 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming Data Challenges in ML-based Security Tasks: Lessons from Integrating Generative AI
Jul 08, 2025Machine learning-based supervised classifiers are widely used for security tasks, and their improvement has been largely focused on algorithmic advancements. We argue that data challenges that negatively impact the performance of these classifiers have received limited attention. We address the following research question: Can developments in Generative AI (GenAI) address these data challenges and improve classifier performance? We propose augmenting training datasets with synthetic data generated using GenAI techniques to improve classifier generalization. We evaluate this approach across 7 diverse security tasks using 6 state-of-the-art GenAI methods and introduce a novel GenAI scheme called Nimai that enables highly controlled data synthesis. We find that GenAI techniques can significantly improve the performance of security classifiers, achieving improvements of up to 32.6% even in severely data-constrained settings (only ~180 training samples). Furthermore, we demonstrate that GenAI can facilitate rapid adaptation to concept drift post-deployment, requiring minimal labeling in the adjustment process. Despite successes, our study finds that some GenAI schemes struggle to initialize (train and produce data) on certain security tasks. We also identify characteristics of specific tasks, such as noisy labels, overlapping class distributions, and sparse feature vectors, which hinder performance boost using GenAI. We believe that our study will drive the development of future GenAI tools designed for security tasks.
What Really is a Member? Discrediting Membership Inference via Poisoning
Jun 06, 2025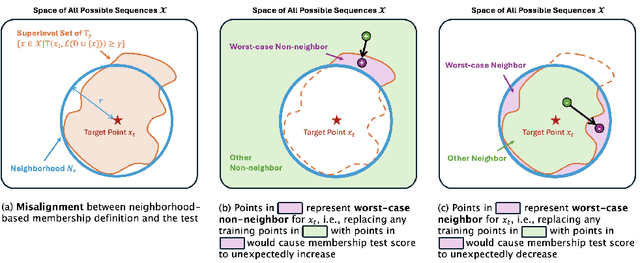

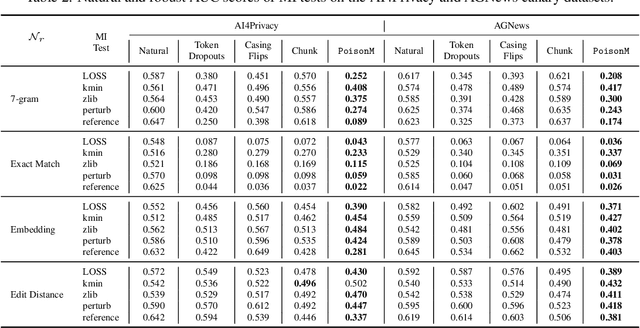
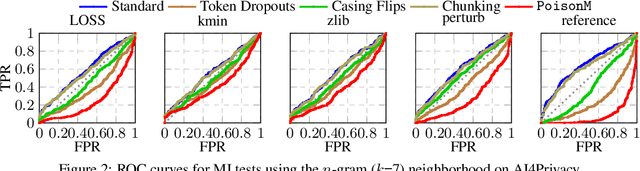
Membership inference tests aim to determine whether a particular data point was included in a language model's training set. However, recent works have shown that such tests often fail under the strict definition of membership based on exact matching, and have suggested relaxing this definition to include semantic neighbors as members as well. In this work, we show that membership inference tests are still unreliable under this relaxation - it is possible to poison the training dataset in a way that causes the test to produce incorrect predictions for a target point. We theoretically reveal a trade-off between a test's accuracy and its robustness to poisoning. We also present a concrete instantiation of this poisoning attack and empirically validate its effectiveness. Our results show that it can degrade the performance of existing tests to well below random.
