 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-Nutri: Dish-Level Nutrition Estimation from Egocentric Cooking Videos
Apr 13, 2026Nutrition estimation of meals from visual data is an important problem for dietary monitoring and computational health, but existing approaches largely rely on single images of the finally completed dish. This setting is fundamentally limited because many nutritionally relevant ingredients and transformations, such as oils, sauces, and mixed components, become visually ambiguous after cooking, making accurate calorie and macronutrient estimation difficult. In this paper, we investigate whether the cooking process information from egocentric cooking videos can contribute to dish-level nutrition estimation. First, we further manually annotated the HD-EPIC dataset and established the first benchmark for video-based nutrition estimation. Most importantly, we propose V-Nutri, a staged framework that combines Nutrition5K-pretrained visual backbones with a lightweight fusion module that aggregates features from the final dish frame and cooking process keyframes extracted from the egocentric videos. V-Nutri also includes a cooking keyframes selection module, a VideoMamba-based event-detection model that targets ingredient-addition moments. Experiments on the HD-EPIC dataset show that process cues can provide complementary nutritional evidence, improving nutrition estimation under controlled conditions. Our results further indicate that the benefit of process keyframes depends strongly on backbone representation capacity and event detection quality. Our code and annotated dataset is available at https://github.com/K624-YCK/V-Nutri.
Dual-Imbalance Continual Learning for Real-World Food Recognition
Mar 31, 2026Visual food recognition in real-world dietary logging scenarios naturally exhibits severe data imbalance, where a small number of food categories appear frequently while many others occur rarely, resulting in long-tailed class distributions. In practice, food recognition systems often operate in a continual learning setting, where new categories are introduced sequentially over time. However, existing studies typically assume that each incremental step introduces a similar number of new food classes, which rarely happens in real world where the number of newly observed categories can vary significantly across steps, leading to highly uneven learning dynamics. As a result, continual food recognition exhibits a dual imbalance: imbalanced samples within each food class and imbalanced numbers of new food classes to learn at each incremental learning step. In this work, we introduce DIME, a Dual-Imbalance-aware Adapter Merging framework for continual food recognition. DIME learns lightweight adapters for each task using parameter-efficient fine-tuning and progressively integrates them through a class-count guided spectral merging strategy. A rank-wise threshold modulation mechanism further stabilizes the merging process by preserving dominant knowledge while allowing adaptive updates. The resulting model maintains a single merged adapter for inference, enabling efficient deployment without accumulating task-specific modules. Experiments on realistic long-tailed food benchmarks under our step-imbalanced setup show that the proposed method consistently improves by more than 3% over the strongest existing continual learning baselines. Code is available at https://github.com/xiaoyanzhang1/DIME.
Multimodal Fusion of Skeleton Dynamics and Clinical Gait Features for Video-Based Cerebral Palsy Severity Assessment
Mar 23, 2026Video-based gait analysis has become a promising approach for assessing motor impairment in children with cerebral palsy (CP). However, existing methods usually rely on either pose sequences or handcrafted gait features alone, making it difficult to simultaneously capture spatiotemporal motion patterns and clinically meaningful biomechanical information. To address this gap, we propose a multimodal fusion framework that integrates skeleton dynamics with contribution-guided clinically meaningful gait features. First, Grad-CAM analysis on a pre-trained ST-GCN backbone identified the most discriminative body keypoints, providing an interpretable basis for subsequent gait feature extraction. We then build a dual-stream architecture, with one stream modeling skeleton dynamics using ST-GCN and the other encoding gait geatures derived from the identified keypoints. By fusing the two streams through feature cross-attention improved four-level CP motor severity classification to 70.86%, outperforming the baseline by 5.6 percentage points. Overall, this work suggests that integrating skeleton dynamics with clinically meaningful gait descriptors can improve both prediction performance and biomechanical interpretability for video-based CP severity assessment.
