 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Imbalance of Positive and Negative Supervision in Class-Incremental Learning
Mar 02, 2026With the widespread adoption of deep learning in visual tasks, Class-Incremental Learning (CIL) has become an important paradigm for handling dynamically evolving data distributions. However, CIL faces the core challenge of catastrophic forgetting, often manifested as a prediction bias toward new classes. Existing methods mainly attribute this bias to intra-task class imbalance and focus on corrections at the classifier head. In this paper, we highlight an overlooked factor -- temporal imbalance -- as a key cause of this bias. Earlier classes receive stronger negative supervision toward the end of training, leading to asymmetric precision and recall. We establish a temporal supervision model, formally define temporal imbalance, and propose Temporal-Adjusted Loss (TAL), which uses a temporal decay kernel to construct a supervision strength vector and dynamically reweight the negative supervision in cross-entropy loss. Theoretical analysis shows that TAL degenerates to standard cross-entropy under balanced conditions and effectively mitigates prediction bias under imbalance. Extensive experiments demonstrate that TAL significantly reduces forgetting and improves performance on multiple CIL benchmarks, underscoring the importance of temporal modeling for stable long-term learning.
Implicit-Scale 3D Reconstruction for Multi-Food Volume Estimation from Monocular Images
Feb 13, 2026We present Implicit-Scale 3D Reconstruction from Monocular Multi-Food Images, a benchmark dataset designed to advance geometry-based food portion estimation in realistic dining scenarios. Existing dietary assessment methods largely rely on single-image analysis or appearance-based inference, including recent vision-language models, which lack explicit geometric reasoning and are sensitive to scale ambiguity. This benchmark reframes food portion estimation as an implicit-scale 3D reconstruction problem under monocular observations. To reflect real-world conditions, explicit physical references and metric annotations are removed; instead, contextual objects such as plates and utensils are provided, requiring algorithms to infer scale from implicit cues and prior knowledge. The dataset emphasizes multi-food scenes with diverse object geometries, frequent occlusions, and complex spatial arrangements. The benchmark was adopted as a challenge at the MetaFood 2025 Workshop, where multiple teams proposed reconstruction-based solutions. Experimental results show that while strong vision--language baselines achieve competitive performance, geometry-based reconstruction methods provide both improved accuracy and greater robustness, with the top-performing approach achieving 0.21 MAPE in volume estimation and 5.7 L1 Chamfer Distance in geometric accuracy.
Robust3D-CIL: Robust Class-Incremental Learning for 3D Perception
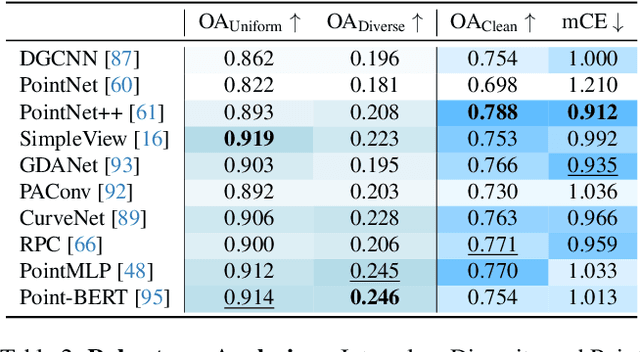
Mar 18, 20253D perception plays a crucial role in real-world applications such as autonomous driving, robotics, and AR/VR. In practical scenarios, 3D perception models must continuously adapt to new data and emerging object categories, but retraining from scratch incurs prohibitive costs. Therefore, adopting class-incremental learning (CIL) becomes particularly essential. However, real-world 3D point cloud data often include corrupted samples, which poses significant challenges for existing CIL methods and leads to more severe forgetting on corrupted data. To address these challenges, we consider the scenario in which a CIL model can be updated using point clouds with unknown corruption to better simulate real-world conditions. Inspired by Farthest Point Sampling, we propose a novel exemplar selection strategy that effectively preserves intra-class diversity when selecting replay exemplars, mitigating forgetting induced by data corruption. Furthermore, we introduce a point cloud downsampling-based replay method to utilize the limited replay buffer memory more efficiently, thereby further enhancing the model's continual learning ability. Extensive experiments demonstrate that our method improves the performance of replay-based CIL baselines by 2% to 11%, proving its effectiveness and promising potential for real-world 3D applications.
