality synthetic images and, interestingly, can be used to perform face morphing in latent space.