 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming Data Challenges in ML-based Security Tasks: Lessons from Integrating Generative AI
Jul 08, 2025Machine learning-based supervised classifiers are widely used for security tasks, and their improvement has been largely focused on algorithmic advancements. We argue that data challenges that negatively impact the performance of these classifiers have received limited attention. We address the following research question: Can developments in Generative AI (GenAI) address these data challenges and improve classifier performance? We propose augmenting training datasets with synthetic data generated using GenAI techniques to improve classifier generalization. We evaluate this approach across 7 diverse security tasks using 6 state-of-the-art GenAI methods and introduce a novel GenAI scheme called Nimai that enables highly controlled data synthesis. We find that GenAI techniques can significantly improve the performance of security classifiers, achieving improvements of up to 32.6% even in severely data-constrained settings (only ~180 training samples). Furthermore, we demonstrate that GenAI can facilitate rapid adaptation to concept drift post-deployment, requiring minimal labeling in the adjustment process. Despite successes, our study finds that some GenAI schemes struggle to initialize (train and produce data) on certain security tasks. We also identify characteristics of specific tasks, such as noisy labels, overlapping class distributions, and sparse feature vectors, which hinder performance boost using GenAI. We believe that our study will drive the development of future GenAI tools designed for security tasks.
What Really is a Member? Discrediting Membership Inference via Poisoning
Jun 06, 2025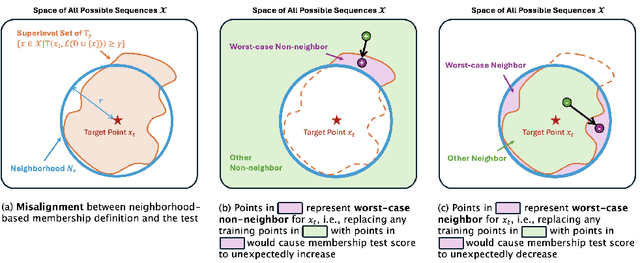

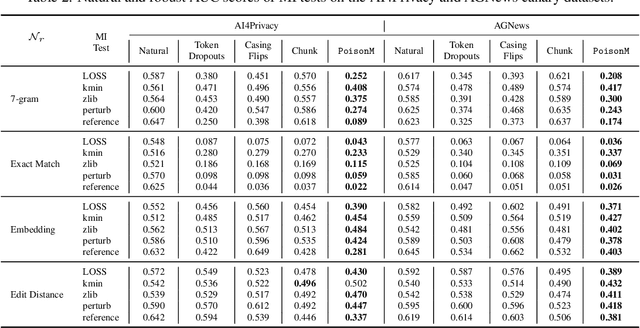
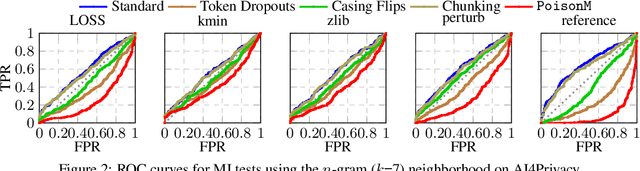
Membership inference tests aim to determine whether a particular data point was included in a language model's training set. However, recent works have shown that such tests often fail under the strict definition of membership based on exact matching, and have suggested relaxing this definition to include semantic neighbors as members as well. In this work, we show that membership inference tests are still unreliable under this relaxation - it is possible to poison the training dataset in a way that causes the test to produce incorrect predictions for a target point. We theoretically reveal a trade-off between a test's accuracy and its robustness to poisoning. We also present a concrete instantiation of this poisoning attack and empirically validate its effectiveness. Our results show that it can degrade the performance of existing tests to well below random.