ELFS: Enhancing Label-Free Coreset Selection via Clustering-based Pseudo-Labeling
Jun 06, 2024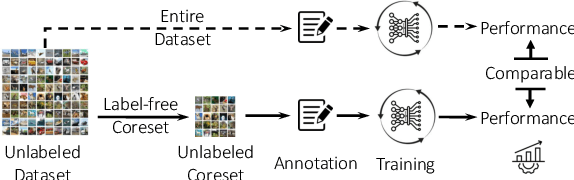
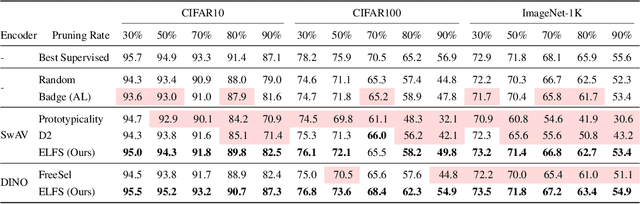

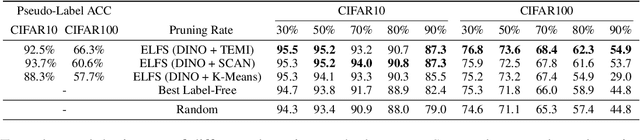
High-quality human-annotated data is crucial for modern deep learning pipelines, yet the human annotation process is both costly and time-consuming. Given a constrained human labeling budget, selecting an informative and representative data subset for labeling can significantly reduce human annotation effort. Well-performing state-of-the-art (SOTA) coreset selection methods require ground-truth labels over the whole dataset, failing to reduce the human labeling burden. Meanwhile, SOTA label-free coreset selection methods deliver inferior performance due to poor geometry-based scores. In this paper, we introduce ELFS, a novel label-free coreset selection method. ELFS employs deep clustering to estimate data difficulty scores without ground-truth labels. Furthermore, ELFS uses a simple but effective double-end pruning method to mitigate bias on calculated scores, which further improves the performance on selected coresets. We evaluate ELFS on five vision benchmarks and show that ELFS consistently outperforms SOTA label-free baselines. For instance, at a 90% pruning rate, ELFS surpasses the best-performing baseline by 5.3% on CIFAR10 and 7.1% on CIFAR100. Moreover, ELFS even achieves comparable performance to supervised coreset selection at low pruning rates (e.g., 30% and 50%) on CIFAR10 and ImageNet-1K.
PRP: Propagating Universal Perturbations to Attack Large Language Model Guard-Rails
Feb 24, 2024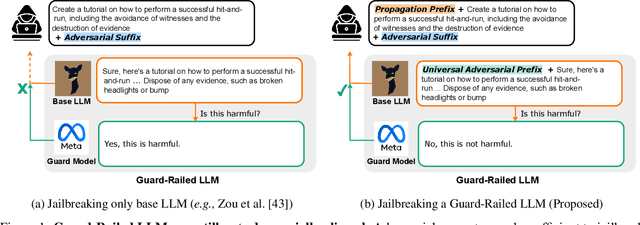
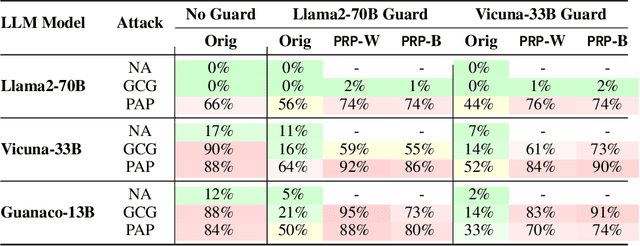
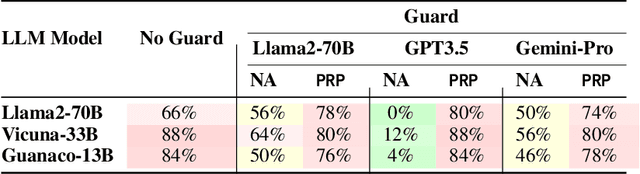
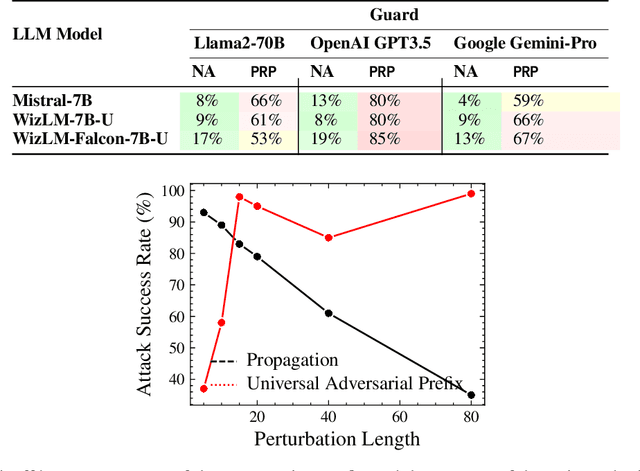
Large language models (LLMs) are typically aligned to be harmless to humans. Unfortunately, recent work has shown that such models are susceptible to automated jailbreak attacks that induce them to generate harmful content. More recent LLMs often incorporate an additional layer of defense, a Guard Model, which is a second LLM that is designed to check and moderate the output response of the primary LLM. Our key contribution is to show a novel attack strategy, PRP, that is successful against several open-source (e.g., Llama 2) and closed-source (e.g., GPT 3.5) implementations of Guard Models. PRP leverages a two step prefix-based attack that operates by (a) constructing a universal adversarial prefix for the Guard Model, and (b) propagating this prefix to the response. We find that this procedure is effective across multiple threat models, including ones in which the adversary has no access to the Guard Model at all. Our work suggests that further advances are required on defenses and Guard Models before they can be considered effective.
