 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot Your Stereo-Typical Estimator: Combining Vision and Language for Volume Perception
Apr 10, 2026Accurate volume estimation of objects from visual data is a long-standing challenge in computer vision with significant applications in robotics, logistics, and smart health. Existing methods often rely on complex 3D reconstruction pipelines or struggle with the ambiguity inherent in single-view images. To address these limitations, we introduce a new method that fuses implicit 3D cues from stereo vision with explicit prior knowledge from natural language text. Our approach extracts deep features from a stereo image pair and a descriptive text prompt that contains the object's class and an approximate volume, then integrates them using a simple yet effective projection layer into a unified, multi-modal representation for regression. We conduct extensive experiments on public datasets demonstrating that our text-guided approach significantly outperforms vision-only baselines. Our findings show that leveraging even simple textual priors can effectively guide the volume estimation task, paving the way for more context-aware visual measurement systems. Code: https://gitlab.com/viper-purdue/stereo-typical-estimator.
DietDelta: A Vision-Language Approach for Dietary Assessment via Before-and-After Images
Apr 07, 2026Accurate dietary assessment is critical for precision nutrition, yet most image-based methods rely on a single pre-consumption image and provide only coarse, meal-level estimates. These approaches cannot determine what was actually consumed and often require restrictive inputs such as depth sensing, multi-view imagery, or explicit segmentation. In this paper, we propose a simple vision-language framework for food-item-level nutritional analysis using paired before-and-after eating images. Instead of relying on rigid segmentation masks, our method leverages natural language prompts to localize specific food items and estimate their weight directly from a single RGB image. We further estimate food consumption by predicting weight differences between paired images using a two-stage training strategy. We evaluate our method on three publicly available datasets and demonstrate consistent improvements over existing approaches, establishing a strong baseline for before-and-after dietary image analysis.
Can You Hear, Localize, and Segment Continually? An Exemplar-Free Continual Learning Benchmark for Audio-Visual Segmentation
Mar 09, 2026Audio-Visual Segmentation (AVS) aims to produce pixel-level masks of sound producing objects in videos, by jointly learning from audio and visual signals. However, real-world environments are inherently dynamic, causing audio and visual distributions to evolve over time, which challenge existing AVS systems that assume static training settings. To address this gap, we introduce the first exemplar-free continual learning benchmark for Audio-Visual Segmentation, comprising four learning protocols across single-source and multi-source AVS datasets. We further propose a strong baseline, ATLAS, which uses audio-guided pre-fusion conditioning to modulate visual feature channels via projected audio context before cross-modal attention. Finally, we mitigate catastrophic forgetting by introducing Low-Rank Anchoring (LRA), which stabilizes adapted weights based on loss sensitivity. Extensive experiments demonstrate competitive performance across diverse continual scenarios, establishing a foundation for lifelong audio-visual perception. Code is available at${}^{*}$\footnote{Paper under review} - \hyperlink{https://gitlab.com/viper-purdue/atlas}{https://gitlab.com/viper-purdue/atlas} \keywords{Continual Learning \and Audio-Visual Segmentation \and Multi-Modal Learning}
Implicit-Scale 3D Reconstruction for Multi-Food Volume Estimation from Monocular Images
Feb 13, 2026We present Implicit-Scale 3D Reconstruction from Monocular Multi-Food Images, a benchmark dataset designed to advance geometry-based food portion estimation in realistic dining scenarios. Existing dietary assessment methods largely rely on single-image analysis or appearance-based inference, including recent vision-language models, which lack explicit geometric reasoning and are sensitive to scale ambiguity. This benchmark reframes food portion estimation as an implicit-scale 3D reconstruction problem under monocular observations. To reflect real-world conditions, explicit physical references and metric annotations are removed; instead, contextual objects such as plates and utensils are provided, requiring algorithms to infer scale from implicit cues and prior knowledge. The dataset emphasizes multi-food scenes with diverse object geometries, frequent occlusions, and complex spatial arrangements. The benchmark was adopted as a challenge at the MetaFood 2025 Workshop, where multiple teams proposed reconstruction-based solutions. Experimental results show that while strong vision--language baselines achieve competitive performance, geometry-based reconstruction methods provide both improved accuracy and greater robustness, with the top-performing approach achieving 0.21 MAPE in volume estimation and 5.7 L1 Chamfer Distance in geometric accuracy.
