 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCocoon: Robust Multi-Modal Perception with Uncertainty-Aware Sensor Fusion
Oct 16, 2024
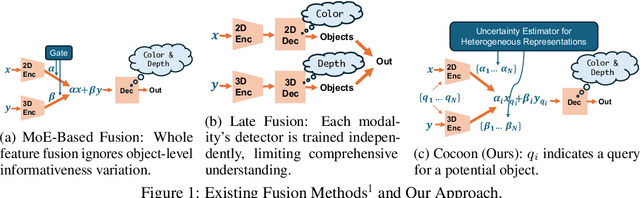
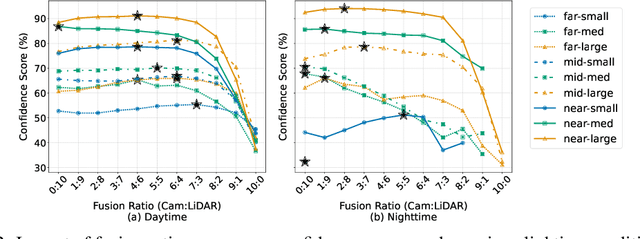
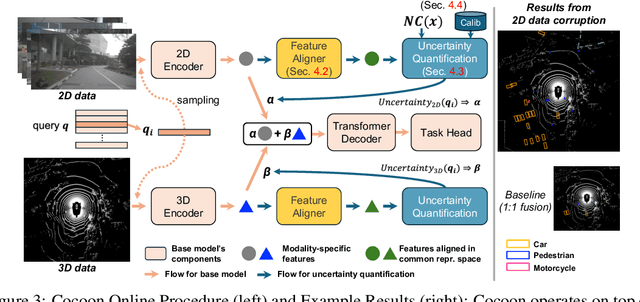
An important paradigm in 3D object detection is the use of multiple modalities to enhance accuracy in both normal and challenging conditions, particularly for long-tail scenarios. To address this, recent studies have explored two directions of adaptive approaches: MoE-based adaptive fusion, which struggles with uncertainties arising from distinct object configurations, and late fusion for output-level adaptive fusion, which relies on separate detection pipelines and limits comprehensive understanding. In this work, we introduce Cocoon, an object- and feature-level uncertainty-aware fusion framework. The key innovation lies in uncertainty quantification for heterogeneous representations, enabling fair comparison across modalities through the introduction of a feature aligner and a learnable surrogate ground truth, termed feature impression. We also define a training objective to ensure that their relationship provides a valid metric for uncertainty quantification. Cocoon consistently outperforms existing static and adaptive methods in both normal and challenging conditions, including those with natural and artificial corruptions. Furthermore, we show the validity and efficacy of our uncertainty metric across diverse datasets.
Compute Or Load KV Cache? Why Not Both?
Oct 04, 2024



Recent advancements in Large Language Models (LLMs) have significantly increased context window sizes, enabling sophisticated applications but also introducing substantial computational overheads, particularly computing key-value (KV) cache in the prefill stage. Prefix caching has emerged to save GPU power in this scenario, which saves KV cache at disks and reuse them across multiple queries. However, traditional prefix caching mechanisms often suffer from substantial latency because the speed of loading KV cache from disks to GPU memory is bottlenecked by the throughput of I/O devices. To optimize the latency of long-context prefill, we propose Cake, a novel KV cache loader, which employs a bidirectional parallelized KV cache generation strategy. Upon receiving a prefill task, Cake simultaneously and dynamically loads saved KV cache from prefix cache locations and computes KV cache on local GPUs, maximizing the utilization of available computation and I/O bandwidth resources. Additionally, Cake automatically adapts to diverse system statuses without manual parameter. tuning. In experiments on various prompt datasets, GPUs, and I/O devices, Cake offers up to 68.1% Time To First Token (TTFT) reduction compare with compute-only method and 94.6% TTFT reduction compare with I/O-only method.
Safeguard is a Double-edged Sword: Denial-of-service Attack on Large Language Models
Oct 03, 2024



Safety is a paramount concern of large language models (LLMs) in their open deployment. To this end, safeguard methods aim to enforce the ethical and responsible use of LLMs through safety alignment or guardrail mechanisms. However, we found that the malicious attackers could exploit false positives of safeguards, i.e., fooling the safeguard model to block safe content mistakenly, leading to a new denial-of-service (DoS) attack on LLMs. Specifically, by software or phishing attacks on user client software, attackers insert a short, seemingly innocuous adversarial prompt into to user prompt templates in configuration files; thus, this prompt appears in final user requests without visibility in the user interface and is not trivial to identify. By designing an optimization process that utilizes gradient and attention information, our attack can automatically generate seemingly safe adversarial prompts, approximately only 30 characters long, that universally block over 97\% of user requests on Llama Guard 3. The attack presents a new dimension of evaluating LLM safeguards focusing on false positives, fundamentally different from the classic jailbreak.
Adaptive Skeleton Graph Decoding
Feb 19, 2024