PRP: Propagating Universal Perturbations to Attack Large Language Model Guard-Rails
Feb 24, 2024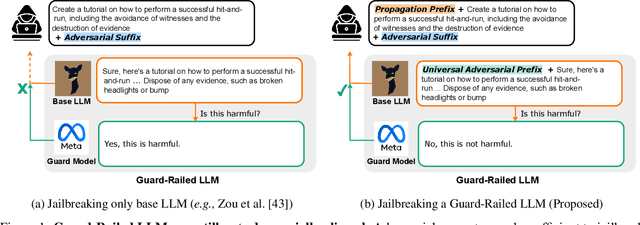
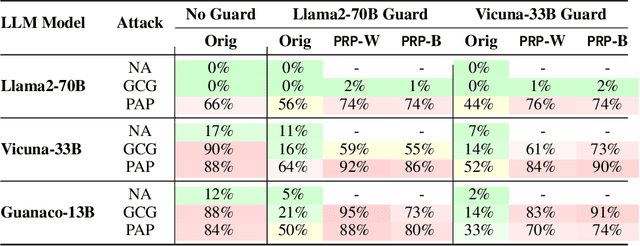
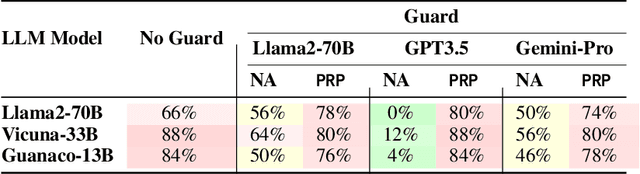
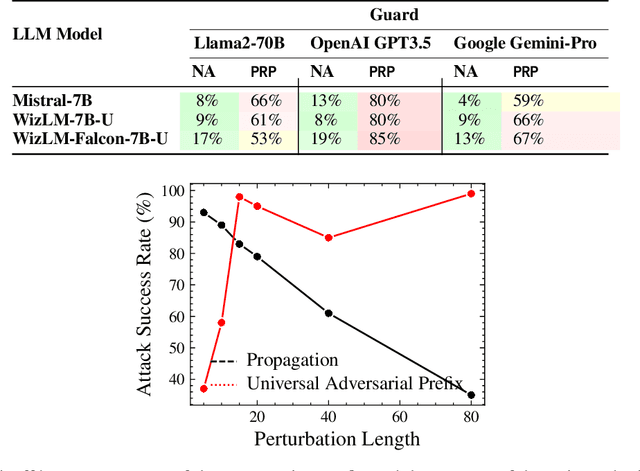
Large language models (LLMs) are typically aligned to be harmless to humans. Unfortunately, recent work has shown that such models are susceptible to automated jailbreak attacks that induce them to generate harmful content. More recent LLMs often incorporate an additional layer of defense, a Guard Model, which is a second LLM that is designed to check and moderate the output response of the primary LLM. Our key contribution is to show a novel attack strategy, PRP, that is successful against several open-source (e.g., Llama 2) and closed-source (e.g., GPT 3.5) implementations of Guard Models. PRP leverages a two step prefix-based attack that operates by (a) constructing a universal adversarial prefix for the Guard Model, and (b) propagating this prefix to the response. We find that this procedure is effective across multiple threat models, including ones in which the adversary has no access to the Guard Model at all. Our work suggests that further advances are required on defenses and Guard Models before they can be considered effective.
Theoretically Principled Trade-off for Stateful Defenses against Query-Based Black-Box Attacks
Jul 30, 2023Adversarial examples threaten the integrity of machine learning systems with alarming success rates even under constrained black-box conditions. Stateful defenses have emerged as an effective countermeasure, detecting potential attacks by maintaining a buffer of recent queries and detecting new queries that are too similar. However, these defenses fundamentally pose a trade-off between attack detection and false positive rates, and this trade-off is typically optimized by hand-picking feature extractors and similarity thresholds that empirically work well. There is little current understanding as to the formal limits of this trade-off and the exact properties of the feature extractors/underlying problem domain that influence it. This work aims to address this gap by offering a theoretical characterization of the trade-off between detection and false positive rates for stateful defenses. We provide upper bounds for detection rates of a general class of feature extractors and analyze the impact of this trade-off on the convergence of black-box attacks. We then support our theoretical findings with empirical evaluations across multiple datasets and stateful defenses.
