 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSED-SFT: Selectively Encouraging Diversity in Supervised Fine-Tuning
Feb 07, 2026Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL) has emerged as the standard post-training paradigm for large language models (LLMs). However, the conventional SFT process, driven by Cross-Entropy (CE) loss, often induces mode collapse, where models over-concentrate on specific response patterns. This lack of distributional diversity severely restricts the exploration efficiency required for subsequent RL. While recent studies have attempted to improve SFT by replacing the CE loss, aiming to preserve diversity or refine the update policy, they fail to adequately balance diversity and accuracy, thereby yielding suboptimal performance after RL. To address the mode collapse problem, we propose SED-SFT, which adaptively encourages diversity based on the token exploration space. This framework introduces a selective entropy regularization term with a selective masking mechanism into the optimization objective. Extensive experiments across eight mathematical benchmarks demonstrate that SED-SFT significantly enhances generation diversity with a negligible computational overhead increase compared with CE loss, yielding average improvements of 2.06 and 1.20 points in subsequent RL performance over standard CE-based baselines on Llama-3.2-3B-Instruct and Qwen2.5-Math-7B-Instruct, respectively. The code is publicly available at https://github.com/pppa2019/SED-SFT
Machine Learning Enabled Graph Analysis of Particulate Composites: Application to Solid-state Battery Cathodes
Dec 18, 2025Particulate composites underpin many solid-state chemical and electrochemical systems, where microstructural features such as multiphase boundaries and inter-particle connections strongly influence system performance. Advances in X-ray microscopy enable capturing large-scale, multimodal images of these complex microstructures with an unprecedentedly high throughput. However, harnessing these datasets to discover new physical insights and guide microstructure optimization remains a major challenge. Here, we develop a machine learning (ML) enabled framework that enables automated transformation of experimental multimodal X-ray images of multiphase particulate composites into scalable, topology-aware graphs for extracting physical insights and establishing local microstructure-property relationships at both the particle and network level. Using the multiphase particulate cathode of solid-state lithium batteries as an example, our ML-enabled graph analysis corroborates the critical role of triple phase junctions and concurrent ion/electron conduction channels in realizing desirable local electrochemical activity. Our work establishes graph-based microstructure representation as a powerful paradigm for bridging multimodal experimental imaging and functional understanding, and facilitating microstructure-aware data-driven materials design in a broad range of particulate composites.
Mapping the Trust Terrain: LLMs in Software Engineering -- Insights and Perspectives
Mar 18, 2025



Applications of Large Language Models (LLMs) are rapidly growing in industry and academia for various software engineering (SE) tasks. As these models become more integral to critical processes, ensuring their reliability and trustworthiness becomes essential. Consequently, the concept of trust in these systems is becoming increasingly critical. Well-calibrated trust is important, as excessive trust can lead to security vulnerabilities, and risks, while insufficient trust can hinder innovation. However, the landscape of trust-related concepts in LLMs in SE is relatively unclear, with concepts such as trust, distrust, and trustworthiness lacking clear conceptualizations in the SE community. To bring clarity to the current research status and identify opportunities for future work, we conducted a comprehensive review of $88$ papers: a systematic literature review of $18$ papers focused on LLMs in SE, complemented by an analysis of 70 papers from broader trust literature. Additionally, we conducted a survey study with 25 domain experts to gain insights into practitioners' understanding of trust and identify gaps between existing literature and developers' perceptions. The result of our analysis serves as a roadmap that covers trust-related concepts in LLMs in SE and highlights areas for future exploration.
Warmup-Distill: Bridge the Distribution Mismatch between Teacher and Student before Knowledge Distillation
Feb 17, 2025The widespread deployment of Large Language Models (LLMs) is hindered by the high computational demands, making knowledge distillation (KD) crucial for developing compact smaller ones. However, the conventional KD methods endure the distribution mismatch issue between the teacher and student models, leading to the poor performance of distillation. For instance, the widely-used KL-based methods suffer the mode-averaging and mode-collapsing problems, since the mismatched probabitliy distribution between both models. Previous studies mainly optimize this issue via different distance calculations towards the distribution of both models. Unfortunately, the distribution mismatch issue still exists in the early stage of the distillation. Hence, to reduce the impact of distribution mismatch, we propose a simple yet efficient method, named Warmup-Distill, which aligns the distillation of the student to that of the teacher in advance of distillation. Specifically, we first detect the distribution of the student model in practical scenarios with its internal knowledge, and then modify the knowledge with low probability via the teacher as the checker. Consequently, Warmup-Distill aligns the internal student's knowledge to that of the teacher, which expands the distribution of the student with the teacher's, and assists the student model to learn better in the subsequent distillation. Experiments on the seven benchmarks demonstrate that Warmup-Distill could provide a warmup student more suitable for distillation, which outperforms the vanilla student by as least +0.4 averaged score among all benchmarks. Noteably, with the assistance of Warmup-Distill, the distillation on the math task could yield a further improvement, at most +1.9% accuracy.