Size Matters: Reconstructing Real-Scale 3D Models from Monocular Images for Food Portion Estimation
Jan 27, 2026The rise of chronic diseases related to diet, such as obesity and diabetes, emphasizes the need for accurate monitoring of food intake. While AI-driven dietary assessment has made strides in recent years, the ill-posed nature of recovering size (portion) information from monocular images for accurate estimation of ``how much did you eat?'' is a pressing challenge. Some 3D reconstruction methods have achieved impressive geometric reconstruction but fail to recover the crucial real-world scale of the reconstructed object, limiting its usage in precision nutrition. In this paper, we bridge the gap between 3D computer vision and digital health by proposing a method that recovers a true-to-scale 3D reconstructed object from a monocular image. Our approach leverages rich visual features extracted from models trained on large-scale datasets to estimate the scale of the reconstructed object. This learned scale enables us to convert single-view 3D reconstructions into true-to-life, physically meaningful models. Extensive experiments and ablation studies on two publicly available datasets show that our method consistently outperforms existing techniques, achieving nearly a 30% reduction in mean absolute volume-estimation error, showcasing its potential to enhance the domain of precision nutrition. Code: https://gitlab.com/viper-purdue/size-matters
PANDA - Patch And Distribution-Aware Augmentation for Long-Tailed Exemplar-Free Continual Learning
Nov 12, 2025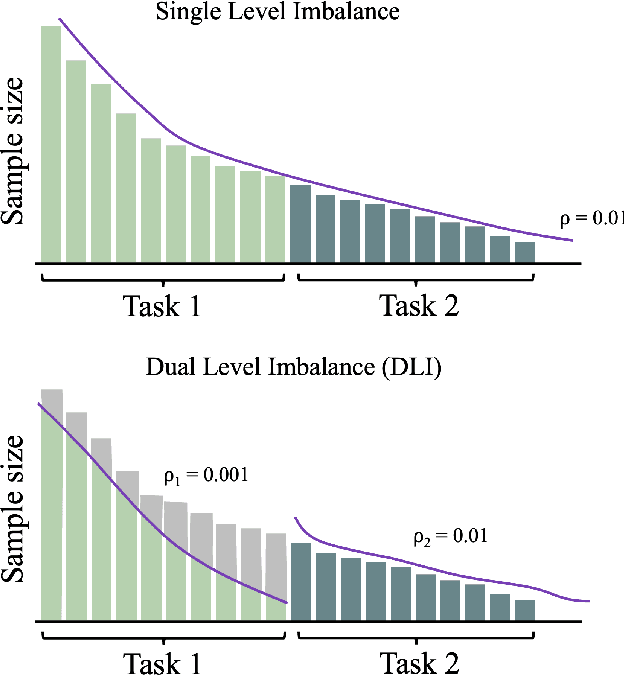
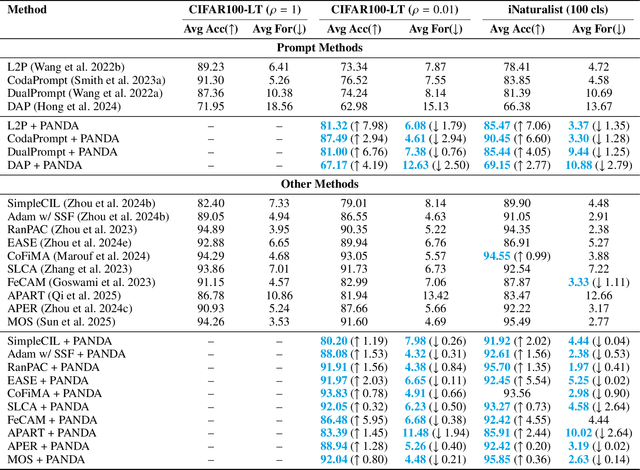
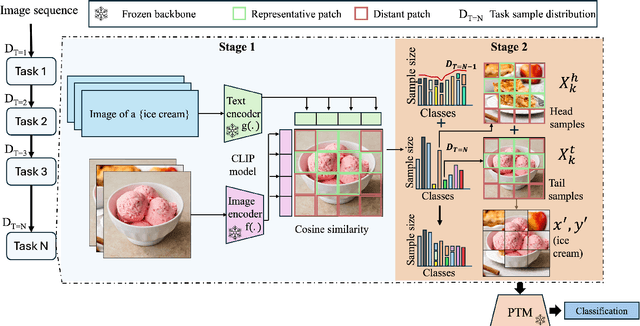
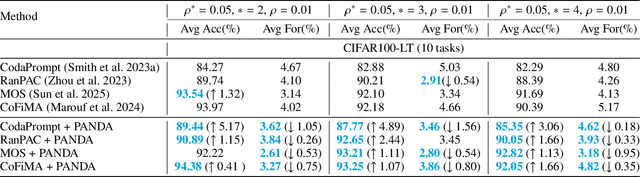