MFP3D: Monocular Food Portion Estimation Leveraging 3D Point Clouds
Nov 14, 2024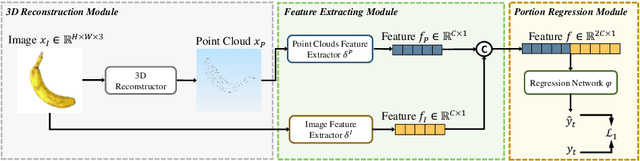
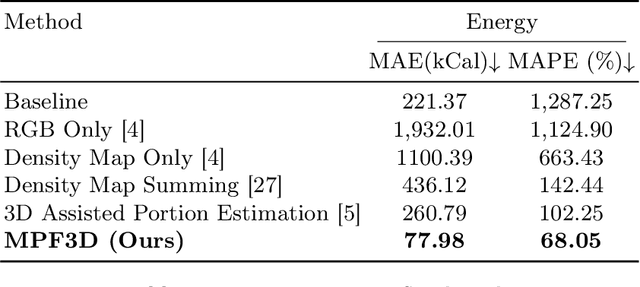
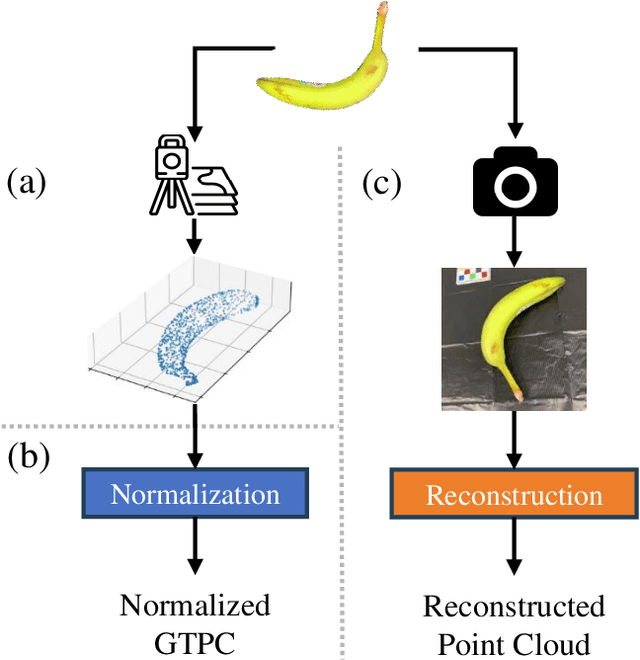
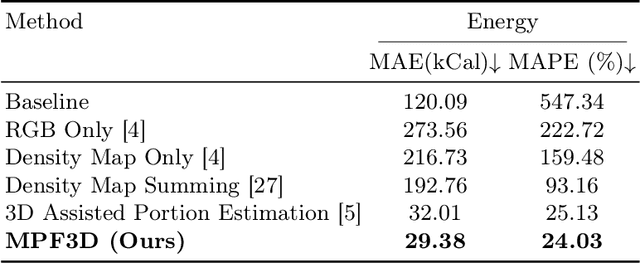
Food portion estimation is crucial for monitoring health and tracking dietary intake. Image-based dietary assessment, which involves analyzing eating occasion images using computer vision techniques, is increasingly replacing traditional methods such as 24-hour recalls. However, accurately estimating the nutritional content from images remains challenging due to the loss of 3D information when projecting to the 2D image plane. Existing portion estimation methods are challenging to deploy in real-world scenarios due to their reliance on specific requirements, such as physical reference objects, high-quality depth information, or multi-view images and videos. In this paper, we introduce MFP3D, a new framework for accurate food portion estimation using only a single monocular image. Specifically, MFP3D consists of three key modules: (1) a 3D Reconstruction Module that generates a 3D point cloud representation of the food from the 2D image, (2) a Feature Extraction Module that extracts and concatenates features from both the 3D point cloud and the 2D RGB image, and (3) a Portion Regression Module that employs a deep regression model to estimate the food's volume and energy content based on the extracted features. Our MFP3D is evaluated on MetaFood3D dataset, demonstrating its significant improvement in accurate portion estimation over existing methods.