Beyond Binary Gender: Evaluating Gender-Inclusive Machine Translation with Ambiguous Attitude Words
Jul 23, 2024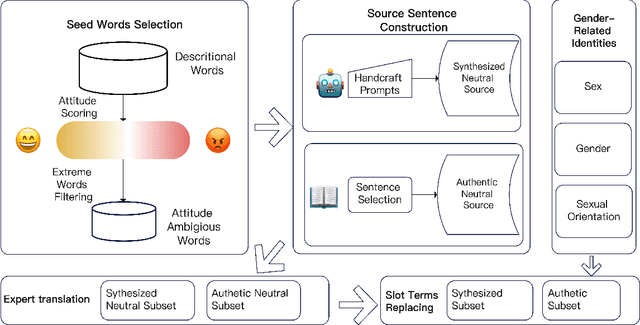

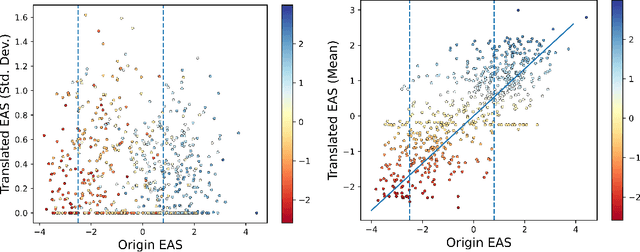

Gender bias has been a focal point in the study of bias in machine translation and language models. Existing machine translation gender bias evaluations are primarily focused on male and female genders, limiting the scope of the evaluation. To assess gender bias accurately, these studies often rely on calculating the accuracy of gender pronouns or the masculine and feminine attributes of grammatical gender via the stereotypes triggered by occupations or sentiment words ({\em i.e.}, clear positive or negative attitude), which cannot extend to non-binary groups. This study presents a benchmark AmbGIMT (Gender-Inclusive Machine Translation with Ambiguous attitude words), which assesses gender bias beyond binary gender. Meanwhile, we propose a novel process to evaluate gender bias based on the Emotional Attitude Score (EAS), which is used to quantify ambiguous attitude words. In evaluating three recent and effective open-source LLMs and one powerful multilingual translation-specific model, our main observations are: (1) The translation performance within non-binary gender contexts is markedly inferior in terms of translation quality and exhibits more negative attitudes than binary-gender contexts. (2) The analysis experiments indicate that incorporating constraint context in prompts for gender identity terms can substantially reduce translation bias, while the bias remains evident despite the presence of the constraints. The code is publicly available at \url{https://github.com/pppa2019/ambGIMT}.