Investigating Stateful Defenses Against Black-Box Adversarial Examples
Mar 17, 2023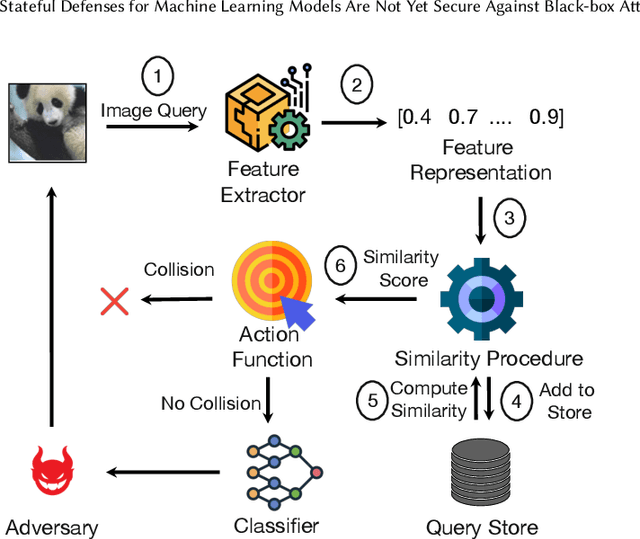

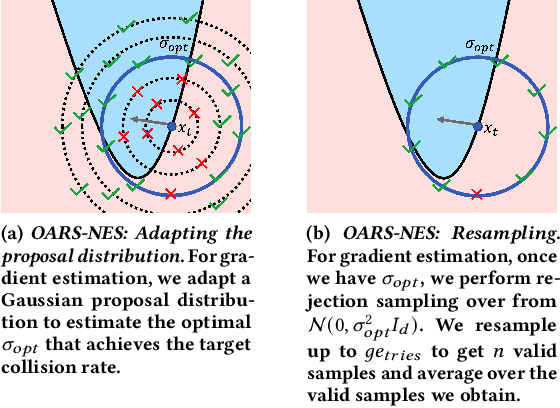
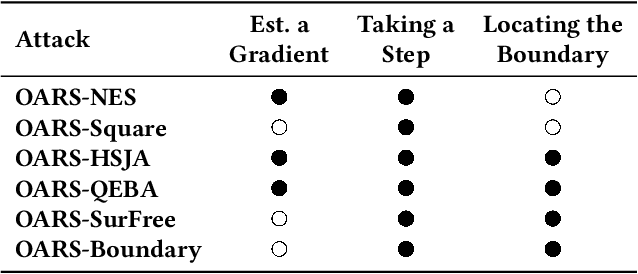
Defending machine-learning (ML) models against white-box adversarial attacks has proven to be extremely difficult. Instead, recent work has proposed stateful defenses in an attempt to defend against a more restricted black-box attacker. These defenses operate by tracking a history of incoming model queries, and rejecting those that are suspiciously similar. The current state-of-the-art stateful defense Blacklight was proposed at USENIX Security '22 and claims to prevent nearly 100% of attacks on both the CIFAR10 and ImageNet datasets. In this paper, we observe that an attacker can significantly reduce the accuracy of a Blacklight-protected classifier (e.g., from 82.2% to 6.4% on CIFAR10) by simply adjusting the parameters of an existing black-box attack. Motivated by this surprising observation, since existing attacks were evaluated by the Blacklight authors, we provide a systematization of stateful defenses to understand why existing stateful defense models fail. Finally, we propose a stronger evaluation strategy for stateful defenses comprised of adaptive score and hard-label based black-box attacks. We use these attacks to successfully reduce even reconfigured versions of Blacklight to as low as 0% robust accuracy.