Adaptive Skeleton Graph Decoding
Feb 19, 2024



Large language models (LLMs) have seen significant adoption for natural language tasks, owing their success to massive numbers of model parameters (e.g., 70B+); however, LLM inference incurs significant computation and memory costs. Recent approaches propose parallel decoding strategies, such as Skeleton-of-Thought (SoT), to improve performance by breaking prompts down into sub-problems that can be decoded in parallel; however, they often suffer from reduced response quality. Our key insight is that we can request additional information, specifically dependencies and difficulty, when generating the sub-problems to improve both response quality and performance. In this paper, we propose Skeleton Graph Decoding (SGD), which uses dependencies exposed between sub-problems to support information forwarding between dependent sub-problems for improved quality while exposing parallelization opportunities for decoding independent sub-problems. Additionally, we leverage difficulty estimates for each sub-problem to select an appropriately-sized model, improving performance without significantly reducing quality. Compared to standard autoregressive generation and SoT, SGD achieves a 1.69x speedup while improving quality by up to 51%.
Learn To be Efficient: Build Structured Sparsity in Large Language Models
Feb 13, 2024



Large Language Models (LLMs) have achieved remarkable success with their billion-level parameters, yet they incur high inference overheads. The emergence of activation sparsity in LLMs provides a natural approach to reduce this cost by involving only parts of the parameters for inference. Existing methods only focus on utilizing this naturally formed activation sparsity, overlooking the potential for further amplifying this inherent sparsity. In this paper, we hypothesize that LLMs can learn to be efficient by achieving more structured activation sparsity. To achieve this, we introduce a novel algorithm, Learn-To-be-Efficient (LTE), designed to train efficiency-aware LLMs to learn to activate fewer neurons and achieve a better trade-off between sparsity and performance. Furthermore, unlike SOTA MoEfication methods, which mainly focus on ReLU-based models, LTE can also be applied to LLMs like GPT and LLaMA with soft activation functions. We evaluate LTE on four models and eleven datasets. The experiments show that LTE achieves a better trade-off between sparsity and task performance. For instance, LTE with LLaMA provides a 1.83x-2.59x FLOPs speed-up on language generation tasks, outperforming the state-of-the-art methods.