Exemplar-Free Continual Learning (EFCL) restricts the storage of previous task data and is highly susceptible to catastrophic forgetting. While pre-trained models (PTMs) are increasingly leveraged for EFCL, existing methods often overlook the inherent imbalance of real-world data distributions. We discovered that real-world data streams commonly exhibit dual-level imbalances, dataset-level distributions combined with extreme or reversed skews within individual tasks, creating both intra-task and inter-task disparities that hinder effective learning and generalization. To address these challenges, we propose PANDA, a Patch-and-Distribution-Aware Augmentation framework that integrates seamlessly with existing PTM-based EFCL methods. PANDA amplifies low-frequency classes by using a CLIP encoder to identify representative regions and transplanting those into frequent-class samples within each task. Furthermore, PANDA incorporates an adaptive balancing strategy that leverages prior task distributions to smooth inter-task imbalances, reducing the overall gap between average samples across tasks and enabling fairer learning with frozen PTMs. Extensive experiments and ablation studies demonstrate PANDA's capability to work with existing PTM-based CL methods, improving accuracy and reducing catastrophic forgetting.
MFP3D: Monocular Food Portion Estimation Leveraging 3D Point Clouds
Nov 14, 2024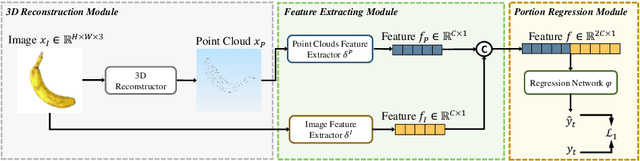
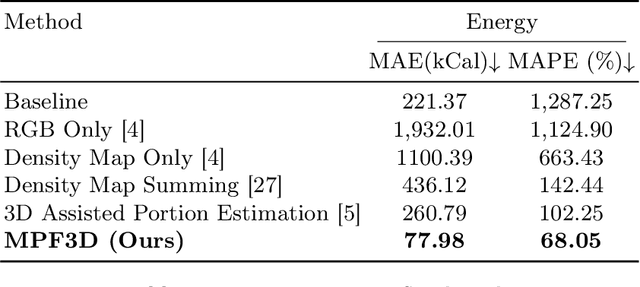
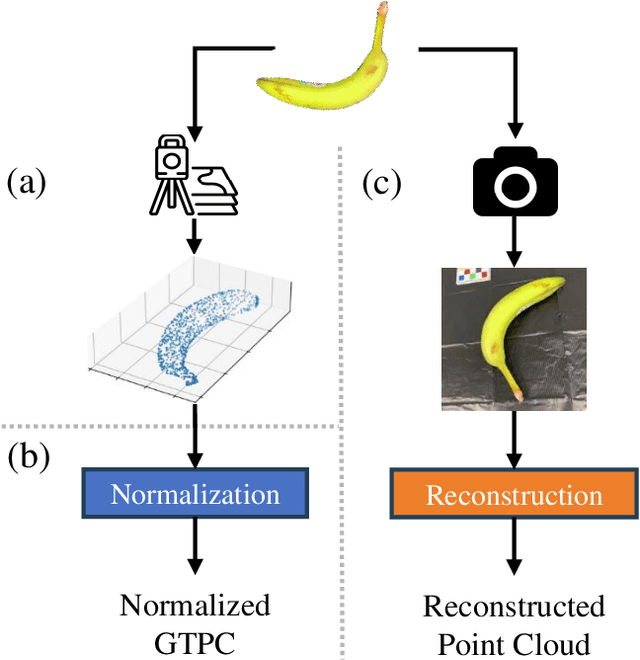
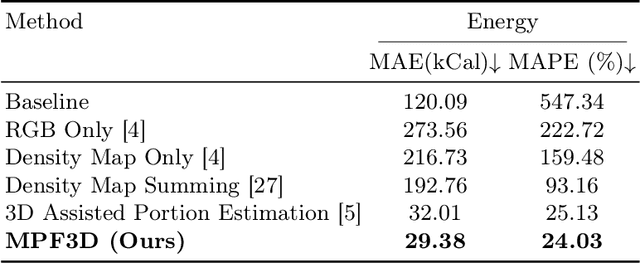
Food portion estimation is crucial for monitoring health and tracking dietary intake. Image-based dietary assessment, which involves analyzing eating occasion images using computer vision techniques, is increasingly replacing traditional methods such as 24-hour recalls. However, accurately estimating the nutritional content from images remains challenging due to the loss of 3D information when projecting to the 2D image plane. Existing portion estimation methods are challenging to deploy in real-world scenarios due to their reliance on specific requirements, such as physical reference objects, high-quality depth information, or multi-view images and videos. In this paper, we introduce