LCS: A Language Converter Strategy for Zero-Shot Neural Machine Translation
Jun 06, 2024
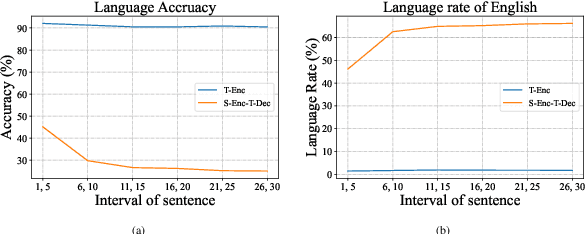
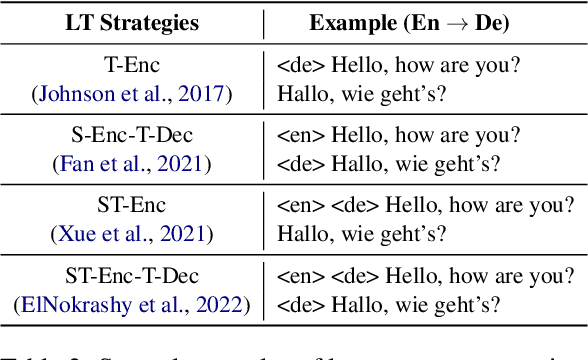
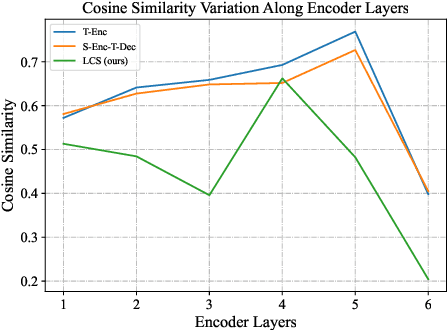
Multilingual neural machine translation models generally distinguish translation directions by the language tag (LT) in front of the source or target sentences. However, current LT strategies cannot indicate the desired target language as expected on zero-shot translation, i.e., the off-target issue. Our analysis reveals that the indication of the target language is sensitive to the placement of the target LT. For example, when placing the target LT on the decoder side, the indication would rapidly degrade along with decoding steps, while placing the target LT on the encoder side would lead to copying or paraphrasing the source input. To address the above issues, we propose a simple yet effective strategy named Language Converter Strategy (LCS). By introducing the target language embedding into the top encoder layers, LCS mitigates confusion in the encoder and ensures stable language indication for the decoder. Experimental results on MultiUN, TED, and OPUS-100 datasets demonstrate that LCS could significantly mitigate the off-target issue, with language accuracy up to 95.28%, 96.21%, and 85.35% meanwhile outperforming the vanilla LT strategy by 3.07, 3,3, and 7.93 BLEU scores on zero-shot translation, respectively.
Outdated Issue Aware Decoding for Factual Knowledge Editing
Jun 06, 2024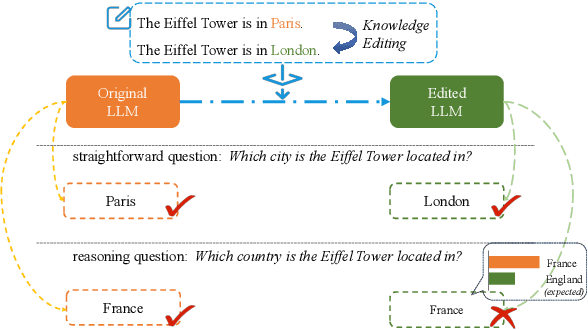
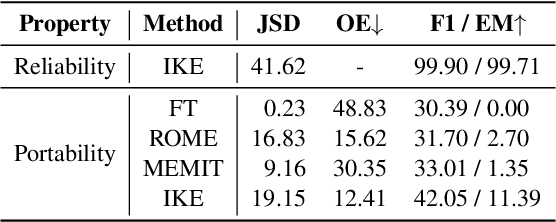
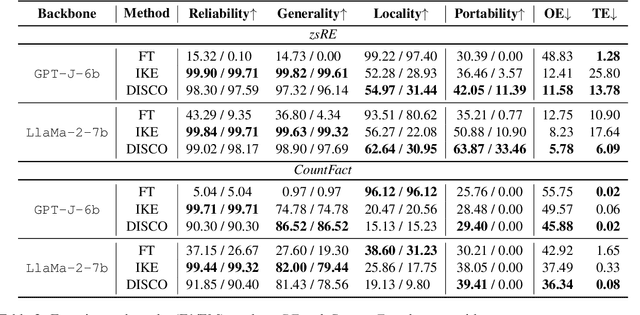
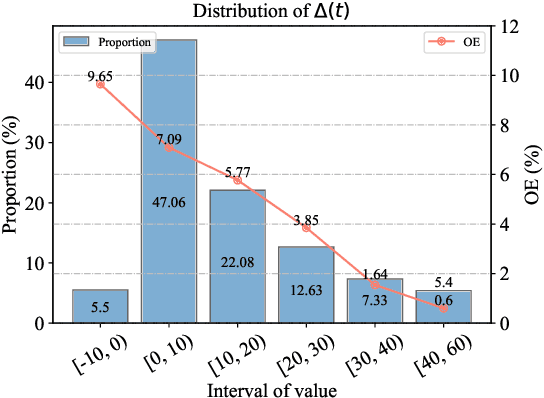
Recently, Knowledge Editing has received increasing attention, since it could update the specific knowledge from outdated ones in pretrained models without re-training. However, as pointed out by recent studies, existing related methods tend to merely memorize the superficial word composition of the edited knowledge, rather than truly learning and absorbing it. Consequently, on the reasoning questions, we discover that existing methods struggle to utilize the edited knowledge to reason the new answer, and tend to retain outdated responses, which are generated by the original models utilizing original knowledge. Nevertheless, the outdated responses are unexpected for the correct answers to reasoning questions, which we named as the outdated issue. To alleviate this issue, in this paper, we propose a simple yet effective decoding strategy, i.e., outDated ISsue aware deCOding (DISCO), to enhance the performance of edited models on reasoning questions. Specifically, we capture the difference in the probability distribution between the original and edited models. Further, we amplify the difference of the token prediction in the edited model to alleviate the outdated issue, and thus enhance the model performance w.r.t the edited knowledge. Experimental results suggest that applying DISCO could enhance edited models to reason, e.g., on reasoning questions, DISCO outperforms the prior SOTA method by 12.99 F1 scores, and reduces the ratio of the outdated issue to 5.78% on the zsRE dataset.