Large language models (LLMs) have seen significant adoption for natural language tasks, owing their success to massive numbers of model parameters (e.g., 70B+); however, LLM inference incurs significant computation and memory costs. Recent approaches propose parallel decoding strategies, such as Skeleton-of-Thought (SoT), to improve performance by breaking prompts down into sub-problems that can be decoded in parallel; however, they often suffer from reduced response quality. Our key insight is that we can request additional information, specifically dependencies and difficulty, when generating the sub-problems to improve both response quality and performance. In this paper, we propose Skeleton Graph Decoding (SGD), which uses dependencies exposed between sub-problems to support information forwarding between dependent sub-problems for improved quality while exposing parallelization opportunities for decoding independent sub-problems. Additionally, we leverage difficulty estimates for each sub-problem to select an appropriately-sized model, improving performance without significantly reducing quality. Compared to standard autoregressive generation and SoT, SGD achieves a 1.69x speedup while improving quality by up to 51%.
Exploring the Limits of ChatGPT in Software Security Applications
Dec 08, 2023



Large language models (LLMs) have undergone rapid evolution and achieved remarkable results in recent times. OpenAI's ChatGPT, backed by GPT-3.5 or GPT-4, has gained instant popularity due to its strong capability across a wide range of tasks, including natural language tasks, coding, mathematics, and engaging conversations. However, the impacts and limits of such LLMs in system security domain are less explored. In this paper, we delve into the limits of LLMs (i.e., ChatGPT) in seven software security applications including vulnerability detection/repair, debugging, debloating, decompilation, patching, root cause analysis, symbolic execution, and fuzzing. Our exploration reveals that ChatGPT not only excels at generating code, which is the conventional application of language models, but also demonstrates strong capability in understanding user-provided commands in natural languages, reasoning about control and data flows within programs, generating complex data structures, and even decompiling assembly code. Notably, GPT-4 showcases significant improvements over GPT-3.5 in most security tasks. Also, certain limitations of ChatGPT in security-related tasks are identified, such as its constrained ability to process long code contexts.
On Data Fabrication in Collaborative Vehicular Perception: Attacks and Countermeasures
Oct 03, 2023



Collaborative perception, which greatly enhances the sensing capability of connected and autonomous vehicles (CAVs) by incorporating data from external resources, also brings forth potential security risks. CAVs' driving decisions rely on remote untrusted data, making them susceptible to attacks carried out by malicious participants in the collaborative perception system. However, security analysis and countermeasures for such threats are absent. To understand the impact of the vulnerability, we break the ground by proposing various real-time data fabrication attacks in which the attacker delivers crafted malicious data to victims in order to perturb their perception results, leading to hard brakes or increased collision risks. Our attacks demonstrate a high success rate of over 86% on high-fidelity simulated scenarios and are realizable in real-world experiments. To mitigate the vulnerability, we present a systematic anomaly detection approach that enables benign vehicles to jointly reveal malicious fabrication. It detects 91.5% of attacks with a false positive rate of 3% in simulated scenarios and significantly mitigates attack impacts in real-world scenarios.
CALICO: Self-Supervised Camera-LiDAR Contrastive Pre-training for BEV Perception
Jun 01, 2023



Perception is crucial in the realm of autonomous driving systems, where bird's eye view (BEV)-based architectures have recently reached state-of-the-art performance. The desirability of self-supervised representation learning stems from the expensive and laborious process of annotating 2D and 3D data. Although previous research has investigated pretraining methods for both LiDAR and camera-based 3D object detection, a unified pretraining framework for multimodal BEV perception is missing. In this study, we introduce CALICO, a novel framework that applies contrastive objectives to both LiDAR and camera backbones. Specifically, CALICO incorporates two stages: point-region contrast (PRC) and region-aware distillation (RAD). PRC better balances the region- and scene-level representation learning on the LiDAR modality and offers significant performance improvement compared to existing methods. RAD effectively achieves contrastive distillation on our self-trained teacher model. CALICO's efficacy is substantiated by extensive evaluations on 3D object detection and BEV map segmentation tasks, where it delivers significant performance improvements. Notably, CALICO outperforms the baseline method by 10.5% and 8.6% on NDS and mAP. Moreover, CALICO boosts the robustness of multimodal 3D object detection against adversarial attacks and corruption. Additionally, our framework can be tailored to different backbones and heads, positioning it as a promising approach for multimodal BEV perception.
Benchmarking Robustness of 3D Point Cloud Recognition Against Common Corruptions
Jan 28, 2022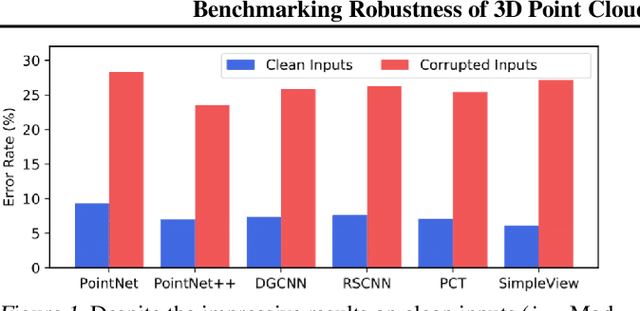
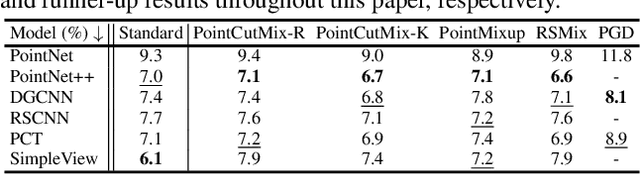
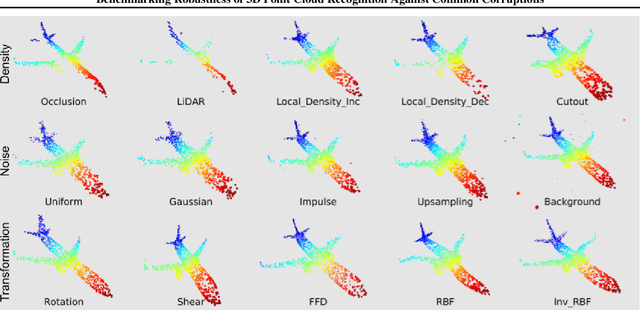