MetaFood3D: Large 3D Food Object Dataset with Nutrition Values
Sep 03, 2024
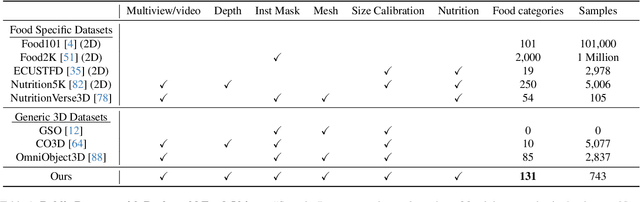
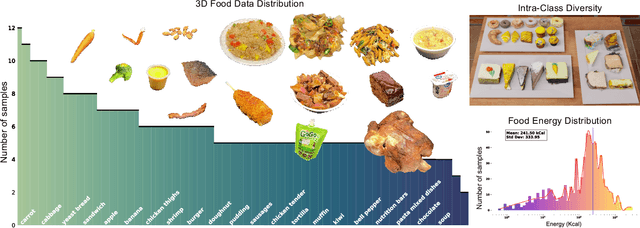
Food computing is both important and challenging in computer vision (CV). It significantly contributes to the development of CV algorithms due to its frequent presence in datasets across various applications, ranging from classification and instance segmentation to 3D reconstruction. The polymorphic shapes and textures of food, coupled with high variation in forms and vast multimodal information, including language descriptions and nutritional data, make food computing a complex and demanding task for modern CV algorithms. 3D food modeling is a new frontier for addressing food-related problems, due to its inherent capability to deal with random camera views and its straightforward representation for calculating food portion size. However, the primary hurdle in the development of algorithms for food object analysis is the lack of nutrition values in existing 3D datasets. Moreover, in the broader field of 3D research, there is a critical need for domain-specific test datasets. To bridge the gap between general 3D vision and food computing research, we propose MetaFood3D. This dataset consists of 637 meticulously labeled 3D food objects across 108 categories, featuring detailed nutrition information, weight, and food codes linked to a comprehensive nutrition database. The dataset emphasizes intra-class diversity and includes rich modalities such as textured mesh files, RGB-D videos, and segmentation masks. Experimental results demonstrate our dataset's significant potential for improving algorithm performance, highlight the challenging gap between video captures and 3D scanned data, and show the strength of the MetaFood3D dataset in high-quality data generation, simulation, and augmentation.
MASSW: A New Dataset and Benchmark Tasks for AI-Assisted Scientific Workflows
Jun 10, 2024



Scientific innovation relies on detailed workflows, which include critical steps such as analyzing literature, generating ideas, validating these ideas, interpreting results, and inspiring follow-up research. However, scientific publications that document these workflows are extensive and unstructured. This makes it difficult for both human researchers and AI systems to effectively navigate and explore the space of scientific innovation. To address this issue, we introduce MASSW, a comprehensive text dataset on Multi-Aspect Summarization of Scientific Workflows. MASSW includes more than 152,000 peer-reviewed publications from 17 leading computer science conferences spanning the past 50 years. Using Large Language Models (LLMs), we automatically extract five core aspects from these publications -- context, key idea, method, outcome, and projected impact -- which correspond to five key steps in the research workflow. These structured summaries facilitate a variety of downstream tasks and analyses. The quality of the LLM-extracted summaries is validated by comparing them with human annotations. We demonstrate the utility of MASSW through multiple novel machine-learning tasks that can be benchmarked using this new dataset, which make various types of predictions and recommendations along the scientific workflow. MASSW holds significant potential for researchers to create and benchmark new AI methods for optimizing scientific workflows and fostering scientific innovation in the field. Our dataset is openly available at \url{https://github.com/xingjian-zhang/massw}.
Strategies to Improve Real-World Applicability of Laparoscopic Anatomy Segmentation Models
Mar 25, 2024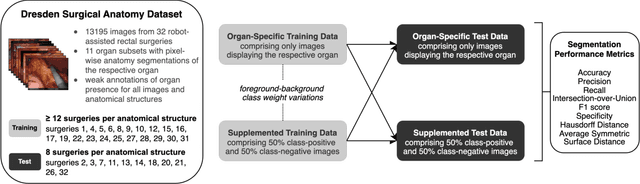


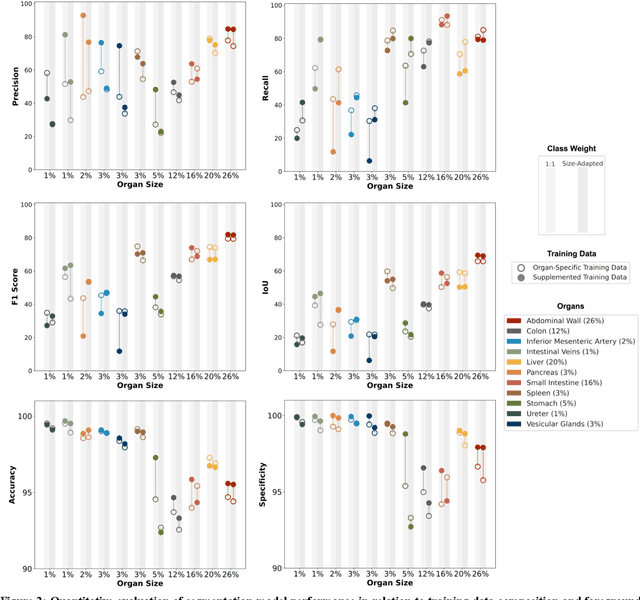
Accurate identification and localization of anatomical structures of varying size and appearance in laparoscopic imaging are necessary to leverage the potential of computer vision techniques for surgical decision support. Segmentation performance of such models is traditionally reported using metrics of overlap such as IoU. However, imbalanced and unrealistic representation of classes in the training data and suboptimal selection of reported metrics have the potential to skew nominal segmentation performance and thereby ultimately limit clinical translation. In this work, we systematically analyze the impact of class characteristics (i.e., organ size differences), training and test data composition (i.e., representation of positive and negative examples), and modeling parameters (i.e., foreground-to-background class weight) on eight segmentation metrics: accuracy, precision, recall, IoU, F1 score, specificity, Hausdorff Distance, and Average Symmetric Surface Distance. Based on our findings, we propose two simple yet effective strategies to improve real-world applicability of image segmentation models in laparoscopic surgical data: (1) inclusion of negative examples in the training process and (2) adaptation of foreground-background weights in segmentation models to maximize model performance with respect to specific metrics of interest, depending on the clinical use case.
