 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Single-Policy Sample Complexity and Transient Coverage for Average-Reward Offline RL
Jun 26, 2025We study offline reinforcement learning in average-reward MDPs, which presents increased challenges from the perspectives of distribution shift and non-uniform coverage, and has been relatively underexamined from a theoretical perspective. While previous work obtains performance guarantees under single-policy data coverage assumptions, such guarantees utilize additional complexity measures which are uniform over all policies, such as the uniform mixing time. We develop sharp guarantees depending only on the target policy, specifically the bias span and a novel policy hitting radius, yielding the first fully single-policy sample complexity bound for average-reward offline RL. We are also the first to handle general weakly communicating MDPs, contrasting restrictive structural assumptions made in prior work. To achieve this, we introduce an algorithm based on pessimistic discounted value iteration enhanced by a novel quantile clipping technique, which enables the use of a sharper empirical-span-based penalty function. Our algorithm also does not require any prior parameter knowledge for its implementation. Remarkably, we show via hard examples that learning under our conditions requires coverage assumptions beyond the stationary distribution of the target policy, distinguishing single-policy complexity measures from previously examined cases. We also develop lower bounds nearly matching our main result.
Faster Fixed-Point Methods for Multichain MDPs
Jun 26, 2025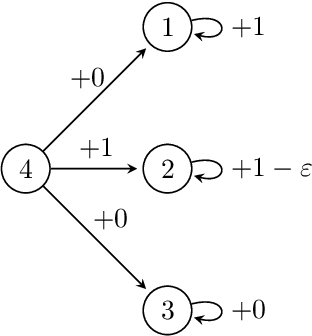
We study value-iteration (VI) algorithms for solving general (a.k.a. multichain) Markov decision processes (MDPs) under the average-reward criterion, a fundamental but theoretically challenging setting. Beyond the difficulties inherent to all average-reward problems posed by the lack of contractivity and non-uniqueness of solutions to the Bellman operator, in the multichain setting an optimal policy must solve the navigation subproblem of steering towards the best connected component, in addition to optimizing long-run performance within each component. We develop algorithms which better solve this navigational subproblem in order to achieve faster convergence for multichain MDPs, obtaining improved rates of convergence and sharper measures of complexity relative to prior work. Many key components of our results are of potential independent interest, including novel connections between average-reward and discounted problems, optimal fixed-point methods for discounted VI which extend to general Banach spaces, new sublinear convergence rates for the discounted value error, and refined suboptimality decompositions for multichain MDPs. Overall our results yield faster convergence rates for discounted and average-reward problems and expand the theoretical foundations of VI approaches.
Soft Reasoning: Navigating Solution Spaces in Large Language Models through Controlled Embedding Exploration
May 30, 2025Large Language Models (LLMs) struggle with complex reasoning due to limited diversity and inefficient search. We propose Soft Reasoning, an embedding-based search framework that optimises the embedding of the first token to guide generation. It combines (1) embedding perturbation for controlled exploration and (2) Bayesian optimisation to refine embeddings via a verifier-guided objective, balancing exploration and exploitation. This approach improves reasoning accuracy and coherence while avoiding reliance on heuristic search. Experiments demonstrate superior correctness with minimal computation, making it a scalable, model-agnostic solution.
RePaViT: Scalable Vision Transformer Acceleration via Structural Reparameterization on Feedforward Network Layers
May 28, 2025We reveal that feedforward network (FFN) layers, rather than attention layers, are the primary contributors to Vision Transformer (ViT) inference latency, with their impact signifying as model size increases. This finding highlights a critical opportunity for optimizing the efficiency of large-scale ViTs by focusing on FFN layers. In this work, we propose a novel channel idle mechanism that facilitates post-training structural reparameterization for efficient FFN layers during testing. Specifically, a set of feature channels remains idle and bypasses the nonlinear activation function in each FFN layer, thereby forming a linear pathway that enables structural reparameterization during inference. This mechanism results in a family of ReParameterizable Vision Transformers (RePaViTs), which achieve remarkable latency reductions with acceptable sacrifices (sometimes gains) in accuracy across various ViTs. The benefits of our method scale consistently with model sizes, demonstrating greater speed improvements and progressively narrowing accuracy gaps or even higher accuracies on larger models. In particular, RePa-ViT-Large and RePa-ViT-Huge enjoy 66.8% and 68.7% speed-ups with +1.7% and +1.1% higher top-1 accuracies under the same training strategy, respectively. RePaViT is the first to employ structural reparameterization on FFN layers to expedite ViTs to our best knowledge, and we believe that it represents an auspicious direction for efficient ViTs. Source code is available at https://github.com/Ackesnal/RePaViT.
