 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCL-LoRA: Continual Low-Rank Adaptation for Rehearsal-Free Class-Incremental Learning
May 30, 2025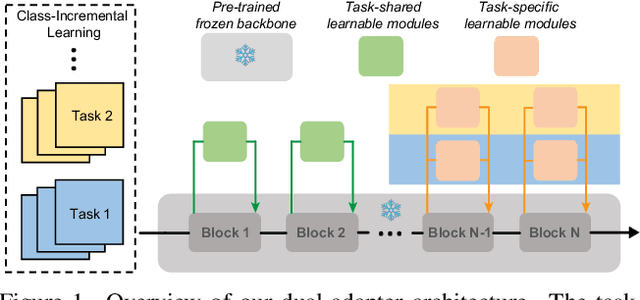
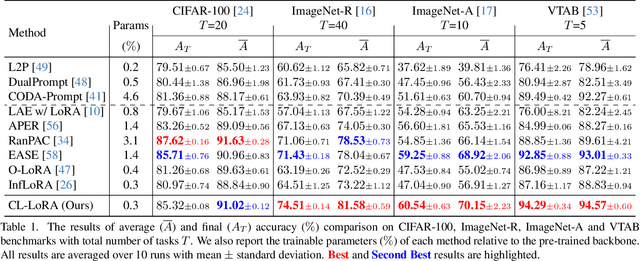
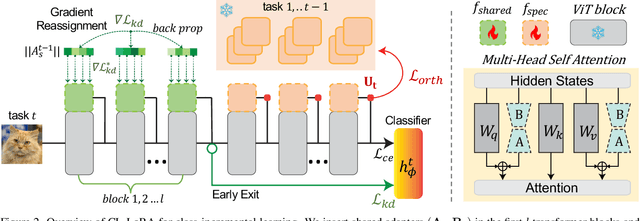
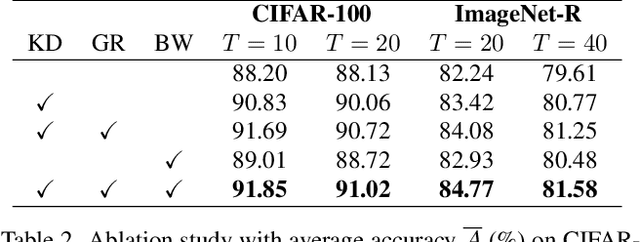
Class-Incremental Learning (CIL) aims to learn new classes sequentially while retaining the knowledge of previously learned classes. Recently, pre-trained models (PTMs) combined with parameter-efficient fine-tuning (PEFT) have shown remarkable performance in rehearsal-free CIL without requiring exemplars from previous tasks. However, existing adapter-based methods, which incorporate lightweight learnable modules into PTMs for CIL, create new adapters for each new task, leading to both parameter redundancy and failure to leverage shared knowledge across tasks. In this work, we propose ContinuaL Low-Rank Adaptation (CL-LoRA), which introduces a novel dual-adapter architecture combining \textbf{task-shared adapters} to learn cross-task knowledge and \textbf{task-specific adapters} to capture unique features of each new task. Specifically, the shared adapters utilize random orthogonal matrices and leverage knowledge distillation with gradient reassignment to preserve essential shared knowledge. In addition, we introduce learnable block-wise weights for task-specific adapters, which mitigate inter-task interference while maintaining the model's plasticity. We demonstrate CL-LoRA consistently achieves promising performance under multiple benchmarks with reduced training and inference computation, establishing a more efficient and scalable paradigm for continual learning with pre-trained models.