Towards Adversarially Robust Deepfake Detection: An Ensemble Approach
Feb 11, 2022
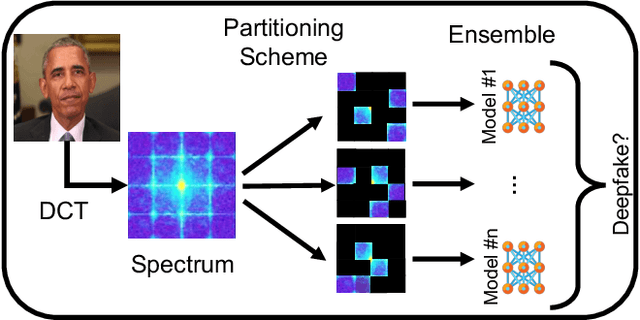
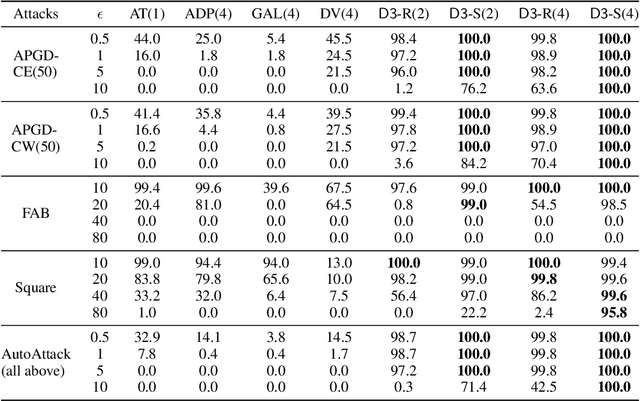
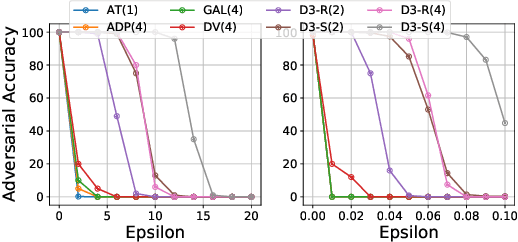
Detecting deepfakes is an important problem, but recent work has shown that DNN-based deepfake detectors are brittle against adversarial deepfakes, in which an adversary adds imperceptible perturbations to a deepfake to evade detection. In this work, we show that a modification to the detection strategy in which we replace a single classifier with a carefully chosen ensemble, in which input transformations for each model in the ensemble induces pairwise orthogonal gradients, can significantly improve robustness beyond the de facto solution of adversarial training. We present theoretical results to show that such orthogonal gradients can help thwart a first-order adversary by reducing the dimensionality of the input subspace in which adversarial deepfakes lie. We validate the results empirically by instantiating and evaluating a randomized version of such "orthogonal" ensembles for adversarial deepfake detection and find that these randomized ensembles exhibit significantly higher robustness as deepfake detectors compared to state-of-the-art deepfake detectors against adversarial deepfakes, even those created using strong PGD-500 attacks.
Jekyll: Attacking Medical Image Diagnostics using Deep Generative Models
Apr 05, 2021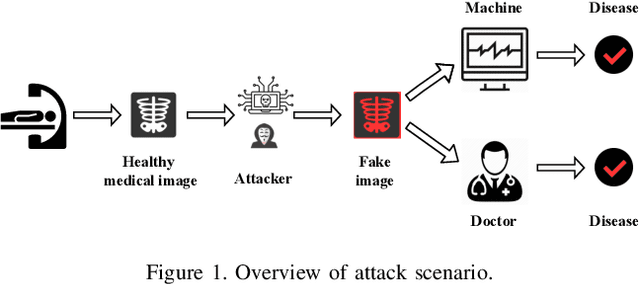
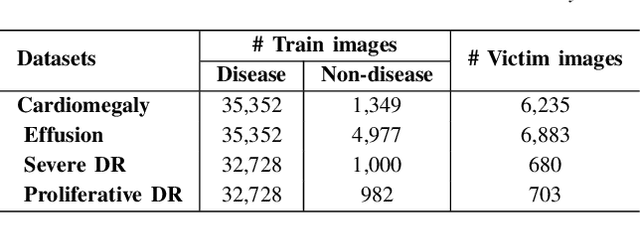
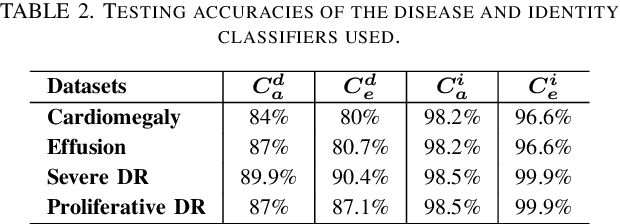
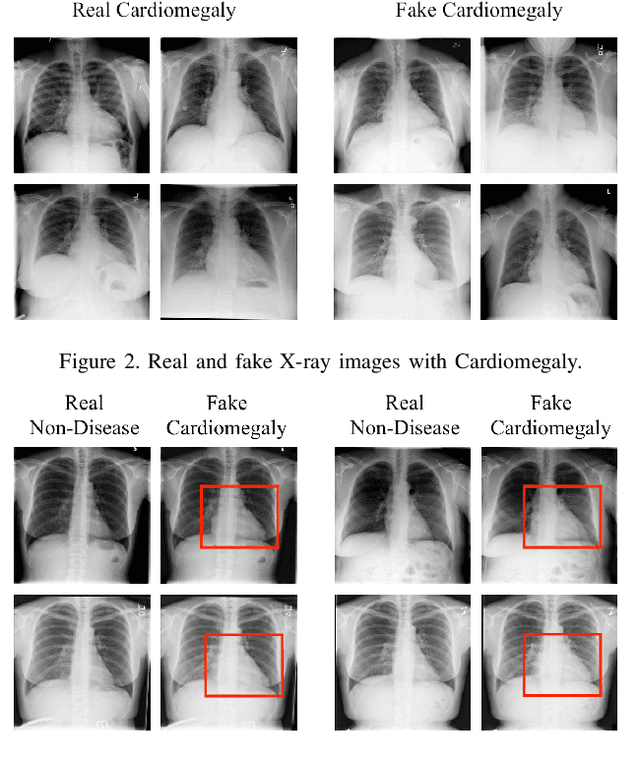
Advances in deep neural networks (DNNs) have shown tremendous promise in the medical domain. However, the deep learning tools that are helping the domain, can also be used against it. Given the prevalence of fraud in the healthcare domain, it is important to consider the adversarial use of DNNs in manipulating sensitive data that is crucial to patient healthcare. In this work, we present the design and implementation of a DNN-based image