A Piecewise Lyapunov Analysis of Sub-quadratic SGD: Applications to Robust and Quantile Regression
Apr 15, 2025Motivated by robust and quantile regression problems, we investigate the stochastic gradient descent (SGD) algorithm for minimizing an objective function $f$ that is locally strongly convex with a sub--quadratic tail. This setting covers many widely used online statistical methods. We introduce a novel piecewise Lyapunov function that enables us to handle functions $f$ with only first-order differentiability, which includes a wide range of popular loss functions such as Huber loss. Leveraging our proposed Lyapunov function, we derive finite-time moment bounds under general diminishing stepsizes, as well as constant stepsizes. We further establish the weak convergence, central limit theorem and bias characterization under constant stepsize, providing the first geometrical convergence result for sub--quadratic SGD. Our results have wide applications, especially in online statistical methods. In particular, we discuss two applications of our results. 1) Online robust regression: We consider a corrupted linear model with sub--exponential covariates and heavy--tailed noise. Our analysis provides convergence rates comparable to those for corrupted models with Gaussian covariates and noise. 2) Online quantile regression: Importantly, our results relax the common assumption in prior work that the conditional density is continuous and provide a more fine-grained analysis for the moment bounds.
Optimally Installing Strict Equilibria
Mar 05, 2025In this work, we develop a reward design framework for installing a desired behavior as a strict equilibrium across standard solution concepts: dominant strategy equilibrium, Nash equilibrium, correlated equilibrium, and coarse correlated equilibrium. We also extend our framework to capture the Markov-perfect equivalents of each solution concept. Central to our framework is a comprehensive mathematical characterization of strictly installable, based on the desired solution concept and the behavior's structure. These characterizations lead to efficient iterative algorithms, which we generalize to handle optimization objectives through linear programming. Finally, we explore how our results generalize to bounded rational agents.
Re-examining Double Descent and Scaling Laws under Norm-based Capacity via Deterministic Equivalence
Feb 03, 2025



We investigate double descent and scaling laws in terms of weights rather than the number of parameters. Specifically, we analyze linear and random features models using the deterministic equivalence approach from random matrix theory. We precisely characterize how the weights norm concentrate around deterministic quantities and elucidate the relationship between the expected test error and the norm-based capacity (complexity). Our results rigorously answer whether double descent exists under norm-based capacity and reshape the corresponding scaling laws. Moreover, they prompt a rethinking of the data-parameter paradigm - from under-parameterized to over-parameterized regimes - by shifting the focus to norms (weights) rather than parameter count.
One-step full gradient suffices for low-rank fine-tuning, provably and efficiently
Feb 03, 2025



This paper studies how to improve the performance of Low-Rank Adaption (LoRA) as guided by our theoretical analysis. Our first set of theoretical results show that for random initialization and linear models, \textit{i)} LoRA will align to the certain singular subspace of one-step gradient of full fine-tuning; \textit{ii)} preconditioners improve convergence in the high-rank case. These insights motivate us to focus on preconditioned LoRA using a specific spectral initialization strategy for aligning with certain subspaces. For both linear and nonlinear models, we prove that alignment and generalization guarantees can be directly achieved at initialization, and the subsequent linear convergence can be also built. Our analysis leads to the \emph{LoRA-One} algorithm (using \emph{One}-step gradient and preconditioning), a theoretically grounded algorithm that achieves significant empirical improvement over vanilla LoRA and its variants on several benchmarks. Our theoretical analysis, based on decoupling the learning dynamics and characterizing how spectral initialization contributes to feature learning, may be of independent interest for understanding matrix sensing and deep learning theory. The source code can be found in the https://github.com/YuanheZ/LoRA-One.
