 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Image Compression For Class-Incremental Learning
Mar 10, 2024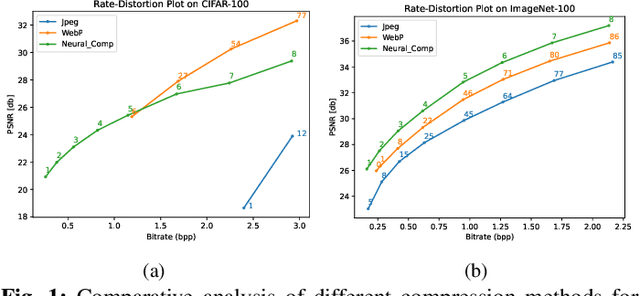
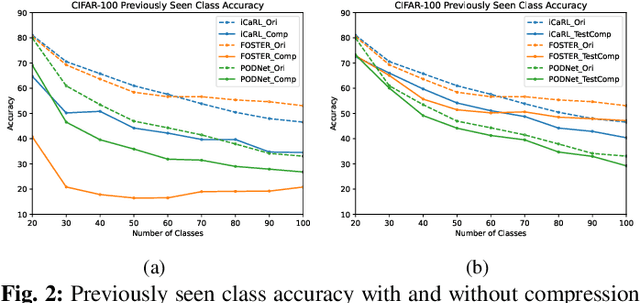
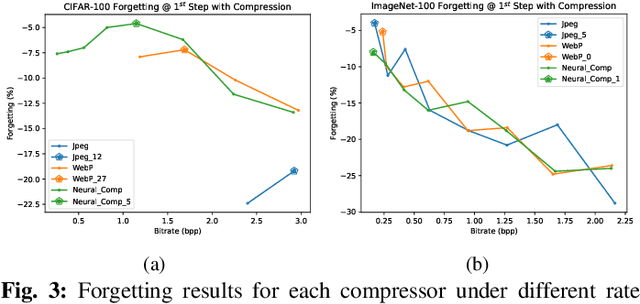
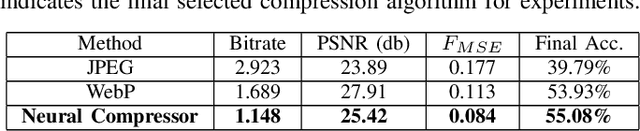
Image compression emerges as a pivotal tool in the efficient handling and transmission of digital images. Its ability to substantially reduce file size not only facilitates enhanced data storage capacity but also potentially brings advantages to the development of continual machine learning (ML) systems, which learn new knowledge incrementally from sequential data. Continual ML systems often rely on storing representative samples, also known as exemplars, within a limited memory constraint to maintain the performance on previously learned data. These methods are known as memory replay-based algorithms and have proven effective at mitigating the detrimental effects of catastrophic forgetting. Nonetheless, the limited memory buffer size often falls short of adequately representing the entire data distribution. In this paper, we explore the use of image compression as a strategy to enhance the buffer's capacity, thereby increasing exemplar diversity. However, directly using compressed exemplars introduces domain shift during continual ML, marked by a discrepancy between compressed training data and uncompressed testing data. Additionally, it is essential to determine the appropriate compression algorithm and select the most effective rate for continual ML systems to balance the trade-off between exemplar quality and quantity. To this end, we introduce a new framework to incorporate image compression for continual ML including a pre-processing data compression step and an efficient compression rate/algorithm selection method. We conduct extensive experiments on CIFAR-100 and ImageNet datasets and show that our method significantly improves image classification accuracy in continual ML settings.
Self-Supervised Visual Representation Learning on Food Images
Mar 16, 2023

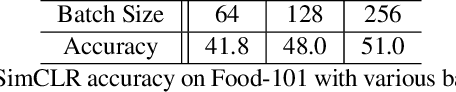

Food image analysis is the groundwork for image-based dietary assessment, which is the process of monitoring what kinds of food and how much energy is consumed using captured food or eating scene images. Existing deep learning-based methods learn the visual representation for downstream tasks based on human annotation of each food image. However, most food images in real life are obtained without labels, and data annotation requires plenty of time and human effort, which is not feasible for real-world applications. To make use of the vast amount of unlabeled images, many existing works focus on unsupervised or self-supervised learning of visual representations directly from unlabeled data. However, none of these existing works focus on food images, which is more challenging than general objects due to its high inter-class similarity and intra-class variance. In this paper, we focus on the implementation and analysis of existing representative self-supervised learning methods on food images. Specifically, we first compare the performance of six selected self-supervised learning models on the Food-101 dataset. Then we analyze the pros and cons of each selected model when training on food data to identify the key factors that can help improve the performance. Finally, we propose several ideas for future work on self-supervised visual representation learning for food images.
Simulating Personal Food Consumption Patterns using a Modified Markov Chain
Aug 13, 2022
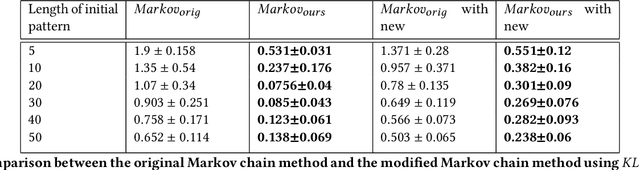
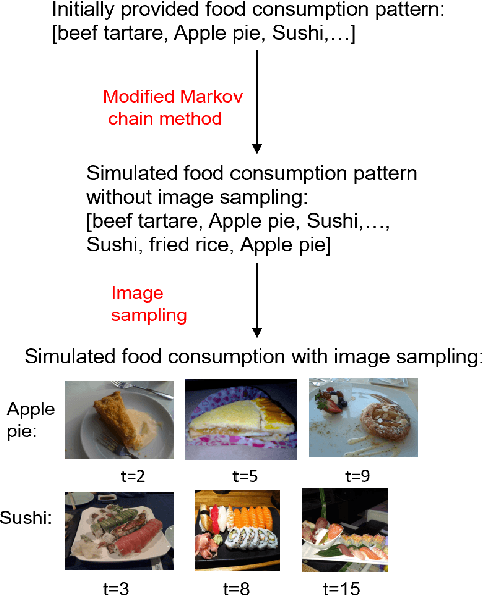
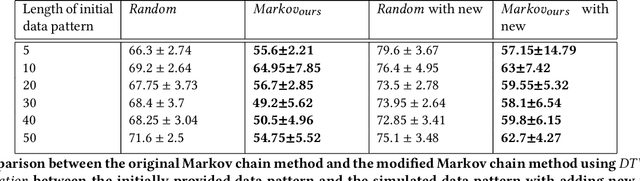
Food image classification serves as the foundation of image-based dietary assessment to predict food categories. Since there are many different food classes in real life, conventional models cannot achieve sufficiently high accuracy. Personalized classifiers aim to largely improve the accuracy of food image classification for each individual. However, a lack of public personal food consumption data proves to be a challenge for training such models. To address this issue, we propose a novel framework to simulate personal food consumption data patterns, leveraging the use of a modified Markov chain model and self-supervised learning. Our method is capable of creating an accurate future data pattern from a limited amount of initial data, and our simulated data patterns can be closely correlated with the initial data pattern. Furthermore, we use Dynamic Time Warping distance and Kullback-Leibler divergence as metrics to evaluate the effectiveness of our method on the public Food-101 dataset. Our experimental results demonstrate promising performance compared with random simulation and the original Markov chain method.