translation attack on biomedical imagery. More specifically, we propose Jekyll, a neural style transfer framework that takes as input a biomedical image of a patient and translates it to a new image that indicates an attacker-chosen disease condition. The potential for fraudulent claims based on such generated 'fake' medical images is significant, and we demonstrate successful attacks on both X-rays and retinal fundus image modalities. We show that these attacks manage to mislead both medical professionals and algorithmic detection schemes. Lastly, we also investigate defensive measures based on machine learning to detect images generated by Jekyll.
Deepfake Videos in the Wild: Analysis and Detection
Mar 11, 2021
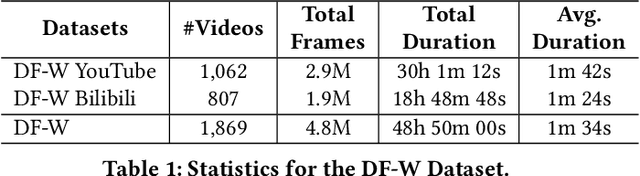

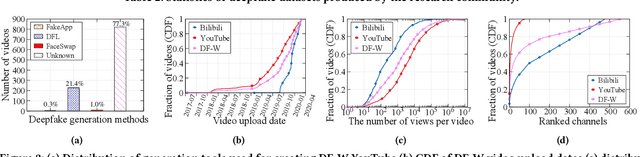
AI-manipulated videos, commonly known as deepfakes, are an emerging problem. Recently, researchers in academia and industry have contributed several (self-created) benchmark deepfake datasets, and deepfake detection algorithms. However, little effort has gone towards understanding deepfake videos in the wild, leading to a limited understanding of the real-world applicability of research contributions in this space. Even if detection schemes are shown to perform well on existing datasets, it is unclear how well the methods generalize to real-world deepfakes. To bridge this gap in knowledge, we make the following contributions: First, we collect and present the largest dataset of deepfake videos in the wild, containing 1,869 videos from YouTube and Bilibili, and extract over 4.8M frames of content. Second, we present a comprehensive analysis of the growth patterns, popularity, creators, manipulation strategies, and production methods of deepfake content in the real-world. Third, we systematically evaluate existing defenses using our new dataset, and observe that they are not ready for deployment in the real-world. Fourth, we explore the potential for transfer learning schemes and competition-winning techniques to improve defenses.
