 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Peril of (Even a Little) Nonstationarity in Satisficing Regret Minimization
Mar 19, 2026Motivated by the principle of satisficing in decision-making, we study satisficing regret guarantees for nonstationary $K$-armed bandits. We show that in the general realizable, piecewise-stationary setting with $L$ stationary segments, the optimal regret is $Θ(L\log T)$ as long as $L\geq 2$. This stands in sharp contrast to the case of $L=1$ (i.e., the stationary setting), where a $T$-independent $Θ(1)$ satisficing regret is achievable under realizability. In other words, the optimal regret has to scale with $T$ even if just a little nonstationarity presents. A key ingredient in our analysis is a novel Fano-based framework tailored to nonstationary bandits via a \emph{post-interaction reference} construction. This framework strictly extends the classical Fano method for passive estimation as well as recent interactive Fano techniques for stationary bandits. As a complement, we also discuss a special regime in which constant satisficing regret is again possible.
AC-MASAC: An Attentive Curriculum Learning Framework for Heterogeneous UAV Swarm Coordination
Feb 12, 2026Cooperative path planning for heterogeneous UAV swarms poses significant challenges for Multi-Agent Reinforcement Learning (MARL), particularly in handling asymmetric inter-agent dependencies and addressing the risks of sparse rewards and catastrophic forgetting during training. To address these issues, this paper proposes an attentive curriculum learning framework (AC-MASAC). The framework introduces a role-aware heterogeneous attention mechanism to explicitly model asymmetric dependencies. Moreover, a structured curriculum strategy is designed, integrating hierarchical knowledge transfer and stage-proportional experience replay to address the issues of sparse rewards and catastrophic forgetting. The proposed framework is validated on a custom multi-agent simulation platform, and the results show that our method has significant advantages over other advanced methods in terms of Success Rate, Formation Keeping Rate, and Success-weighted Mission Time. The code is available at \textcolor{red}{https://github.com/Wanhao-Liu/AC-MASAC}.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Information-Theoretic Multi-Model Fusion for Target-Oriented Adaptive Sampling in Materials Design
Feb 03, 2026Target-oriented discovery under limited evaluation budgets requires making reliable progress in high-dimensional, heterogeneous design spaces where each new measurement is costly, whether experimental or high-fidelity simulation. We present an information-theoretic framework for target-oriented adaptive sampling that reframes optimization as trajectory discovery: instead of approximating the full response surface, the method maintains and refines a low-entropy information state that concentrates search on target-relevant directions. The approach couples data, model beliefs, and physics/structure priors through dimension-aware information budgeting, adaptive bootstrapped distillation over a heterogeneous surrogate reservoir, and structure-aware candidate manifold analysis with Kalman-inspired multi-model fusion to balance consensus-driven exploitation and disagreement-driven exploration. Evaluated under a single unified protocol without dataset-specific tuning, the framework improves sample efficiency and reliability across 14 single- and multi-objective materials design tasks spanning candidate pools from $600$ to $4 \times 10^6$ and feature dimensions from $10$ to $10^3$, typically reaching top-performing regions within 100 evaluations. Complementary 20-dimensional synthetic benchmarks (Ackley, Rastrigin, Schwefel) further demonstrate robustness to rugged and multimodal landscapes.
Thinker: A vision-language foundation model for embodied intelligence
Jan 29, 2026When large vision-language models are applied to the field of robotics, they encounter problems that are simple for humans yet error-prone for models. Such issues include confusion between third-person and first-person perspectives and a tendency to overlook information in video endings during temporal reasoning. To address these challenges, we propose Thinker, a large vision-language foundation model designed for embodied intelligence. We tackle the aforementioned issues from two perspectives. Firstly, we construct a large-scale dataset tailored for robotic perception and reasoning, encompassing ego-view videos, visual grounding, spatial understanding, and chain-of-thought data. Secondly, we introduce a simple yet effective approach that substantially enhances the model's capacity for video comprehension by jointly incorporating key frames and full video sequences as inputs. Our model achieves state-of-the-art results on two of the most commonly used benchmark datasets in the field of task planning.