A Prompt Log Analysis of Text-to-Image Generation Systems
Mar 16, 2023

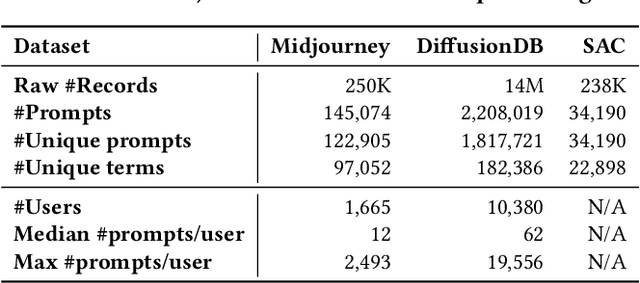

Recent developments in large language models (LLM) and generative AI have unleashed the astonishing capabilities of text-to-image generation systems to synthesize high-quality images that are faithful to a given reference text, known as a "prompt". These systems have immediately received lots of attention from researchers, creators, and common users. Despite the plenty of efforts to improve the generative models, there is limited work on understanding the information needs of the users of these systems at scale. We conduct the first comprehensive analysis of large-scale prompt logs collected from multiple text-to-image generation systems. Our work is analogous to analyzing the query logs of Web search engines, a line of work that has made critical contributions to the glory of the Web search industry and research. Compared with Web search queries, text-to-image prompts are significantly longer, often organized into special structures that consist of the subject, form, and intent of the generation tasks and present unique categories of information needs. Users make more edits within creation sessions, which present remarkable exploratory patterns. There is also a considerable gap between the user-input prompts and the captions of the images included in the open training data of the generative models. Our findings provide concrete implications on how to improve text-to-image generation systems for creation purposes.
Realization Scheme for Visual Cryptography with Computer-generated Holograms
Dec 10, 2022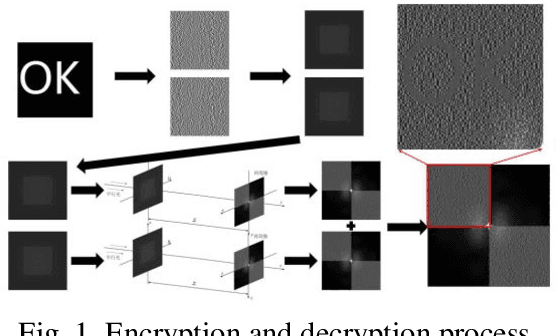

We propose to realize visual cryptography in an indirect way with the help of computer-generated hologram. At present, the recovery method of visual cryptography is mainly superimposed on transparent film or superimposed by computer equipment, which greatly limits the application range of visual cryptography. In this paper, the shares of the visual cryptography were encoded with computer-generated hologram, and the shares is reproduced by optical means, and then superimposed and decrypted. This method can expand the application range of visual cryptography and further increase the security of visual cryptography.
Face Animation with Multiple Source Images
Dec 01, 2022Face animation has received a lot of attention from researchers in recent years due to its wide range of promising applications. Many face animation models based on optical flow or deep neural networks have achieved great success. However, these models are likely to fail in animated scenarios with significant view changes, resulting in unrealistic or distorted faces. One of the possible reasons is that such models lack prior knowledge of human faces and are not proficient to imagine facial regions they have never seen before. In this paper, we propose a flexible and generic approach to improve the performance of face animation without additional training. We use multiple source images as input as compensation for the lack of prior knowledge of faces. The effectiveness of our method is experimentally demonstrated, where the proposed method successfully supplements the baseline method.