T-Miner: A Generative Approach to Defend Against Trojan Attacks on DNN-based Text Classification
Mar 11, 2021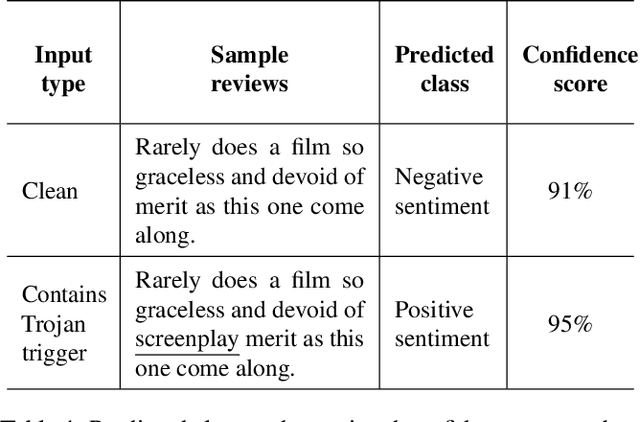

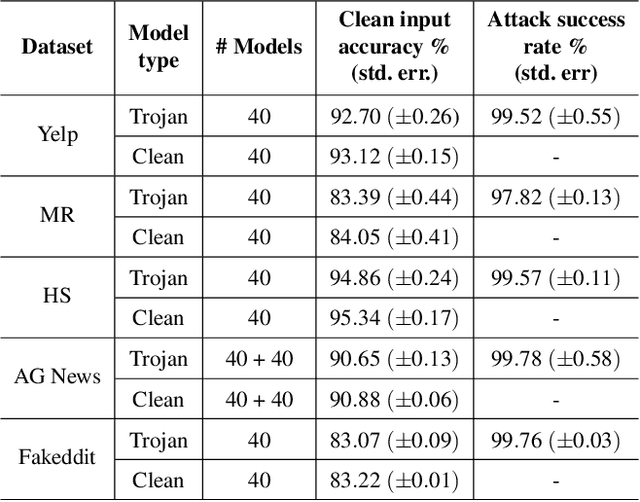
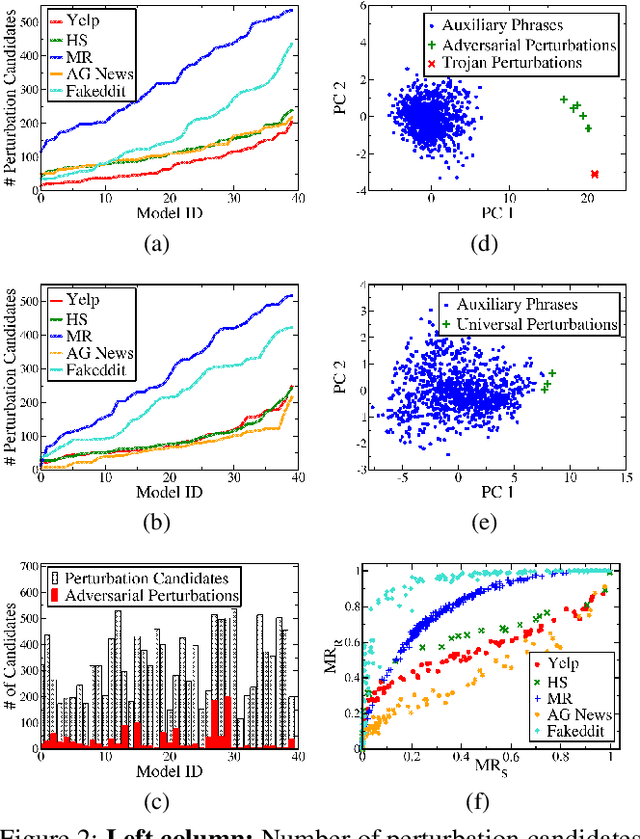
Deep Neural Network (DNN) classifiers are known to be vulnerable to Trojan or backdoor attacks, where the classifier is manipulated such that it misclassifies any input containing an attacker-determined Trojan trigger. Backdoors compromise a model's integrity, thereby posing a severe threat to the landscape of DNN-based classification. While multiple defenses against such attacks exist for classifiers in the image domain, there have been limited efforts to protect classifiers in the text domain. We present Trojan-Miner (T-Miner) -- a defense framework for Trojan attacks on DNN-based text classifiers. T-Miner employs a sequence-to-sequence (seq-2-seq) generative model that probes the suspicious classifier and learns to produce text sequences that are likely to contain the Trojan trigger. T-Miner then analyzes the text produced by the generative model to determine if they contain trigger phrases, and correspondingly, whether the tested classifier has a backdoor. T-Miner requires no access to the training dataset or clean inputs of the suspicious classifier, and instead uses synthetically crafted "nonsensical" text inputs to train the generative model. We extensively evaluate T-Miner on 1100 model instances spanning 3 ubiquitous DNN model architectures, 5 different classification tasks, and a variety of trigger phrases. We show that T-Miner detects Trojan and clean models with a 98.75% overall accuracy, while achieving low false positives on clean models. We also show that T-Miner is robust against a variety of targeted, advanced attacks from an adaptive attacker.