MFP3D, a new framework for accurate food portion estimation using only a single monocular image. Specifically, MFP3D consists of three key modules: (1) a 3D Reconstruction Module that generates a 3D point cloud representation of the food from the 2D image, (2) a Feature Extraction Module that extracts and concatenates features from both the 3D point cloud and the 2D RGB image, and (3) a Portion Regression Module that employs a deep regression model to estimate the food's volume and energy content based on the extracted features. Our MFP3D is evaluated on MetaFood3D dataset, demonstrating its significant improvement in accurate portion estimation over existing methods.
MetaFood3D: Large 3D Food Object Dataset with Nutrition Values
Sep 03, 2024
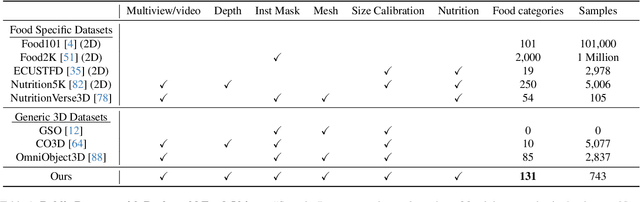
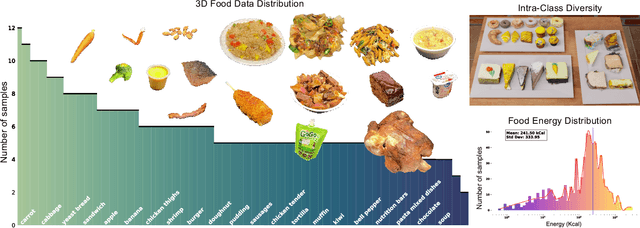
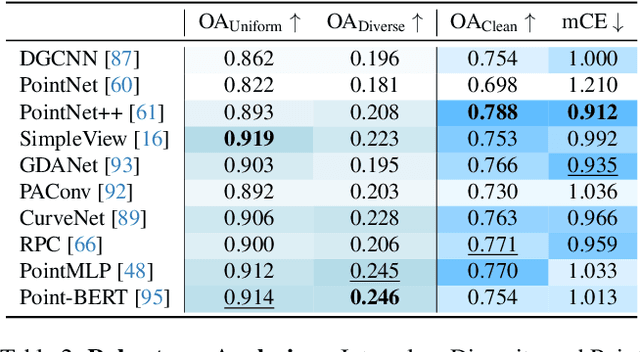
Food computing is both important and challenging in computer vision (CV). It significantly contributes to the development of CV algorithms due to its frequent presence in datasets across various applications, ranging from classification and instance segmentation to 3D reconstruction. The polymorphic shapes and textures of food, coupled with high variation in forms and vast multimodal information, including language descriptions and nutritional data, make food computing a complex and demanding task for modern CV algorithms. 3D food modeling is a new frontier for addressing food-related problems, due to its inherent capability to deal with random camera views and its straightforward representation for calculating food portion size. However, the primary hurdle in the development of algorithms for food object analysis is the lack of nutrition values in existing 3D datasets. Moreover, in the broader field of 3D research, there is a critical need for domain-specific test datasets. To bridge the gap between general 3D vision and food computing research, we propose MetaFood3D. This dataset consists of 637 meticulously labeled 