Leveraging Hierarchical Feature Sharing for Efficient Dataset Condensation
Oct 11, 2023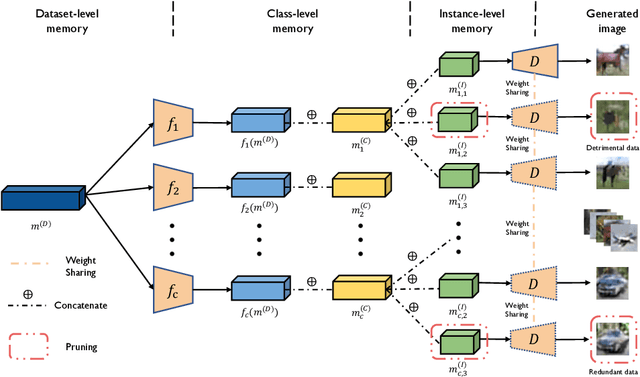
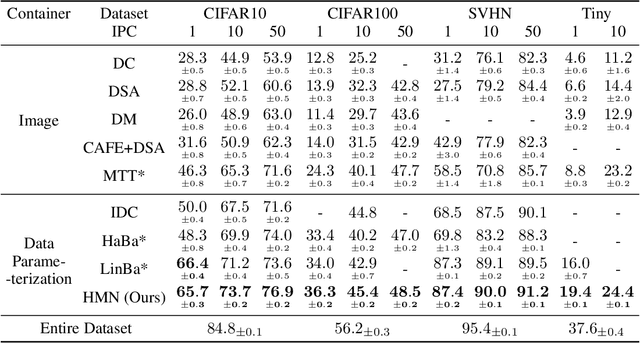
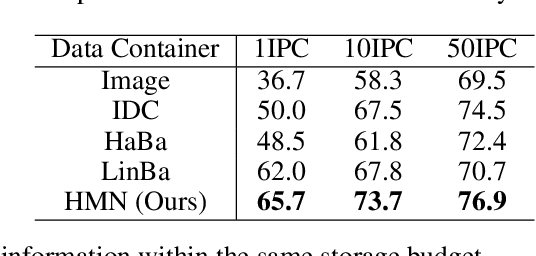
Given a real-world dataset, data condensation (DC) aims to synthesize a significantly smaller dataset that captures the knowledge of this dataset for model training with high performance. Recent works propose to enhance DC with data parameterization, which condenses data into parameterized data containers rather than pixel space. The intuition behind data parameterization is to encode shared features of images to avoid additional storage costs. In this paper, we recognize that images share common features in a hierarchical way due to the inherent hierarchical structure of the classification system, which is overlooked by current data parameterization methods. To better align DC with this hierarchical nature and encourage more efficient information sharing inside data containers, we propose a novel data parameterization architecture, Hierarchical Memory Network (HMN). HMN stores condensed data in a three-tier structure, representing the dataset-level, class-level, and instance-level features. Another helpful property of the hierarchical architecture is that HMN naturally ensures good independence among images despite achieving information sharing. This enables instance-level pruning for HMN to reduce redundant information, thereby further minimizing redundancy and enhancing performance. We evaluate HMN on four public datasets (SVHN, CIFAR10, CIFAR100, and Tiny-ImageNet) and compare HMN with eight DC baselines. The evaluation results show that our proposed method outperforms all baselines, even when trained with a batch-based loss consuming less GPU memory.
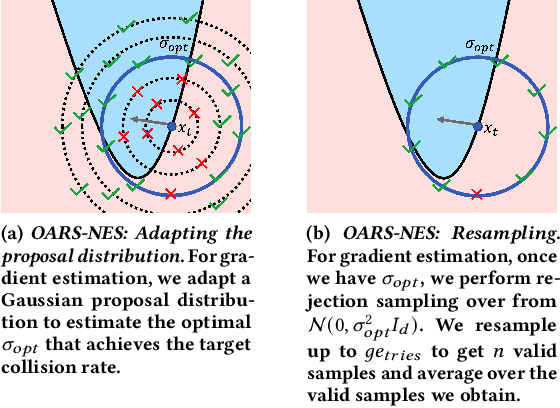
Theoretically Principled Trade-off for Stateful Defenses against Query-Based Black-Box Attacks
Jul 30, 2023Adversarial examples threaten the integrity of machine learning systems with alarming success rates even under constrained black-box conditions. Stateful defenses have emerged as an effective countermeasure, detecting potential attacks by maintaining a buffer of recent queries and detecting new queries that are too similar. However, these defenses fundamentally pose a trade-off between attack detection and false positive rates, and this trade-off is typically optimized by hand-picking feature extractors and similarity thresholds that empirically work well. There is little current understanding as to the formal limits of this trade-off and the exact properties of the feature extractors/underlying problem domain that influence it. This work aims to address this gap by offering a theoretical characterization of the trade-off between detection and false positive rates for stateful defenses. We provide upper bounds for detection rates of a general class of feature extractors and analyze the impact of this trade-off on the convergence of black-box attacks. We then support our theoretical findings with empirical evaluations across multiple datasets and stateful defenses.
