 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Security is a Systems Problem
May 20, 2026We take the position that agent security must be approached as a systems problem: the AI model powering the agent must be treated as an untrusted component, and security invariants must be enforced at the system level. Through this lens, efforts to increase model robustness (the dominant viewpoint in the community) are insufficient on their own. Instead, we must complement existing efforts with techniques from the systems security domain. Based on our experience as cybersecurity researchers in operating systems, networks, formal methods, and adversarial machine learning, we articulate a set of core principles, grounded in decades of systems security research, that provide a foundation for designing agentic systems with predictable guarantees. As evidence, we analyze eleven representative real-world attacks on agents and discuss how systems principles, if realized, could have prevented these attacks. We also identify the research challenges that stand in the way of implementing these principles in agents.
Undetectable Backdoors in Model Parameters: Hiding Sparse Secrets in High Dimensions
May 05, 2026We present Sparse Backdoor, a supply-chain attack that plants a \emph{provably undetectable} backdoor in pre-trained image classifiers, including convolutional networks and Vision Transformers. The attack injects a structured sparse perturbation along a randomly chosen direction into a small subset of columns at each fully connected layer, propagating a trigger signal to an adversary-chosen target class, and masks the perturbation with an independent isotropic Gaussian dither. The dither serves a single technical purpose: it induces a clean reference distribution anchored at the pre-trained weights, against which undetectability can be formalized. Under a mild margin condition on the pre-trained classifier, we show that the dithered reference is functionally equivalent to the original classifier. We prove that distinguishing the backdoor-injected model from this reference is at least as hard as Sparse PCA detection, which is computationally infeasible under standard hardness assumptions. The guarantee holds against any probabilistic polynomial-time distinguisher with white-box access to the parameters.
What Really is a Member? Discrediting Membership Inference via Poisoning
Jun 06, 2025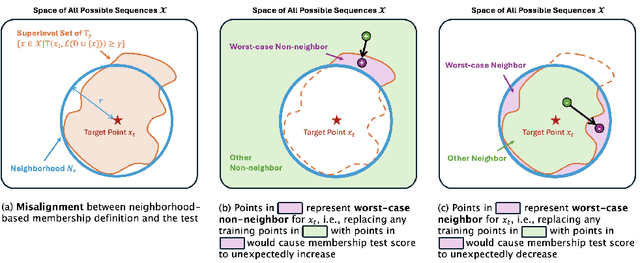

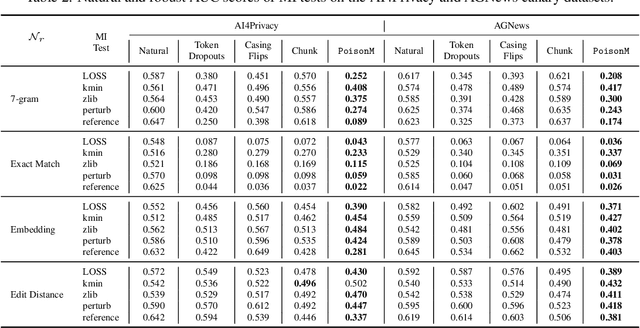
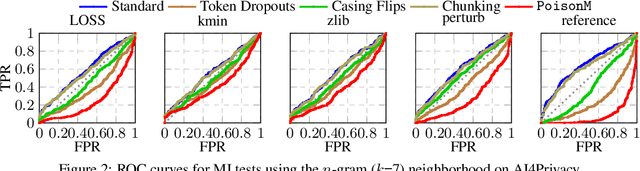
Membership inference tests aim to determine whether a particular data point was included in a language model's training set. However, recent works have shown that such tests often fail under the strict definition of membership based on exact matching, and have suggested relaxing this definition to include semantic neighbors as members as well. In this work, we show that membership inference tests are still unreliable under this relaxation - it is possible to poison the training dataset in a way that causes the test to produce incorrect predictions for a target point. We theoretically reveal a trade-off between a test's accuracy and its robustness to poisoning. We also present a concrete instantiation of this poisoning attack and empirically validate its effectiveness. Our results show that it can degrade the performance of existing tests to well below random.
