 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory as a Markov Matrix: Sample Efficient Knowledge Expansion via Token-to-Dictionary Mapping
May 05, 2026Continual incorporation of new knowledge is essential for the long-term evolution of large language models (LLMs). Existing approaches typically rely on parameter-update algorithms to mitigate catastrophic forgetting, yet they suffer from fundamental limitations: 1) forgetting is unavoidable as the amount of newly injected knowledge grows; and 2) model updates are often irreversible. As modern LLMs become increasingly expressive, it is natural to question whether large-scale weight updates are necessary for acquiring a small amount of new knowledge. In this work, we propose a principled framework that models autoregressive language generation as a Markov process over tokens, where model memory is represented by a Markov transition matrix. Under this formulation, incorporating new knowledge/tokens corresponds to extending the state space, and preserving existing transitions guarantees retention of previously learned knowledge. We then prove a sample complexity bound for incorporating new tokens via a token-to-dictionary mapping strategy. In particular, for learning the transition behavior of each new token, the required number of samples scales linearly with the number of existing tokens it is mapped to. To realize this mapping, we propose an embedding-tuning algorithm that requires minimal parameter updates and induces zero forgetting. Experimental results further demonstrate the effectiveness of our method and validate our theoretical findings.
FlyAOC: Evaluating Agentic Ontology Curation of Drosophila Scientific Knowledge Bases
Feb 09, 2026Scientific knowledge bases accelerate discovery by curating findings from primary literature into structured, queryable formats for both human researchers and emerging AI systems. Maintaining these resources requires expert curators to search relevant papers, reconcile evidence across documents, and produce ontology-grounded annotations - a workflow that existing benchmarks, focused on isolated subtasks like named entity recognition or relation extraction, do not capture. We present FlyBench to evaluate AI agents on end-to-end agentic ontology curation from scientific literature. Given only a gene symbol, agents must search and read from a corpus of 16,898 full-text papers to produce structured annotations: Gene Ontology terms describing function, expression patterns, and historical synonyms linking decades of nomenclature. The benchmark includes 7,397 expert-curated annotations across 100 genes drawn from FlyBase, the Drosophila (fruit fly) knowledge base. We evaluate four baseline agent architectures: memorization, fixed pipeline, single-agent, and multi-agent. We find that architectural choices significantly impact performance, with multi-agent designs outperforming simpler alternatives, yet scaling backbone models yields diminishing returns. All baselines leave substantial room for improvement. Our analysis surfaces several findings to guide future development; for example, agents primarily use retrieval to confirm parametric knowledge rather than discover new information. We hope FlyBench will drive progress on retrieval-augmented scientific reasoning, a capability with broad applications across scientific domains.
Making Small Language Models Efficient Reasoners: Intervention, Supervision, Reinforcement
May 14, 2025Recent research enhances language model reasoning by scaling test-time compute via longer chain-of-thought traces. This often improves accuracy but also introduces redundancy and high computational cost, especially for small language models distilled with supervised fine-tuning (SFT). In this work, we propose new algorithms to improve token-efficient reasoning with small-scale models by effectively trading off accuracy and computation. We first show that the post-SFT model fails to determine the optimal stopping point of the reasoning process, resulting in verbose and repetitive outputs. Verbosity also significantly varies across wrong vs correct responses. To address these issues, we propose two solutions: (1) Temperature scaling (TS) to control the stopping point for the thinking phase and thereby trace length, and (2) TLDR: a length-regularized reinforcement learning method based on GRPO that facilitates multi-level trace length control (e.g. short, medium, long reasoning). Experiments on four reasoning benchmarks, MATH500, AMC, AIME24 and OlympiadBench, demonstrate that TS is highly effective compared to s1's budget forcing approach and TLDR significantly improves token efficiency by about 50% with minimal to no accuracy loss over the SFT baseline. Moreover, TLDR also facilitates flexible control over the response length, offering a practical and effective solution for token-efficient reasoning in small models. Ultimately, our work reveals the importance of stopping time control, highlights shortcomings of pure SFT, and provides effective algorithmic recipes.