3D food objects across 108 categories, featuring detailed nutrition information, weight, and food codes linked to a comprehensive nutrition database. The dataset emphasizes intra-class diversity and includes rich modalities such as textured mesh files, RGB-D videos, and segmentation masks. Experimental results demonstrate our dataset's significant potential for improving algorithm performance, highlight the challenging gap between video captures and 3D scanned data, and show the strength of the MetaFood3D dataset in high-quality data generation, simulation, and augmentation.
DELTA: Decoupling Long-Tailed Online Continual Learning
Apr 06, 2024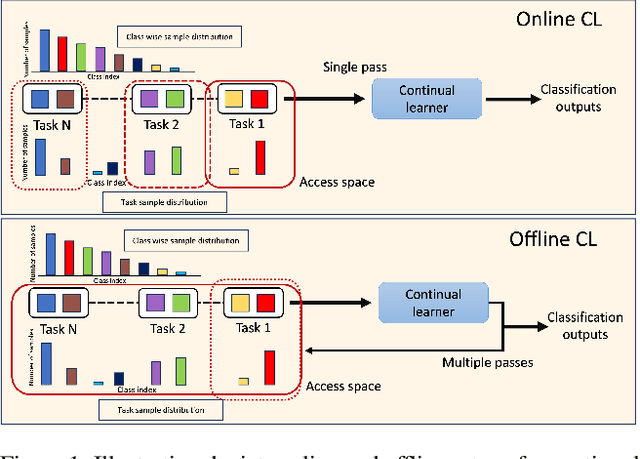

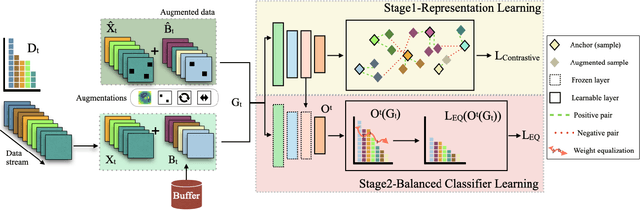
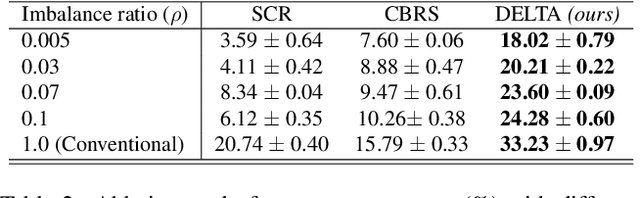
A significant challenge in achieving ubiquitous Artificial Intelligence is the limited ability of models to rapidly learn new information in real-world scenarios where data follows long-tailed distributions, all while avoiding forgetting previously acquired knowledge. In this work, we study the under-explored problem of Long-Tailed Online Continual Learning (LTOCL), which aims to learn new tasks from sequentially arriving class-imbalanced data streams. Each data is observed only once for training without knowing the task data distribution. We present DELTA, a decoupled learning approach designed to enhance learning representations and address the substantial imbalance in LTOCL. We enhance the learning process by adapting supervised contrastive learning to attract similar samples and repel dissimilar (out-of-class) samples. Further, by balancing gradients during training using an equalization loss, DELTA significantly enhances learning outcomes and successfully mitigates catastrophic forgetting. Through extensive evaluation, we demonstrate that DELTA improves the capacity for incremental learning, surpassing existing OCL methods. Our results suggest considerable promise for applying OCL in real-world applications.