Deep neural networks on 3D point cloud data have been widely used in the real world, especially in safety-critical applications. However, their robustness against corruptions is less studied. In this paper, we present ModelNet40-C, the first comprehensive benchmark on 3D point cloud corruption robustness, consisting of 15 common and realistic corruptions. Our evaluation shows a significant gap between the performances on ModelNet40 and ModelNet40-C for state-of-the-art (SOTA) models. To reduce the gap, we propose a simple but effective method by combining PointCutMix-R and TENT after evaluating a wide range of augmentation and test-time adaptation strategies. We identify a number of critical insights for future studies on corruption robustness in point cloud recognition. For instance, we unveil that Transformer-based architectures with proper training recipes achieve the strongest robustness. We hope our in-depth analysis will motivate the development of robust training strategies or architecture designs in the 3D point cloud domain. Our codebase and dataset are included in https://github.com/jiachens/ModelNet40-C
On Adversarial Robustness of Trajectory Prediction for Autonomous Vehicles
Jan 13, 2022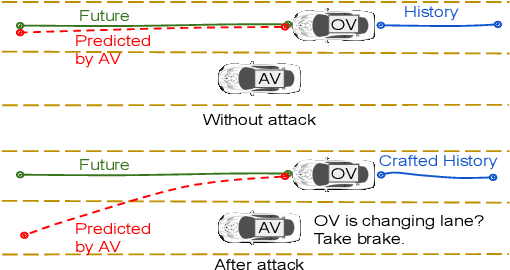
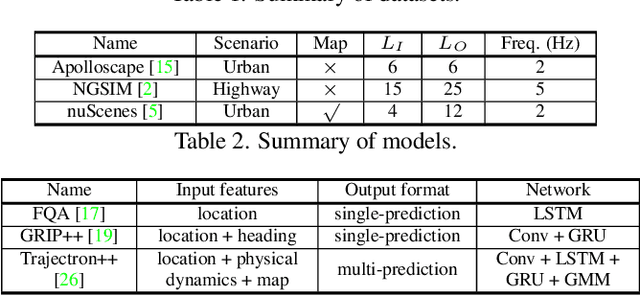
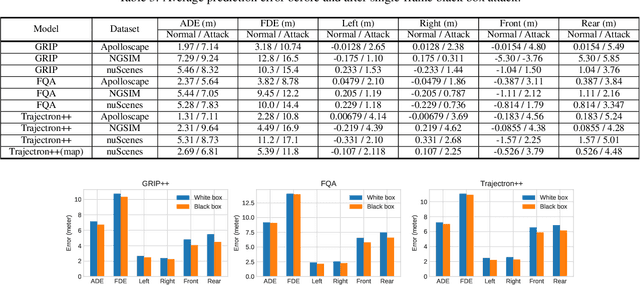
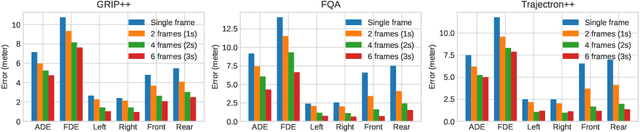
Trajectory prediction is a critical component for autonomous vehicles (AVs) to perform safe planning and navigation. However, few studies have analyzed the adversarial robustness of trajectory prediction or investigated whether the worst-case prediction can still lead to safe planning. To bridge this gap, we study the adversarial robustness of trajectory prediction models by proposing a new adversarial attack that perturbs normal vehicle trajectories to maximize the prediction error. Our experiments on three models and three datasets show that the adversarial prediction increases the prediction error by more than 150%. Our case studies show that if an adversary drives a vehicle close to the target AV following the adversarial trajectory, the AV may make an inaccurate prediction and even make unsafe driving decisions. We also explore possible mitigation techniques via data augmentation and trajectory smoothing.