Low-Rank Adaptation of Pre-trained Vision Backbones for Energy-Efficient Image Coding for Machine
May 23, 2025Image Coding for Machines (ICM) focuses on optimizing image compression for AI-driven analysis rather than human perception. Existing ICM frameworks often rely on separate codecs for specific tasks, leading to significant storage requirements, training overhead, and computational complexity. To address these challenges, we propose an energy-efficient framework that leverages pre-trained vision backbones to extract robust and versatile latent representations suitable for multiple tasks. We introduce a task-specific low-rank adaptation mechanism, which refines the pre-trained features to be both compressible and tailored to downstream applications. This design minimizes trainable parameters and reduces energy costs for multi-task scenarios. By jointly optimizing task performance and entropy minimization, our method enables efficient adaptation to diverse tasks and datasets without full fine-tuning, achieving high coding efficiency. Extensive experiments demonstrate that our framework significantly outperforms traditional codecs and pre-processors, offering an energy-efficient and effective solution for ICM applications. The code and the supplementary materials will be available at: https://gitlab.com/viper-purdue/efficient-compression.
Accelerating Learned Image Compression Through Modeling Neural Training Dynamics
May 23, 2025As learned image compression (LIC) methods become increasingly computationally demanding, enhancing their training efficiency is crucial. This paper takes a step forward in accelerating the training of LIC methods by modeling the neural training dynamics. We first propose a Sensitivity-aware True and Dummy Embedding Training mechanism (STDET) that clusters LIC model parameters into few separate modes where parameters are expressed as affine transformations of reference parameters within the same mode. By further utilizing the stable intra-mode correlations throughout training and parameter sensitivities, we gradually embed non-reference parameters, reducing the number of trainable parameters. Additionally, we incorporate a Sampling-then-Moving Average (SMA) technique, interpolating sampled weights from stochastic gradient descent (SGD) training to obtain the moving average weights, ensuring smooth temporal behavior and minimizing training state variances. Overall, our method significantly reduces training space dimensions and the number of trainable parameters without sacrificing model performance, thus accelerating model convergence. We also provide a theoretical analysis on the Noisy quadratic model, showing that the proposed method achieves a lower training variance than standard SGD. Our approach offers valuable insights for further developing efficient training methods for LICs.
Balanced Rate-Distortion Optimization in Learned Image Compression
Feb 27, 2025Learned image compression (LIC) using deep learning architectures has seen significant advancements, yet standard rate-distortion (R-D) optimization often encounters imbalanced updates due to diverse gradients of the rate and distortion objectives. This imbalance can lead to suboptimal optimization, where one objective dominates, thereby reducing overall compression efficiency. To address this challenge, we reformulate R-D optimization as a multi-objective optimization (MOO) problem and introduce two balanced R-D optimization strategies that adaptively adjust gradient updates to achieve more equitable improvements in both rate and distortion. The first proposed strategy utilizes a coarse-to-fine gradient descent approach along standard R-D optimization trajectories, making it particularly suitable for training LIC models from scratch. The second proposed strategy analytically addresses the reformulated optimization as a quadratic programming problem with an equality constraint, which is ideal for fine-tuning existing models. Experimental results demonstrate that both proposed methods enhance the R-D performance of LIC models, achieving around a 2\% BD-Rate reduction with acceptable additional training cost, leading to a more balanced and efficient optimization process. The code will be made publicly available.
High-Efficiency Neural Video Compression via Hierarchical Predictive Learning
Oct 03, 2024


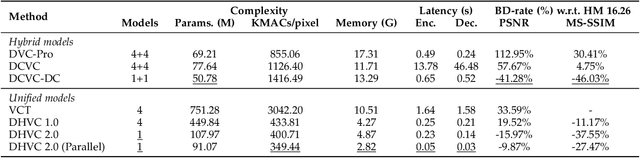
The enhanced Deep Hierarchical Video Compression-DHVC 2.0-has been introduced. This single-model neural video codec operates across a broad range of bitrates, delivering not only superior compression performance to representative methods but also impressive complexity efficiency, enabling real-time processing with a significantly smaller memory footprint on standard GPUs. These remarkable advancements stem from the use of hierarchical predictive coding. Each video frame is uniformly transformed into multiscale representations through hierarchical variational autoencoders. For a specific scale's feature representation of a frame, its corresponding latent residual variables are generated by referencing lower-scale spatial features from the same frame and then conditionally entropy-encoded using a probabilistic model whose parameters are predicted using same-scale temporal reference from previous frames and lower-scale spatial reference of the current frame. This feature-space processing operates from the lowest to the highest scale of each frame, completely eliminating the need for the complexity-intensive motion estimation and compensation techniques that have been standard in video codecs for decades. The hierarchical approach facilitates parallel processing, accelerating both encoding and decoding, and supports transmission-friendly progressive decoding, making it particularly advantageous for networked video applications in the presence of packet loss. Source codes will be made available.