Online Class-Incremental Learning For Real-World Food Classification
Jan 12, 2023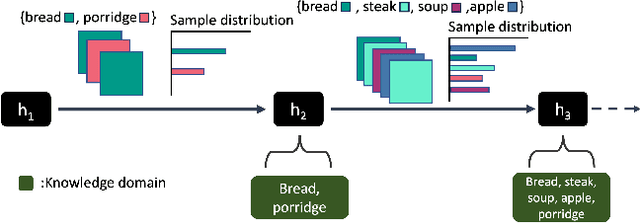
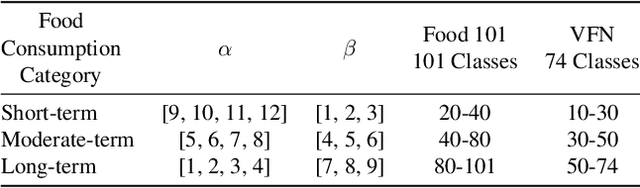
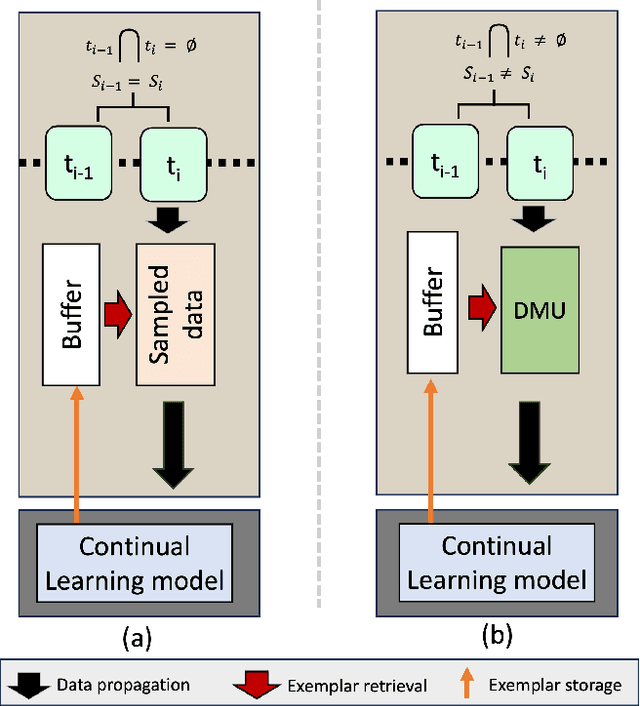
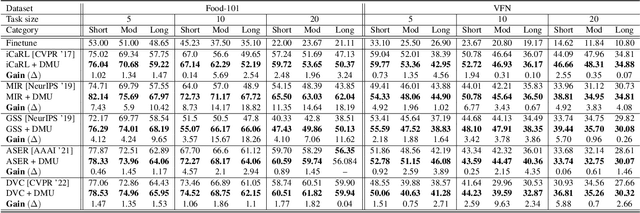
Online Class-Incremental Learning (OCIL) aims to continuously learn new information from single-pass data streams to update the model and mitigate catastrophic forgetting. However, most existing OCIL methods make several assumptions, including non-overlapped classes across phases and an equal number of classes in each learning phase. This is a highly simplified view of typical real-world scenarios. In this paper, we extend OCIL to the real-world food image classification task by removing these assumptions and significantly improving the performance of existing OCIL methods. We first introduce a novel probabilistic framework to simulate realistic food data sequences in different scenarios, including strict, moderate, and open diets, as a new benchmark experiment protocol. Next, we propose a novel plug-and-play module to dynamically select relevant images during training for the model update to improve learning and forgetting performance. Our proposed module can be incorporated into existing Experience Replay (ER) methods, which store representative samples from each class into an episodic memory buffer for knowledge rehearsal. We evaluate our method on the challenging Food-101 dataset and show substantial improvements over the current OCIL methods, demonstrating great potential for lifelong learning of real-world food image classification.