One Adapter for All: Towards Unified Representation in Step-Imbalanced Class-Incremental Learning
Mar 10, 2026Class-incremental learning (CIL) aims to acquire new classes over time while retaining prior knowledge, yet most setups and methods assume balanced task streams. In practice, the number of classes per task often varies significantly. We refer to this as step imbalance, where large tasks that contain more classes dominate learning and small tasks inject unstable updates. Existing CIL methods assume balanced tasks and therefore treat all tasks uniformly, producing imbalanced updates that degrade overall learning performance. To address this challenge, we propose One-A, a unified and imbalance-aware framework that incrementally merges task updates into a single adapter, maintaining constant inference cost. One-A performs asymmetric subspace alignment to preserve dominant subspaces learned from large tasks while constraining low-information updates within them. An information-adaptive weighting balances the contribution between base and new adapters, and a directional gating mechanism selectively fuses updates along each singular direction, maintaining stability in head directions and plasticity in tail ones. Across multiple benchmarks and step-imbalanced streams, One-A achieves competitive accuracy with significantly low inference overhead, showing that a single, asymmetrically fused adapter can remain both adaptive to dynamic task sizes and efficient at deployment.
Implicit-Scale 3D Reconstruction for Multi-Food Volume Estimation from Monocular Images
Feb 13, 2026We present Implicit-Scale 3D Reconstruction from Monocular Multi-Food Images, a benchmark dataset designed to advance geometry-based food portion estimation in realistic dining scenarios. Existing dietary assessment methods largely rely on single-image analysis or appearance-based inference, including recent vision-language models, which lack explicit geometric reasoning and are sensitive to scale ambiguity. This benchmark reframes food portion estimation as an implicit-scale 3D reconstruction problem under monocular observations. To reflect real-world conditions, explicit physical references and metric annotations are removed; instead, contextual objects such as plates and utensils are provided, requiring algorithms to infer scale from implicit cues and prior knowledge. The dataset emphasizes multi-food scenes with diverse object geometries, frequent occlusions, and complex spatial arrangements. The benchmark was adopted as a challenge at the MetaFood 2025 Workshop, where multiple teams proposed reconstruction-based solutions. Experimental results show that while strong vision--language baselines achieve competitive performance, geometry-based reconstruction methods provide both improved accuracy and greater robustness, with the top-performing approach achieving 0.21 MAPE in volume estimation and 5.7 L1 Chamfer Distance in geometric accuracy.
Size Matters: Reconstructing Real-Scale 3D Models from Monocular Images for Food Portion Estimation
Jan 27, 2026The rise of chronic diseases related to diet, such as obesity and diabetes, emphasizes the need for accurate monitoring of food intake. While AI-driven dietary assessment has made strides in recent years, the ill-posed nature of recovering size (portion) information from monocular images for accurate estimation of ``how much did you eat?'' is a pressing challenge. Some 3D reconstruction methods have achieved impressive geometric reconstruction but fail to recover the crucial real-world scale of the reconstructed object, limiting its usage in precision nutrition. In this paper, we bridge the gap between 3D computer vision and digital health by proposing a method that recovers a true-to-scale 3D reconstructed object from a monocular image. Our approach leverages rich visual features extracted from models trained on large-scale datasets to estimate the scale of the reconstructed object. This learned scale enables us to convert single-view 3D reconstructions into true-to-life, physically meaningful models. Extensive experiments and ablation studies on two publicly available datasets show that our method consistently outperforms existing techniques, achieving nearly a 30% reduction in mean absolute volume-estimation error, showcasing its potential to enhance the domain of precision nutrition. Code: https://gitlab.com/viper-purdue/size-matters
Food Image Generation on Multi-Noun Categories
Dec 09, 2025Generating realistic food images for categories with multiple nouns is surprisingly challenging. For instance, the prompt "egg noodle" may result in images that incorrectly contain both eggs and noodles as separate entities. Multi-noun food categories are common in real-world datasets and account for a large portion of entries in benchmarks such as UEC-256. These compound names often cause generative models to misinterpret the semantics, producing unintended ingredients or objects. This is due to insufficient multi-noun category related knowledge in the text encoder and misinterpretation of multi-noun relationships, leading to incorrect spatial layouts. To overcome these challenges, we propose FoCULR (Food Category Understanding and Layout Refinement) which incorporates food domain knowledge and introduces core concepts early in the generation process. Experimental results demonstrate that the integration of these techniques improves image generation performance in the food domain.