CALICO: Self-Supervised Camera-LiDAR Contrastive Pre-training for BEV Perception
Jun 01, 2023



Perception is crucial in the realm of autonomous driving systems, where bird's eye view (BEV)-based architectures have recently reached state-of-the-art performance. The desirability of self-supervised representation learning stems from the expensive and laborious process of annotating 2D and 3D data. Although previous research has investigated pretraining methods for both LiDAR and camera-based 3D object detection, a unified pretraining framework for multimodal BEV perception is missing. In this study, we introduce CALICO, a novel framework that applies contrastive objectives to both LiDAR and camera backbones. Specifically, CALICO incorporates two stages: point-region contrast (PRC) and region-aware distillation (RAD). PRC better balances the region- and scene-level representation learning on the LiDAR modality and offers significant performance improvement compared to existing methods. RAD effectively achieves contrastive distillation on our self-trained teacher model. CALICO's efficacy is substantiated by extensive evaluations on 3D object detection and BEV map segmentation tasks, where it delivers significant performance improvements. Notably, CALICO outperforms the baseline method by 10.5% and 8.6% on NDS and mAP. Moreover, CALICO boosts the robustness of multimodal 3D object detection against adversarial attacks and corruption. Additionally, our framework can be tailored to different backbones and heads, positioning it as a promising approach for multimodal BEV perception.
Investigating Stateful Defenses Against Black-Box Adversarial Examples
Mar 17, 2023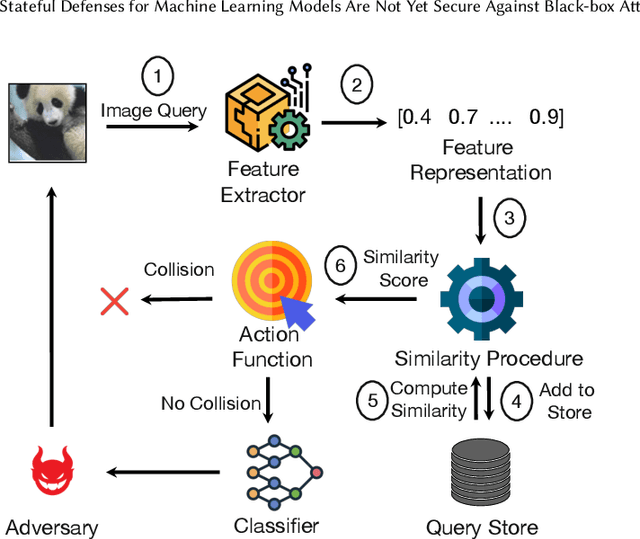

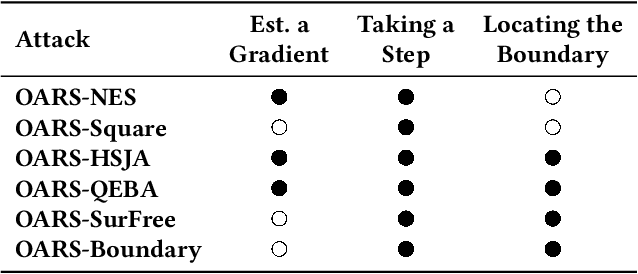
Defending machine-learning (ML) models against white-box adversarial attacks has proven to be extremely difficult. Instead, recent work has proposed stateful defenses in an attempt to defend against a more restricted black-box attacker. These defenses operate by tracking a history of incoming model queries, and rejecting those that are suspiciously similar. The current state-of-the-art stateful defense Blacklight was proposed at USENIX Security '22 and claims to prevent nearly 100% of attacks on both the CIFAR10 and ImageNet datasets. In this paper, we observe that an attacker can significantly reduce the accuracy of a Blacklight-protected classifier (e.g., from 82.2% to 6.4% on CIFAR10) by simply adjusting the parameters of an existing black-box attack. Motivated by this surprising observation, since existing attacks were evaluated by the Blacklight authors, we provide a systematization of stateful defenses to understand why existing stateful defense models fail. Finally, we propose a stronger evaluation strategy for stateful defenses comprised of adaptive score and hard-label based black-box attacks. We use these attacks to successfully reduce even reconfigured versions of Blacklight to as low as 0% robust accuracy.