On Efficient Neural Network Architectures for Image Compression
Jun 14, 2024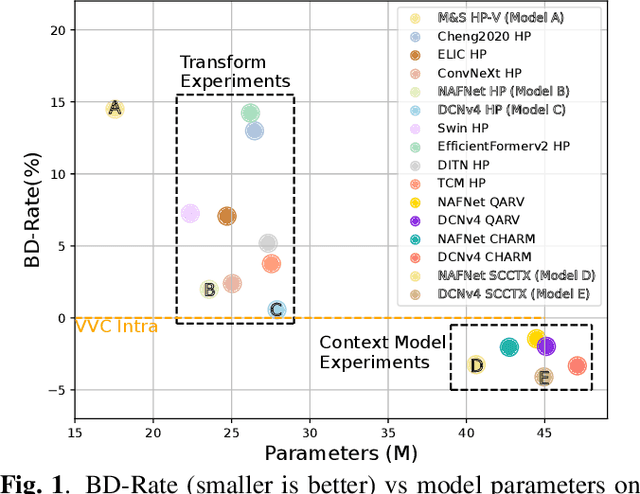
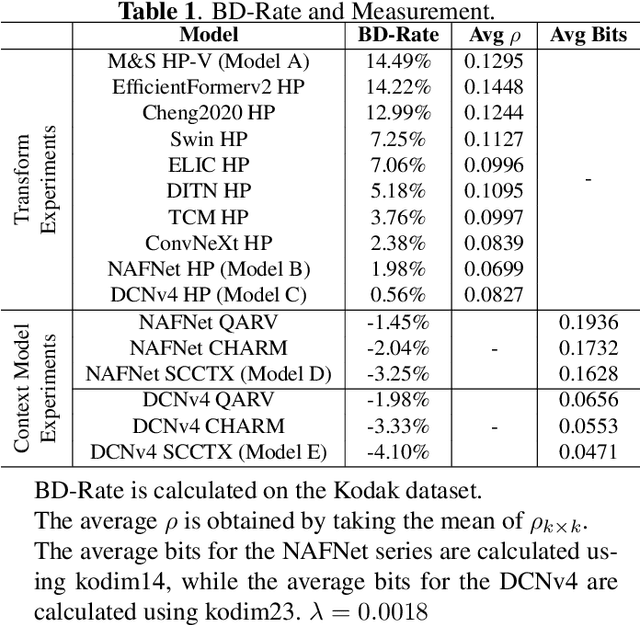
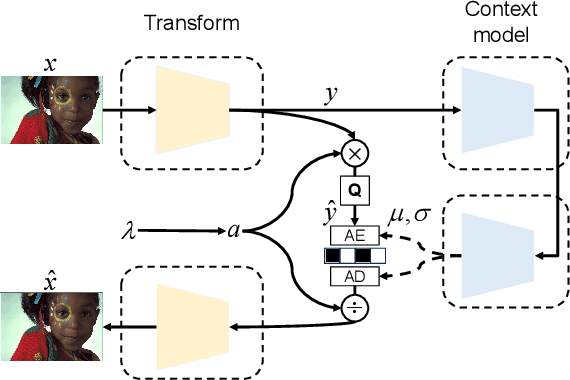
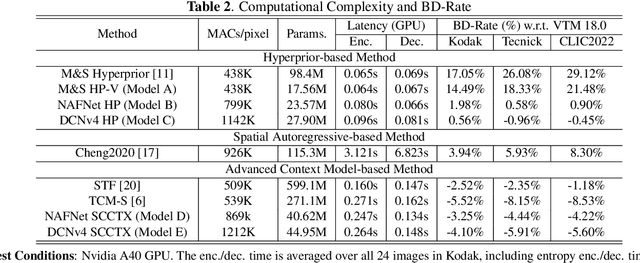
Recent advances in learning-based image compression typically come at the cost of high complexity. Designing computationally efficient architectures remains an open challenge. In this paper, we empirically investigate the impact of different network designs in terms of rate-distortion performance and computational complexity. Our experiments involve testing various transforms, including convolutional neural networks and transformers, as well as various context models, including hierarchical, channel-wise, and space-channel context models. Based on the results, we present a series of efficient models, the final model of which has comparable performance to recent best-performing methods but with significantly lower complexity. Extensive experiments provide insights into the design of architectures for learned image compression and potential direction for future research. The code is available at \url{https://gitlab.com/viper-purdue/efficient-compression}.
Learning to Classify New Foods Incrementally Via Compressed Exemplars
Apr 11, 2024Food image classification systems play a crucial role in health monitoring and diet tracking through image-based dietary assessment techniques. However, existing food recognition systems rely on static datasets characterized by a pre-defined fixed number of food classes. This contrasts drastically with the reality of food consumption, which features constantly changing data. Therefore, food image classification systems should adapt to and manage data that continuously evolves. This is where continual learning plays an important role. A challenge in continual learning is catastrophic forgetting, where ML models tend to discard old knowledge upon learning new information. While memory-replay algorithms have shown promise in mitigating this problem by storing old data as exemplars, they are hampered by the limited capacity of memory buffers, leading to an imbalance between new and previously learned data. To address this, our work explores the use of neural image compression to extend buffer size and enhance data diversity. We introduced the concept of continuously learning a neural compression model to adaptively improve the quality of compressed data and optimize the bitrates per pixel (bpp) to store more exemplars. Our extensive