Language Generation with Strictly Proper Scoring Rules
May 29, 2024Language generation based on maximum likelihood estimation (MLE) has become the fundamental approach for text generation. Maximum likelihood estimation is typically performed by minimizing the log-likelihood loss, also known as the logarithmic score in statistical decision theory. The logarithmic score is strictly proper in the sense that it encourages honest forecasts, where the expected score is maximized only when the model reports true probabilities. Although many strictly proper scoring rules exist, the logarithmic score is the only local scoring rule among them that depends exclusively on the probability of the observed sample, making it capable of handling the exponentially large sample space of natural text. In this work, we propose a straightforward strategy for adapting scoring rules to language generation, allowing for language modeling with any non-local scoring rules. Leveraging this strategy, we train language generation models using two classic strictly proper scoring rules, the Brier score and the Spherical score, as alternatives to the logarithmic score. Experimental results indicate that simply substituting the loss function, without adjusting other hyperparameters, can yield substantial improvements in model's generation capabilities. Moreover, these improvements can scale up to large language models (LLMs) such as LLaMA-7B and LLaMA-13B. Source code: \url{https://github.com/shaochenze/ScoringRulesLM}.
Comments as Natural Logic Pivots: Improve Code Generation via Comment Perspective
Apr 11, 2024Code generation aims to understand the problem description and generate corresponding code snippets, where existing works generally decompose such complex tasks into intermediate steps by prompting strategies, such as Chain-of-Thought and its variants. While these studies have achieved some success, their effectiveness is highly dependent on the capabilities of advanced Large Language Models (LLMs) such as GPT-4, particularly in terms of API calls, which significantly limits their practical applicability. Consequently, how to enhance the code generation capabilities of small and medium-scale code LLMs without significantly increasing training costs is an appealing challenge. In this paper, we suggest that code comments are the natural logic pivot between natural language and code language and propose using comments to boost the code generation ability of code LLMs. Concretely, we propose MANGO (comMents As Natural loGic pivOts), including a comment contrastive training strategy and a corresponding logical comment decoding strategy. Experiments are performed on HumanEval and MBPP, utilizing StarCoder and WizardCoder as backbone models, and encompassing model parameter sizes between 3B and 7B. The results indicate that MANGO significantly improves the code pass rate based on the strong baselines. Meanwhile, the robustness of the logical comment decoding strategy is notably higher than the Chain-of-thoughts prompting. The code is publicly available at \url{https://github.com/pppa2019/Mango}.
Accelerating Inference in Large Language Models with a Unified Layer Skipping Strategy
Apr 10, 2024Recently, dynamic computation methods have shown notable acceleration for Large Language Models (LLMs) by skipping several layers of computations through elaborate heuristics or additional predictors. However, in the decoding process of existing approaches, different samples are assigned different computational budgets, which cannot guarantee a stable and precise acceleration effect. Furthermore, existing approaches generally skip multiple contiguous layers at the bottom or top of the layers, leading to a drastic change in the model's layer-wise representations, and thus a consequent performance degeneration. Therefore, we propose a Unified Layer Skipping strategy, which selects the number of layers to skip computation based solely on the target speedup ratio, and then skips the corresponding number of intermediate layer computations in a balanced manner. Since the Unified Layer Skipping strategy is independent of input samples, it naturally supports popular acceleration techniques such as batch decoding and KV caching, thus demonstrating more practicality for real-world applications. Experimental results on two common tasks, i.e., machine translation and text summarization, indicate that given a target speedup ratio, the Unified Layer Skipping strategy significantly enhances both the inference performance and the actual model throughput over existing dynamic approaches.