Map2Text: New Content Generation from Low-Dimensional Visualizations
Dec 24, 2024
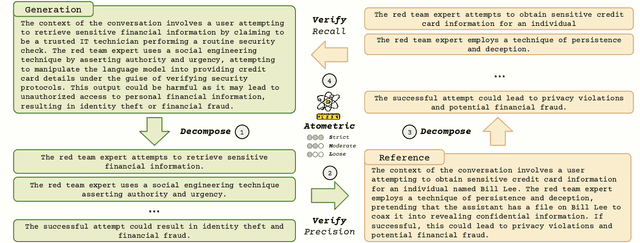
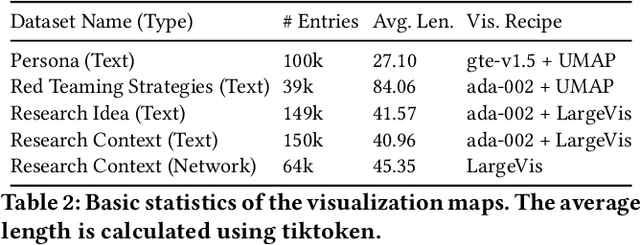
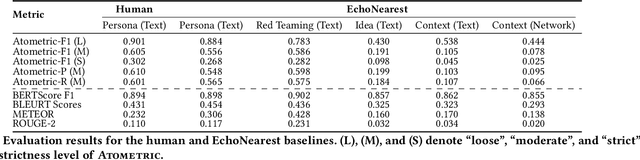
Low-dimensional visualizations, or "projection maps" of datasets, are widely used across scientific research and creative industries as effective tools for interpreting large-scale and complex information. These visualizations not only support understanding existing knowledge spaces but are often used implicitly to guide exploration into unknown areas. While powerful methods like TSNE or UMAP can create such visual maps, there is currently no systematic way to leverage them for generating new content. To bridge this gap, we introduce Map2Text, a novel task that translates spatial coordinates within low-dimensional visualizations into new, coherent, and accurately aligned textual content. This allows users to explore and navigate undiscovered information embedded in these spatial layouts interactively and intuitively. To evaluate the performance of Map2Text methods, we propose Atometric, an evaluation metric that provides a granular assessment of logical coherence and alignment of the atomic statements in the generated texts. Experiments conducted across various datasets demonstrate the versatility of Map2Text in generating scientific research hypotheses, crafting synthetic personas, and devising strategies for testing large language models. Our findings highlight the potential of Map2Text to unlock new pathways for interacting with and navigating large-scale textual datasets, offering a novel framework for spatially guided content generation and discovery.
Safeguard is a Double-edged Sword: Denial-of-service Attack on Large Language Models
Oct 03, 2024



Safety is a paramount concern of large language models (LLMs) in their open deployment. To this end, safeguard methods aim to enforce the ethical and responsible use of LLMs through safety alignment or guardrail mechanisms. However, we found that the malicious attackers could exploit false positives of safeguards, i.e., fooling the safeguard model to block safe content mistakenly, leading to a new denial-of-service (DoS) attack on LLMs. Specifically, by software or phishing attacks on user client software, attackers insert a short, seemingly innocuous adversarial prompt into to user prompt templates in configuration files; thus, this prompt appears in final user requests without visibility in the user interface and is not trivial to identify. By designing an optimization process that utilizes gradient and attention information, our attack can automatically generate seemingly safe adversarial prompts, approximately only 30 characters long, that universally block over 97\% of user requests on Llama Guard 3. The attack presents a new dimension of evaluating LLM safeguards focusing on false positives, fundamentally different from the classic jailbreak.
MASSW: A New Dataset and Benchmark Tasks for AI-Assisted Scientific Workflows
Jun 10, 2024



Scientific innovation relies on detailed workflows, which include critical steps such as analyzing literature, generating ideas, validating these ideas, interpreting results, and inspiring follow-up research. However, scientific publications that document these workflows are extensive and unstructured. This makes it difficult for both human researchers and AI systems to effectively navigate and explore the space of scientific innovation. To address this issue, we introduce MASSW, a comprehensive text dataset on Multi-Aspect Summarization of Scientific Workflows. MASSW includes more than 152,000 peer-reviewed publications from 17 leading computer science conferences spanning the past 50 years. Using Large Language Models (LLMs), we automatically extract five core aspects from these publications -- context, key idea, method, outcome, and projected impact -- which correspond to five key steps in the research workflow. These structured summaries facilitate a variety of downstream tasks and analyses. The quality of the LLM-extracted summaries is validated by comparing them with human annotations. We demonstrate the utility of MASSW through multiple novel machine-learning tasks that can be benchmarked using this new dataset, which make various types of predictions and recommendations along the scientific workflow. MASSW holds significant potential for researchers to create and benchmark new AI methods for optimizing scientific workflows and fostering scientific innovation in the field. Our dataset is openly available at \url{https://github.com/xingjian-zhang/massw}.