experiments, including evaluations on food-specific datasets including Food-101 and VFN-74, as well as the general dataset ImageNet-100, demonstrate improvements in classification accuracy. This progress is pivotal in advancing more realistic food recognition systems that are capable of adapting to continually evolving data. Moreover, the principles and methodologies we've developed hold promise for broader applications, extending their benefits to other domains of continual machine learning systems.
Flexible Variable-Rate Image Feature Compression for Edge-Cloud Systems
Mar 30, 2024



Feature compression is a promising direction for coding for machines. Existing methods have made substantial progress, but they require designing and training separate neural network models to meet different specifications of compression rate, performance accuracy and computational complexity. In this paper, a flexible variable-rate feature compression method is presented that can operate on a range of rates by introducing a rate control parameter as an input to the neural network model. By compressing different intermediate features of a pre-trained vision task model, the proposed method can scale the encoding complexity without changing the overall size of the model. The proposed method is more flexible than existing baselines, at the same time outperforming them in terms of the three-way trade-off between feature compression rate, vision task accuracy, and encoding complexity. We have made the source code available at https://github.com/adnan-hossain/var_feat_comp.git.
Theoretical Bound-Guided Hierarchical VAE for Neural Image Codecs
Mar 27, 2024Recent studies reveal a significant theoretical link between variational autoencoders (VAEs) and rate-distortion theory, notably in utilizing VAEs to estimate the theoretical upper bound of the information rate-distortion function of images. Such estimated theoretical bounds substantially exceed the performance of existing neural image codecs (NICs). To narrow this gap, we propose a theoretical bound-guided hierarchical VAE (BG-VAE) for NIC. The proposed BG-VAE leverages the theoretical bound to guide the NIC model towards enhanced performance. We implement the BG-VAE using Hierarchical VAEs and demonstrate its effectiveness through extensive experiments. Along with advanced neural network blocks, we provide a versatile, variable-rate NIC that outperforms existing methods when considering both rate-distortion performance and computational complexity. The code is available at BG-VAE.