Wasserstein-p Central Limit Theorem Rates: From Local Dependence to Markov Chains
Jan 13, 2026Finite-time central limit theorem (CLT) rates play a central role in modern machine learning (ML). In this paper, we study CLT rates for multivariate dependent data in Wasserstein-$p$ ($\mathcal W_p$) distance, for general $p\ge 1$. We focus on two fundamental dependence structures that commonly arise in ML: locally dependent sequences and geometrically ergodic Markov chains. In both settings, we establish the \textit{first optimal} $\mathcal O(n^{-1/2})$ rate in $\mathcal W_1$, as well as the first $\mathcal W_p$ ($p\ge 2$) CLT rates under mild moment assumptions, substantially improving the best previously known bounds in these dependent-data regimes. As an application of our optimal $\mathcal W_1$ rate for locally dependent sequences, we further obtain the first optimal $\mathcal W_1$--CLT rate for multivariate $U$-statistics. On the technical side, we derive a tractable auxiliary bound for $\mathcal W_1$ Gaussian approximation errors that is well suited to studying dependent data. For Markov chains, we further prove that the regeneration time of the split chain associated with a geometrically ergodic chain has a geometric tail without assuming strong aperiodicity or other restrictive conditions. These tools may be of independent interests and enable our optimal $\mathcal W_1$ rates and underpin our $\mathcal W_p$ ($p\ge 2$) results.
FreqDINO: Frequency-Guided Adaptation for Generalized Boundary-Aware Ultrasound Image Segmentation
Dec 12, 2025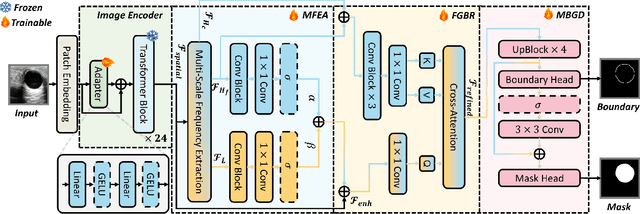
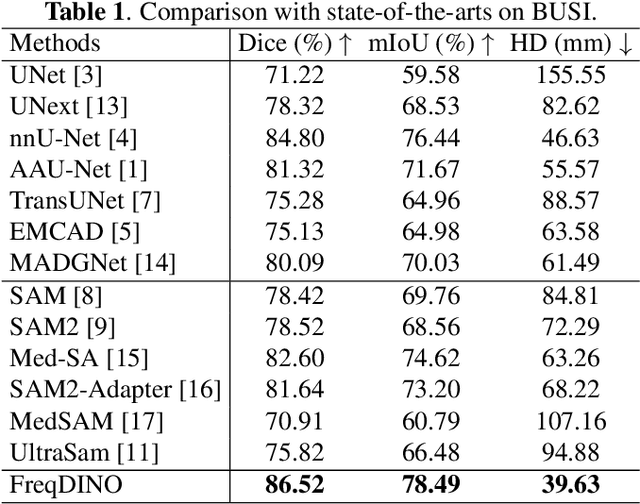
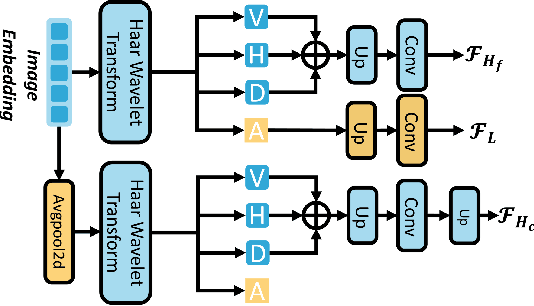
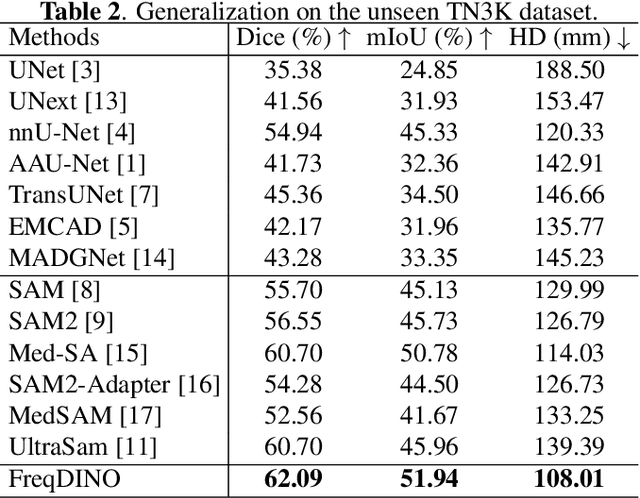
Ultrasound image segmentation is pivotal for clinical diagnosis, yet challenged by speckle noise and imaging artifacts. Recently, DINOv3 has shown remarkable promise in medical image segmentation with its powerful representation capabilities. However, DINOv3, pre-trained on natural images, lacks sensitivity to ultrasound-specific boundary degradation. To address this limitation, we