PANDA - Patch And Distribution-Aware Augmentation for Long-Tailed Exemplar-Free Continual Learning
Nov 12, 2025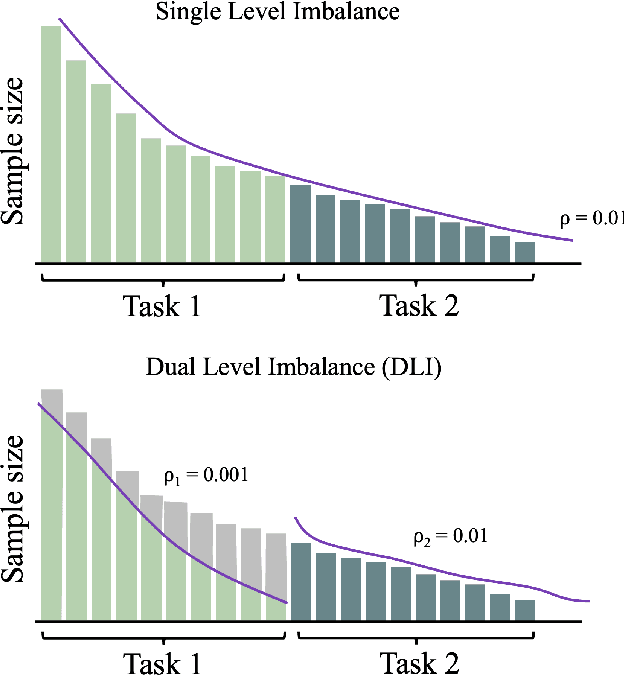
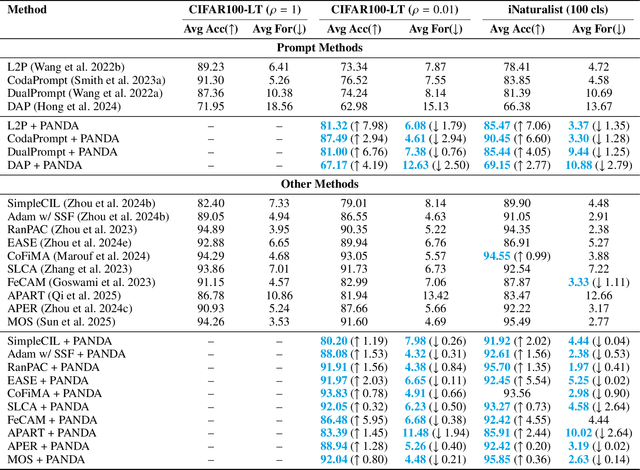
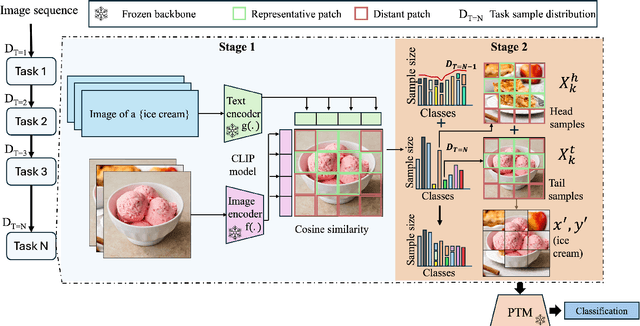
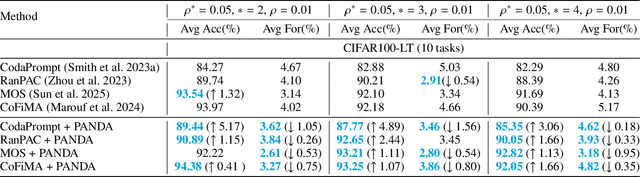
Exemplar-Free Continual Learning (EFCL) restricts the storage of previous task data and is highly susceptible to catastrophic forgetting. While pre-trained models (PTMs) are increasingly leveraged for EFCL, existing methods often overlook the inherent imbalance of real-world data distributions. We discovered that real-world data streams commonly exhibit dual-level imbalances, dataset-level distributions combined with extreme or reversed skews within individual tasks, creating both intra-task and inter-task disparities that hinder effective learning and generalization. To address these challenges, we propose PANDA, a Patch-and-Distribution-Aware Augmentation framework that integrates seamlessly with existing PTM-based EFCL methods. PANDA amplifies low-frequency classes by using a CLIP encoder to identify representative regions and transplanting those into frequent-class samples within each task. Furthermore, PANDA incorporates an adaptive balancing strategy that leverages prior task distributions to smooth inter-task imbalances, reducing the overall gap between average samples across tasks and enabling fairer learning with frozen PTMs. Extensive experiments and ablation studies demonstrate PANDA's capability to work with existing PTM-based CL methods, improving accuracy and reducing catastrophic forgetting.