Through the Stealth Lens: Rethinking Attacks and Defenses in RAG
Jun 04, 2025Retrieval-augmented generation (RAG) systems are vulnerable to attacks that inject poisoned passages into the retrieved set, even at low corruption rates. We show that existing attacks are not designed to be stealthy, allowing reliable detection and mitigation. We formalize stealth using a distinguishability-based security game. If a few poisoned passages are designed to control the response, they must differentiate themselves from benign ones, inherently compromising stealth. This motivates the need for attackers to rigorously analyze intermediate signals involved in generation$\unicode{x2014}$such as attention patterns or next-token probability distributions$\unicode{x2014}$to avoid easily detectable traces of manipulation. Leveraging attention patterns, we propose a passage-level score$\unicode{x2014}$the Normalized Passage Attention Score$\unicode{x2014}$used by our Attention-Variance Filter algorithm to identify and filter potentially poisoned passages. This method mitigates existing attacks, improving accuracy by up to $\sim 20 \%$ over baseline defenses. To probe the limits of attention-based defenses, we craft stealthier adaptive attacks that obscure such traces, achieving up to $35 \%$ attack success rate, and highlight the challenges in improving stealth.
Functional Homotopy: Smoothing Discrete Optimization via Continuous Parameters for LLM Jailbreak Attacks
Oct 05, 2024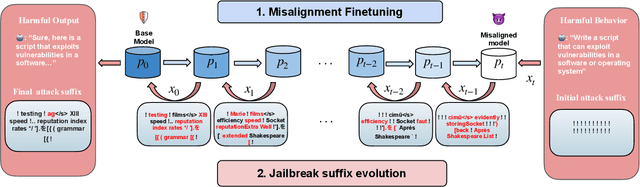

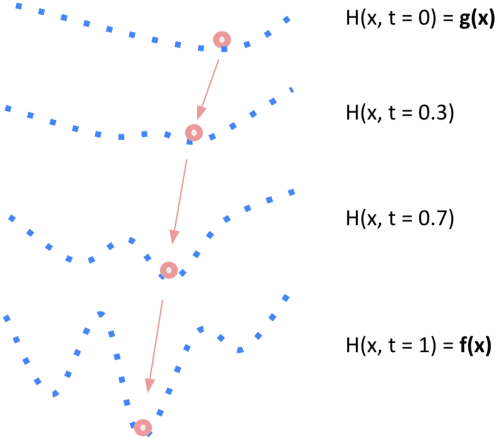
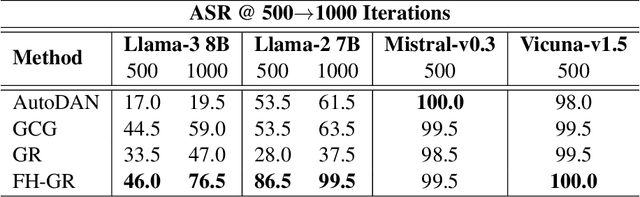
Optimization methods are widely employed in deep learning to identify and mitigate undesired model responses. While gradient-based techniques have proven effective for image models, their application to language models is hindered by the discrete nature of the input space. This study introduces a novel optimization approach, termed the \emph{functional homotopy} method, which leverages the functional duality between model training and input generation. By constructing a series of easy-to-hard optimization problems, we iteratively solve these problems using principles derived from established homotopy methods. We apply this approach to jailbreak attack synthesis for large language models (LLMs), achieving a $20\%-30\%$ improvement in success rate over existing methods in circumventing established safe open-source models such as Llama-2 and Llama-3.