propose FreqDINO, a frequency-guided segmentation framework that enhances boundary perception and structural consistency. Specifically, we devise a Multi-scale Frequency Extraction and Alignment (MFEA) strategy to separate low-frequency structures and multi-scale high-frequency boundary details, and align them via learnable attention. We also introduce a Frequency-Guided Boundary Refinement (FGBR) module that extracts boundary prototypes from high-frequency components and refines spatial features. Furthermore, we design a Multi-task Boundary-Guided Decoder (MBGD) to ensure spatial coherence between boundary and semantic predictions. Extensive experiments demonstrate that FreqDINO surpasses state-of-the-art methods with superior achieves remarkable generalization capability. The code is at https://github.com/MingLang-FD/FreqDINO.
Fair Bayesian Data Selection via Generalized Discrepancy Measures
Nov 10, 2025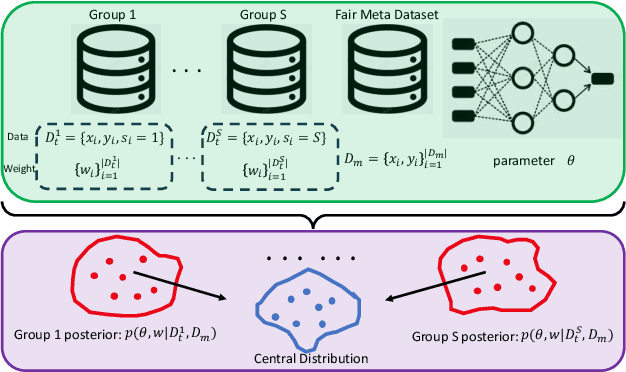
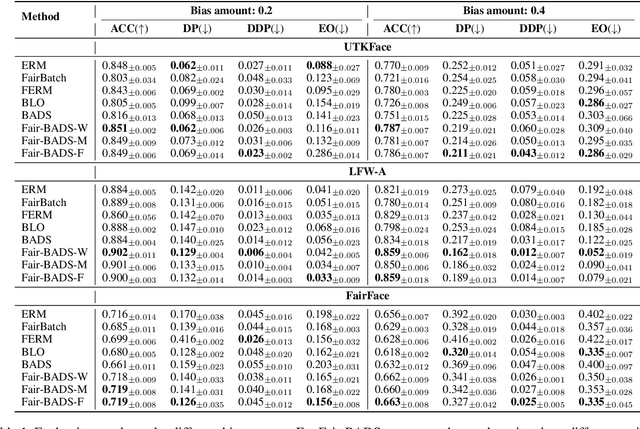

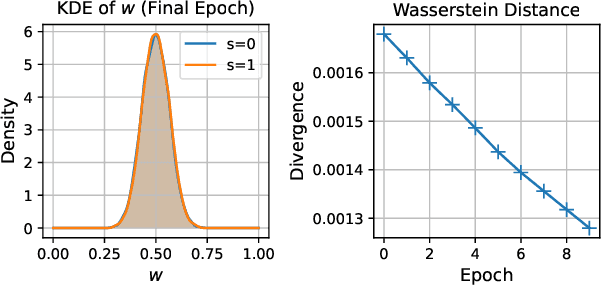
Fairness concerns are increasingly critical as machine learning models are deployed in high-stakes applications. While existing fairness-aware methods typically intervene at the model level, they often suffer from high computational costs, limited scalability, and poor generalization. To address these challenges, we propose a Bayesian data selection framework that ensures fairness by aligning group-specific posterior distributions of model parameters and sample weights with a shared central distribution. Our framework supports flexible alignment via various distributional discrepancy measures, including Wasserstein distance, maximum mean discrepancy, and $f$-divergence, allowing geometry-aware control without imposing explicit fairness constraints. This data-centric approach mitigates group-specific biases in training data and improves fairness in downstream tasks, with theoretical guarantees. Experiments on benchmark datasets show that our method consistently outperforms existing data selection and model-based fairness methods in both fairness and accuracy.