Evaluating Large Multimodal Models for Nutrition Analysis: A Benchmark Enriched with Contextual Metadata
Jul 09, 2025

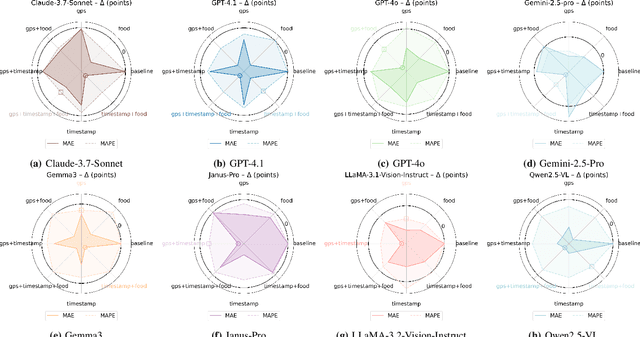
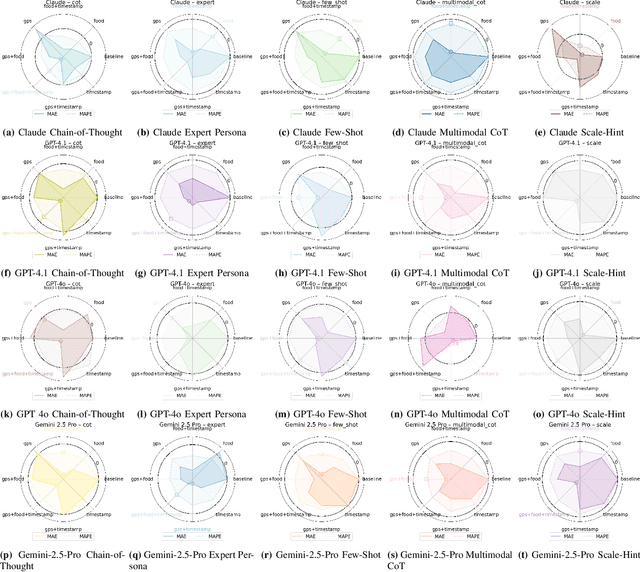
Large Multimodal Models (LMMs) are increasingly applied to meal images for nutrition analysis. However, existing work primarily evaluates proprietary models, such as GPT-4. This leaves the broad range of LLMs underexplored. Additionally, the influence of integrating contextual metadata and its interaction with various reasoning modifiers remains largely uncharted. This work investigates how interpreting contextual metadata derived from GPS coordinates (converted to location/venue type), timestamps (transformed into meal/day type), and the food items present can enhance LMM performance in estimating key nutritional values. These values include calories, macronutrients (protein, carbohydrates, fat), and portion sizes. We also introduce ACETADA, a new food-image dataset slated for public release. This open dataset provides nutrition information verified by the dietitian and serves as the foundation for our analysis. Our evaluation across eight LMMs (four open-weight and four closed-weight) first establishes the benefit of contextual metadata integration over straightforward prompting with images alone. We then demonstrate how this incorporation of contextual information enhances the efficacy of reasoning modifiers, such as Chain-of-Thought, Multimodal Chain-of-Thought, Scale Hint, Few-Shot, and Expert Persona. Empirical results show that integrating metadata intelligently, when applied through straightforward prompting strategies, can significantly reduce the Mean Absolute Error (MAE) and Mean Absolute Percentage Error (MAPE) in predicted nutritional values. This work highlights the potential of context-aware LMMs for improved nutrition analysis.