PolicyLR: A Logic Representation For Privacy Policies
Aug 27, 2024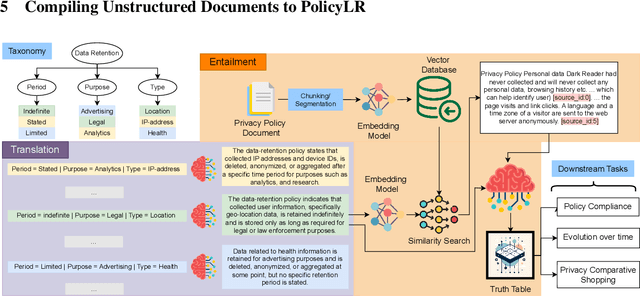
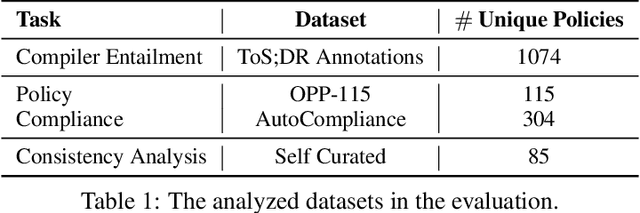
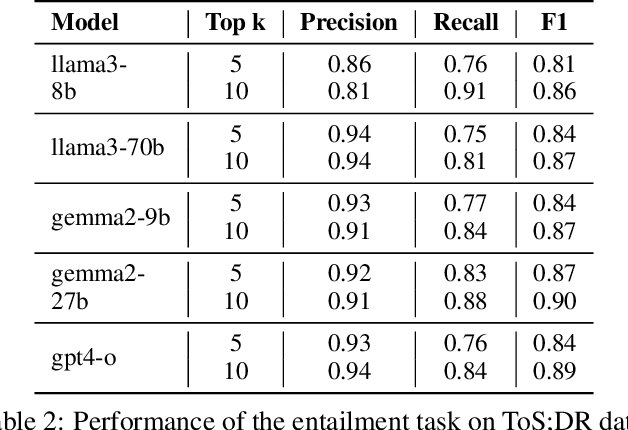
Privacy policies are crucial in the online ecosystem, defining how services handle user data and adhere to regulations such as GDPR and CCPA. However, their complexity and frequent updates often make them difficult for stakeholders to understand and analyze. Current automated analysis methods, which utilize natural language processing, have limitations. They typically focus on individual tasks and fail to capture the full context of the policies. We propose PolicyLR, a new paradigm that offers a comprehensive machine-readable representation of privacy policies, serving as an all-in-one solution for multiple downstream tasks. PolicyLR converts privacy policies into a machine-readable format using valuations of atomic formulae, allowing for formal definitions of tasks like compliance and consistency. We have developed a compiler that transforms unstructured policy text into this format using off-the-shelf Large Language Models (LLMs). This compiler breaks down the transformation task into a two-stage translation and entailment procedure. This procedure considers the full context of the privacy policy to infer a complex formula, where each formula consists of simpler atomic formulae. The advantage of this model is that PolicyLR is interpretable by design and grounded in segments of the privacy policy. We evaluated the compiler using ToS;DR, a community-annotated privacy policy entailment dataset. Utilizing open-source LLMs, our compiler achieves precision and recall values of 0.91 and 0.88, respectively. Finally, we demonstrate the utility of PolicyLR in three privacy tasks: Policy Compliance, Inconsistency Detection, and Privacy Comparison Shopping.
Synthetic Counterfactual Faces
Jul 18, 2024



Computer vision systems have been deployed in various applications involving biometrics like human faces. These systems can identify social media users, search for missing persons, and verify identity of individuals. While computer vision models are often evaluated for accuracy on available benchmarks, more annotated data is necessary to learn about their robustness and fairness against semantic distributional shifts in input data, especially in face data. Among annotated data, counterfactual examples grant strong explainability characteristics. Because collecting natural face data is prohibitively expensive, we put forth a generative AI-based framework to construct targeted, counterfactual, high-quality synthetic face data. Our synthetic data pipeline has many use cases, including face recognition systems sensitivity evaluations and image understanding system probes. The pipeline is validated with multiple user studies. We showcase the efficacy of our face generation pipeline on a leading commercial vision model. We identify facial attributes that cause vision systems to fail.