Medverse: A Universal Model for Full-Resolution 3D Medical Image Segmentation, Transformation and Enhancement
Sep 11, 2025In-context learning (ICL) offers a promising paradigm for universal medical image analysis, enabling models to perform diverse image processing tasks without retraining. However, current ICL models for medical imaging remain limited in two critical aspects: they cannot simultaneously achieve high-fidelity predictions and global anatomical understanding, and there is no unified model trained across diverse medical imaging tasks (e.g., segmentation and enhancement) and anatomical regions. As a result, the full potential of ICL in medical imaging remains underexplored. Thus, we present \textbf{Medverse}, a universal ICL model for 3D medical imaging, trained on 22 datasets covering diverse tasks in universal image segmentation, transformation, and enhancement across multiple organs, imaging modalities, and clinical centers. Medverse employs a next-scale autoregressive in-context learning framework that progressively refines predictions from coarse to fine, generating consistent, full-resolution volumetric outputs and enabling multi-scale anatomical awareness. We further propose a blockwise cross-attention module that facilitates long-range interactions between context and target inputs while preserving computational efficiency through spatial sparsity. Medverse is extensively evaluated on a broad collection of held-out datasets covering previously unseen clinical centers, organs, species, and imaging modalities. Results demonstrate that Medverse substantially outperforms existing ICL baselines and establishes a novel paradigm for in-context learning. Code and model weights will be made publicly available. Our model are publicly available at https://github.com/jiesihu/Medverse.
Towards Hallucination-Free Music: A Reinforcement Learning Preference Optimization Framework for Reliable Song Generation
Aug 07, 2025Recent advances in audio-based generative language models have accelerated AI-driven lyric-to-song generation. However, these models frequently suffer from content hallucination, producing outputs misaligned with the input lyrics and undermining musical coherence. Current supervised fine-tuning (SFT) approaches, limited by passive label-fitting, exhibit constrained self-improvement and poor hallucination mitigation. To address this core challenge, we propose a novel reinforcement learning (RL) framework leveraging preference optimization for hallucination control. Our key contributions include: (1) Developing a robust hallucination preference dataset constructed via phoneme error rate (PER) computation and rule-based filtering to capture alignment with human expectations; (2) Implementing and evaluating three distinct preference optimization strategies within the RL framework: Direct Preference Optimization (DPO), Proximal Policy Optimization (PPO), and Group Relative Policy Optimization (GRPO). DPO operates off-policy to enhance positive token likelihood, achieving a significant 7.4% PER reduction. PPO and GRPO employ an on-policy approach, training a PER-based reward model to iteratively optimize sequences via reward maximization and KL-regularization, yielding PER reductions of 4.9% and 4.7%, respectively. Comprehensive objective and subjective evaluations confirm that our methods effectively suppress hallucinations while preserving musical quality. Crucially, this work presents a systematic, RL-based solution to hallucination control in lyric-to-song generation. The framework's transferability also unlocks potential for music style adherence and musicality enhancement, opening new avenues for future generative song research.