Probing Image Compression For Class-Incremental Learning
Mar 10, 2024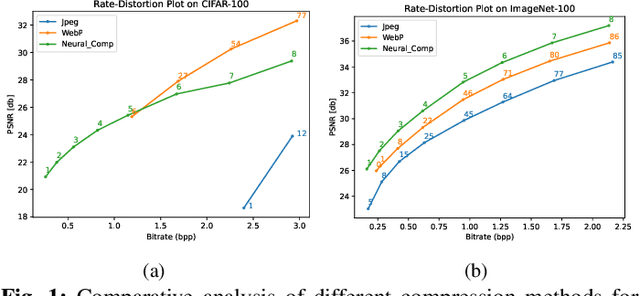
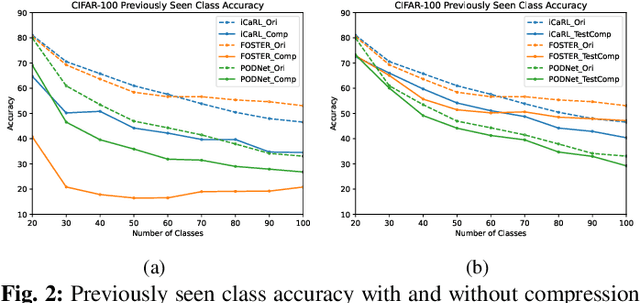
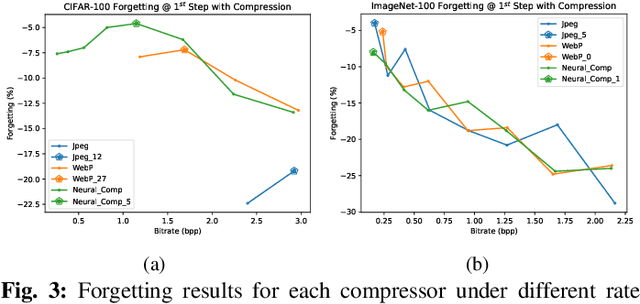
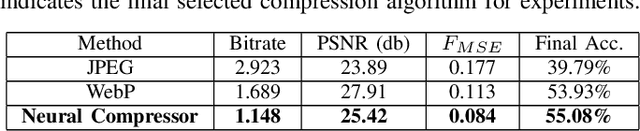
Image compression emerges as a pivotal tool in the efficient handling and transmission of digital images. Its ability to substantially reduce file size not only facilitates enhanced data storage capacity but also potentially brings advantages to the development of continual machine learning (ML) systems, which learn new knowledge incrementally from sequential data. Continual ML systems often rely on storing representative samples, also known as exemplars, within a limited memory constraint to maintain the performance on previously learned data. These methods are known as memory replay-based algorithms and have proven effective at mitigating the detrimental effects of catastrophic forgetting. Nonetheless, the limited memory buffer size often falls short of adequately representing the entire data distribution. In this paper, we explore the use of image compression as a strategy to enhance the buffer's capacity, thereby increasing exemplar diversity. However, directly using compressed exemplars introduces domain shift during continual ML, marked by a discrepancy between compressed training data and uncompressed testing data. Additionally, it is essential to determine the appropriate compression algorithm and select the most effective rate for continual ML systems to balance the trade-off between exemplar quality and quantity. To this end, we introduce a new framework to incorporate image compression for continual ML including a pre-processing data compression step and an efficient compression rate/algorithm selection method. We conduct extensive experiments on CIFAR-100 and ImageNet datasets and show that our method significantly improves image classification accuracy in continual ML settings.