CL-LoRA: Continual Low-Rank Adaptation for Rehearsal-Free Class-Incremental Learning
May 30, 2025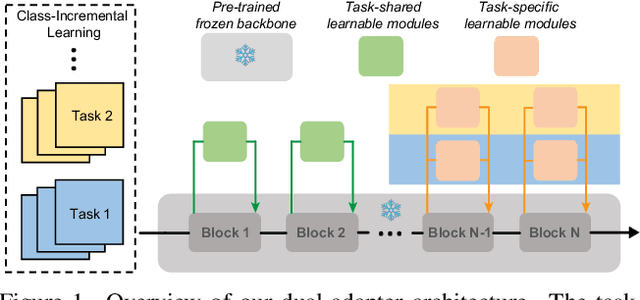
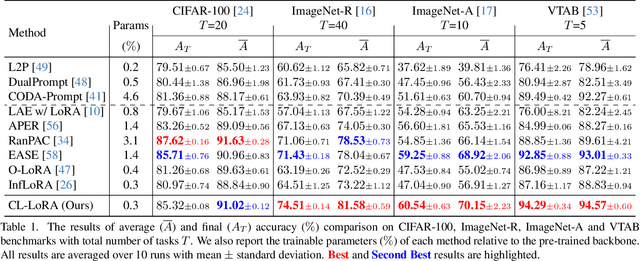
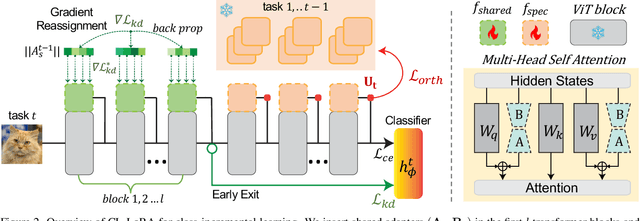
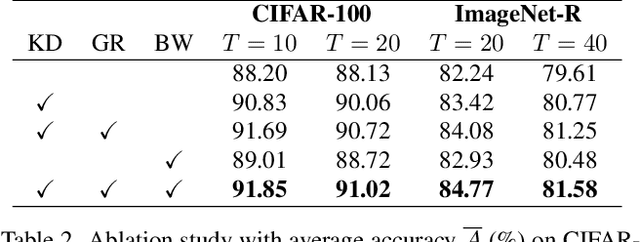
Class-Incremental Learning (CIL) aims to learn new classes sequentially while retaining the knowledge of previously learned classes. Recently, pre-trained models (PTMs) combined with parameter-efficient fine-tuning (PEFT) have shown remarkable performance in rehearsal-free CIL without requiring exemplars from previous tasks. However, existing adapter-based methods, which incorporate lightweight learnable modules into PTMs for CIL, create new adapters for each new task, leading to both parameter redundancy and failure to leverage shared knowledge across tasks. In this work, we propose ContinuaL Low-Rank Adaptation (CL-LoRA), which introduces a novel dual-adapter architecture combining \textbf{task-shared adapters} to learn cross-task knowledge and \textbf{task-specific adapters} to capture unique features of each new task. Specifically, the shared adapters utilize random orthogonal matrices and leverage knowledge distillation with gradient reassignment to preserve essential shared knowledge. In addition, we introduce learnable block-wise weights for task-specific adapters, which mitigate inter-task interference while maintaining the model's plasticity. We demonstrate CL-LoRA consistently achieves promising performance under multiple benchmarks with reduced training and inference computation, establishing a more efficient and scalable paradigm for continual learning with pre-trained models.