The Limits of Transfer Reinforcement Learning with Latent Low-rank Structure
Oct 28, 2024Many reinforcement learning (RL) algorithms are too costly to use in practice due to the large sizes $S, A$ of the problem's state and action space. To resolve this issue, we study transfer RL with latent low rank structure. We consider the problem of transferring a latent low rank representation when the source and target MDPs have transition kernels with Tucker rank $(S , d, A )$, $(S , S , d), (d, S, A )$, or $(d , d , d )$. In each setting, we introduce the transfer-ability coefficient $\alpha$ that measures the difficulty of representational transfer. Our algorithm learns latent representations in each source MDP and then exploits the linear structure to remove the dependence on $S, A $, or $S A$ in the target MDP regret bound. We complement our positive results with information theoretic lower bounds that show our algorithms (excluding the ($d, d, d$) setting) are minimax-optimal with respect to $\alpha$.
Two-Timescale Linear Stochastic Approximation: Constant Stepsizes Go a Long Way
Oct 16, 2024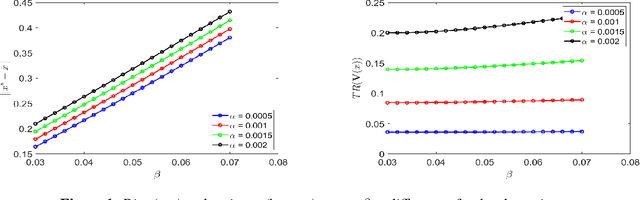
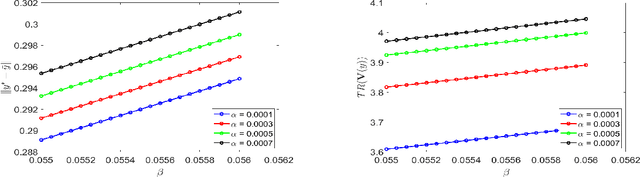
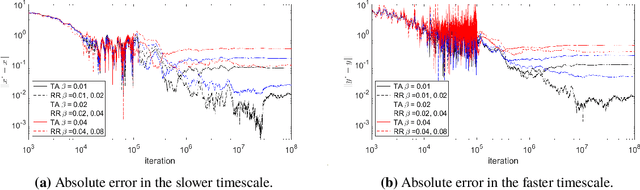
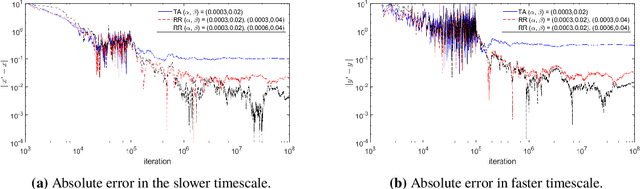
Previous studies on two-timescale stochastic approximation (SA) mainly focused on bounding mean-squared errors under diminishing stepsize schemes. In this work, we investigate {\it constant} stpesize schemes through the lens of Markov processes, proving that the iterates of both timescales converge to a unique joint stationary distribution in Wasserstein metric. We derive explicit geometric and non-asymptotic convergence rates, as well as the variance and bias introduced by constant stepsizes in the presence of Markovian noise. Specifically, with two constant stepsizes $\alpha < \beta$, we show that the biases scale linearly with both stepsizes as $\Theta(\alpha)+\Theta(\beta)$ up to higher-order terms, while the variance of the slower iterate (resp., faster iterate) scales only with its own stepsize as $O(\alpha)$ (resp., $O(\beta)$). Unlike previous work, our results require no additional assumptions such as $\beta^2 \ll \alpha$ nor extra dependence on dimensions. These fine-grained characterizations allow tail-averaging and extrapolation techniques to reduce variance and bias, improving mean-squared error bound to $O(\beta^4 + \frac{1}{t})$ for both iterates.