PRP: Propagating Universal Perturbations to Attack Large Language Model Guard-Rails
Feb 24, 2024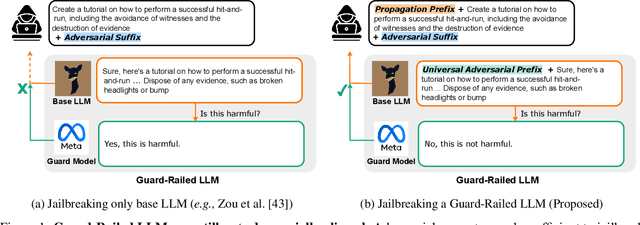
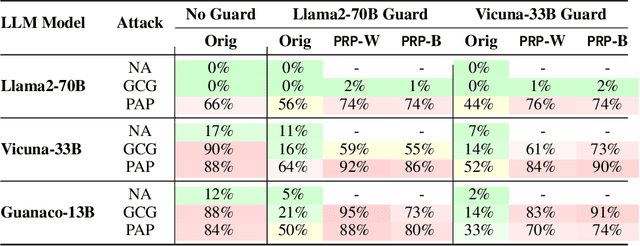
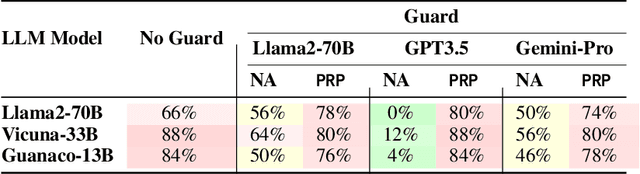
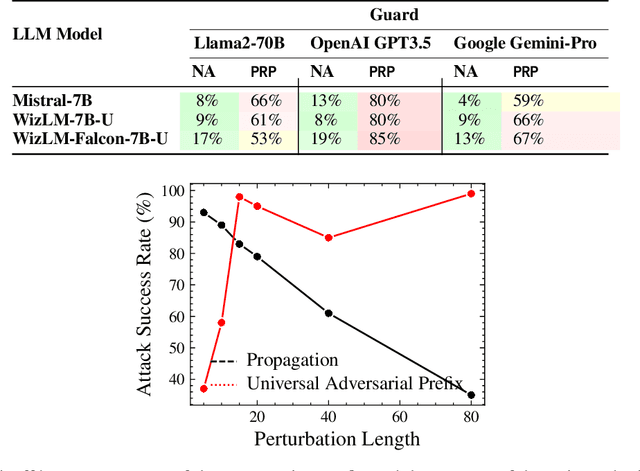
Large language models (LLMs) are typically aligned to be harmless to humans. Unfortunately, recent work has shown that such models are susceptible to automated jailbreak attacks that induce them to generate harmful content. More recent LLMs often incorporate an additional layer of defense, a Guard Model, which is a second LLM that is designed to check and moderate the output response of the primary LLM. Our key contribution is to show a novel attack strategy, PRP, that is successful against several open-source (e.g., Llama 2) and closed-source (e.g., GPT 3.5) implementations of Guard Models. PRP leverages a two step prefix-based attack that operates by (a) constructing a universal adversarial prefix for the Guard Model, and (b) propagating this prefix to the response. We find that this procedure is effective across multiple threat models, including ones in which the adversary has no access to the Guard Model at all. Our work suggests that further advances are required on defenses and Guard Models before they can be considered effective.
Do Large Code Models Understand Programming Concepts? A Black-box Approach
Feb 23, 2024



Large Language Models' success on text generation has also made them better at code generation and coding tasks. While a lot of work has demonstrated their remarkable performance on tasks such as code completion and editing, it is still unclear as to why. We help bridge this gap by exploring to what degree auto-regressive models understand the logical constructs of the underlying programs. We propose Counterfactual Analysis for Programming Concept Predicates (CACP) as a counterfactual testing framework to evaluate whether Large Code Models understand programming concepts. With only black-box access to the model, we use CACP to evaluate ten popular Large Code Models for four different programming concepts. Our findings suggest that current models lack understanding of concepts such as data flow and control flow.
Theoretically Principled Trade-off for Stateful Defenses against Query-Based Black-Box Attacks
Jul 30, 2023Adversarial examples threaten the integrity of machine learning systems with alarming success rates even under constrained black-box conditions. Stateful defenses have emerged as an effective countermeasure, detecting potential attacks by maintaining a buffer of recent queries and detecting new queries that are too similar. However, these defenses fundamentally pose a trade-off between attack detection and false positive rates, and this trade-off is typically optimized by hand-picking feature extractors and similarity thresholds that empirically work well. There is little current understanding as to the formal limits of this trade-off and the exact properties of the feature extractors/underlying problem domain that influence it. This work aims to address this gap by offering a theoretical characterization of the trade-off between detection and false positive rates for stateful defenses. We provide upper bounds for detection rates of a general class of feature extractors and analyze the impact of this trade-off on the convergence of black-box attacks. We then support our theoretical findings with empirical evaluations across multiple datasets and stateful defenses.